Dữ liệu mở của blockchain sẽ không có giá trị nếu người dùng không thể truy cập và hiểu được. Đối với người mới tham gia tiền điện tử, họ thường chỉ quan tâm đến giá token – điều này khá đơn giản. Tuy nhiên, khi dần có thêm kinh nghiệm trong lĩnh vực blockchain, họ sẽ nhận ra rằng muốn thực sự hiểu thị trường thì cần đến dữ liệu cấp pool cho DeFi, dữ liệu duy trì người dùng cho GameFi và nhiều chỉ số khác – như TVL, thông tin ví và số liệu nạp/rút.
Vậy nếu bạn muốn điều tra hoạt động của cá voi giữa các dự án khác nhau thì sao? Hoặc muốn có cái nhìn toàn diện về tác động của một cuộc khủng hoảng truyền thông đối với một giao thức? Làm sao để lấy được loại dữ liệu này và làm thế nào để tạo ra giải pháp tùy chỉnh trả lời các câu hỏi đặc biệt cụ thể?
Việc lấy dữ liệu thô, chưa qua xử lý từ một blockchain duy nhất thực ra không quá phức tạp về mặt kỹ thuật. Đó là lý do vì sao hiện có hàng chục dịch vụ trong lĩnh vực phân tích blockchain. Quy trình này về bản chất là tổ chức lại dữ liệu – chuẩn hóa hàng triệu dòng dữ liệu được đưa vào cơ sở dữ liệu, đặc biệt khi các blockchain có cách triển khai kỹ thuật rất khác nhau. Nhờ lập trình giao diện người dùng khéo léo, dữ liệu sẽ được chuyển thành dạng trực quan, dễ hiểu.
Không khó để cho phép người dùng thêm các chỉ số từ các dự án khác nhau vào một biểu đồ để so sánh. Dune Analytics yêu cầu dùng SQL cho thao tác này. Một số nền tảng khác như Nansen cũng cung cấp biểu đồ tùy chỉnh nhưng ở quy mô hạn chế hơn nhiều. Nhưng nếu muốn so sánh dữ liệu từ các blockchain khác nhau thì sao? Đây là lúc mọi thứ trở nên phức tạp. Tại Footprint, chúng tôi đã phát triển một mô hình tổng hợp dữ liệu thô này và lập chỉ mục để dữ liệu trở nên có ý nghĩa.
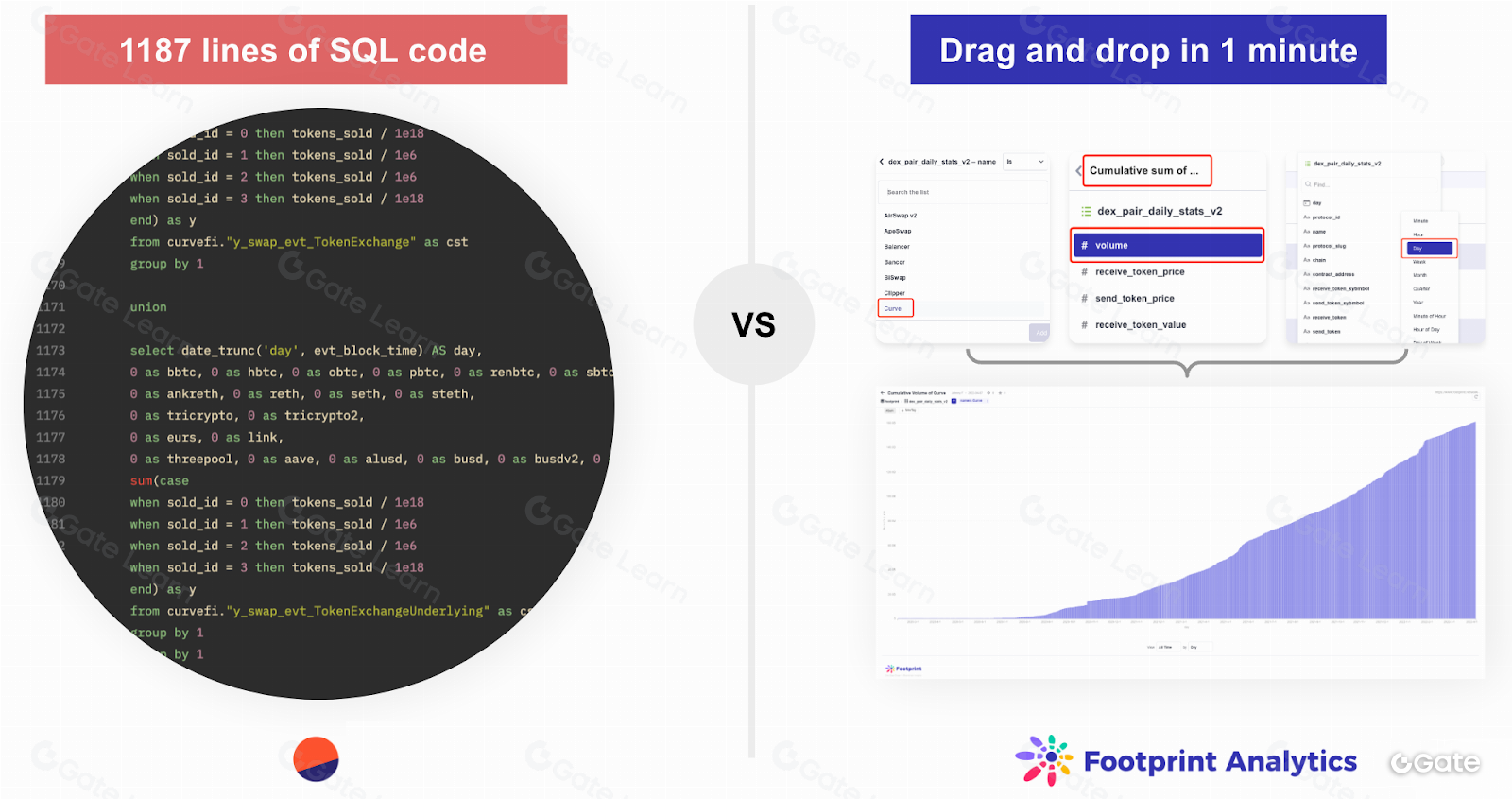
Thông tin về hàng triệu giao dịch này được phân chia theo lĩnh vực – công cụ dữ liệu của chúng tôi xác định xem chúng có thể được phân loại là GameFi, NFT, DEX hay lĩnh vực khác. Chúng tôi giải mã dữ liệu này để các nhà phân tích có thể tìm kiếm thông tin như thời gian khối, TVL, giá token,... và hiển thị dữ liệu đó ngay lập tức trên biểu đồ.
Thay vì các chuỗi số và ký tự mà đa số người dùng không thể hiểu, bạn sẽ có địa chỉ ví, blockchain, bộ sưu tập NFT và những danh mục có ý nghĩa khác.
Ngược lại, những nhà phân tích giàu kinh nghiệm muốn linh hoạt hơn vẫn có thể làm việc với dữ liệu thô bằng SQL hoặc Python.
Xây dựng một công cụ dữ liệu toàn diện nhất trong ngành (hiện tại chúng tôi hỗ trợ 22 blockchain) đồng thời giữ vững hiệu suất hàng đầu là một thành tựu kỹ thuật không nhỏ.
Bài viết sau đây sẽ giải thích chi tiết về thiết kế dữ liệu của chúng tôi.
Vấn đề của phân tích dữ liệu đa chuỗi
Bạn không thể so sánh táo với cam.
Làm sao có thể so sánh độ dày vỏ của táo Golden Delicious với số hạt trong quả cam Cara Cara? Rõ ràng là không hợp lý, nhưng mọi thứ sẽ có ý nghĩa khi bạn so sánh độ ngọt, kích thước, độ cứng, mức tiêu thụ toàn cầu – những yếu tố có thể định lượng cho cả hai loại quả một cách logic.
Cách phân loại hợp lý này giống như dữ liệu ngữ nghĩa có cấu trúc. Dù mã để mint NFT trên Solana hay Ethereum có khác nhau ra sao, vẫn cần đưa tất cả dữ liệu này vào cùng một danh mục, gọi là “Minting”.
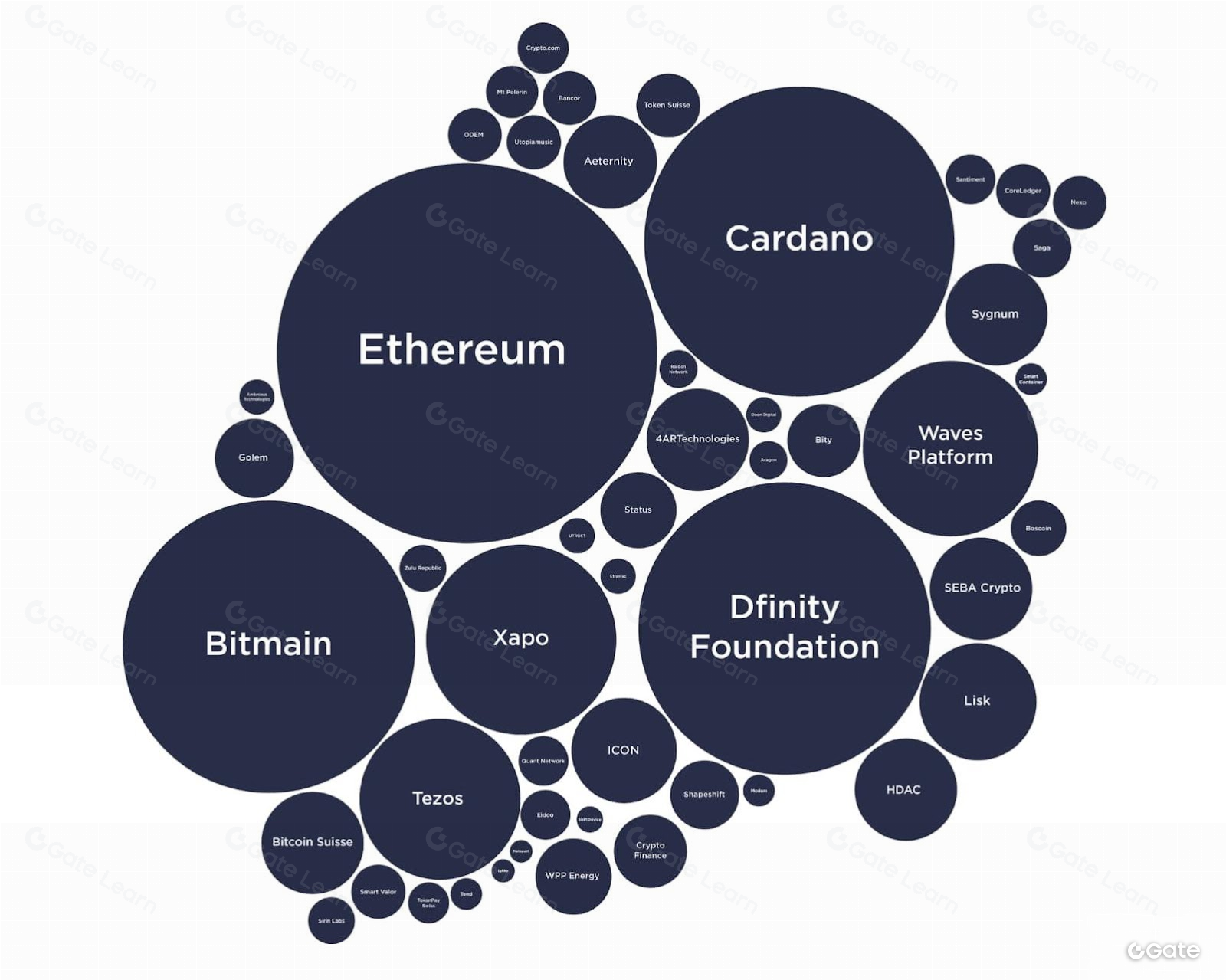
Hầu hết các giải pháp phân tích blockchain lớn đều cho phép bạn so sánh táo với cam. Nhưng với Footprint Analytics, chúng tôi có thể so sánh táo với cam, kiwi, dứa và còn nhiều hơn thế.
Tính đến tháng 12, chúng tôi phân tích dữ liệu từ 22 blockchain khác nhau, nhiều hơn bất kỳ nền tảng nào khác. Cơ sở dữ liệu Footprint Analytics tự động lấy khối, log, trace và giao dịch trên blockchain. Chúng tôi còn bổ sung dữ liệu do cộng đồng đóng góp và dữ liệu từ API bên thứ ba (ví dụ: dữ liệu giá token từ Coingecko). Tất cả dữ liệu này ban đầu đều thô và chưa có cấu trúc. Chúng tôi tổ chức lại để đưa vào các danh mục như vay, cho vay, yield farming,... Nhờ vậy, bất kỳ dữ liệu nào trên blockchain cũng dễ dàng truy cập với mọi người.
Footprint Analytics cân bằng giữa tính linh hoạt và sự đơn giản như thế nào
Ứng dụng web Footprint được xây dựng trên nền tảng mã nguồn mở Metabase. Tìm hiểu thêm về Metabase. Chúng tôi sử dụng Metabase vì tính mở – công nghệ này cho phép người dùng đóng góp vào mã nguồn, phát triển và cải tiến theo thời gian.
Ví dụ, trong bản cập nhật mới nhất của Metabase, các mô hình đã được giới thiệu. Chức năng này cho phép người dùng chọn lọc dữ liệu từ một hoặc nhiều bảng trong cùng một cơ sở dữ liệu để dự đoán các loại câu hỏi mà người dùng sẽ đặt ra đối với dữ liệu.
Các nhà phân tích có thể tạo biểu đồ trên nền tảng Footprint Analytics với công cụ xây dựng truy vấn dạng kéo và thả tiện lợi. Khả năng này giúp giảm đáng kể rào cản tiếp cận, cho phép bất kỳ người dùng nào không có kiến thức kỹ thuật cũng có thể sử dụng sản phẩm và khai thác giá trị kinh doanh.
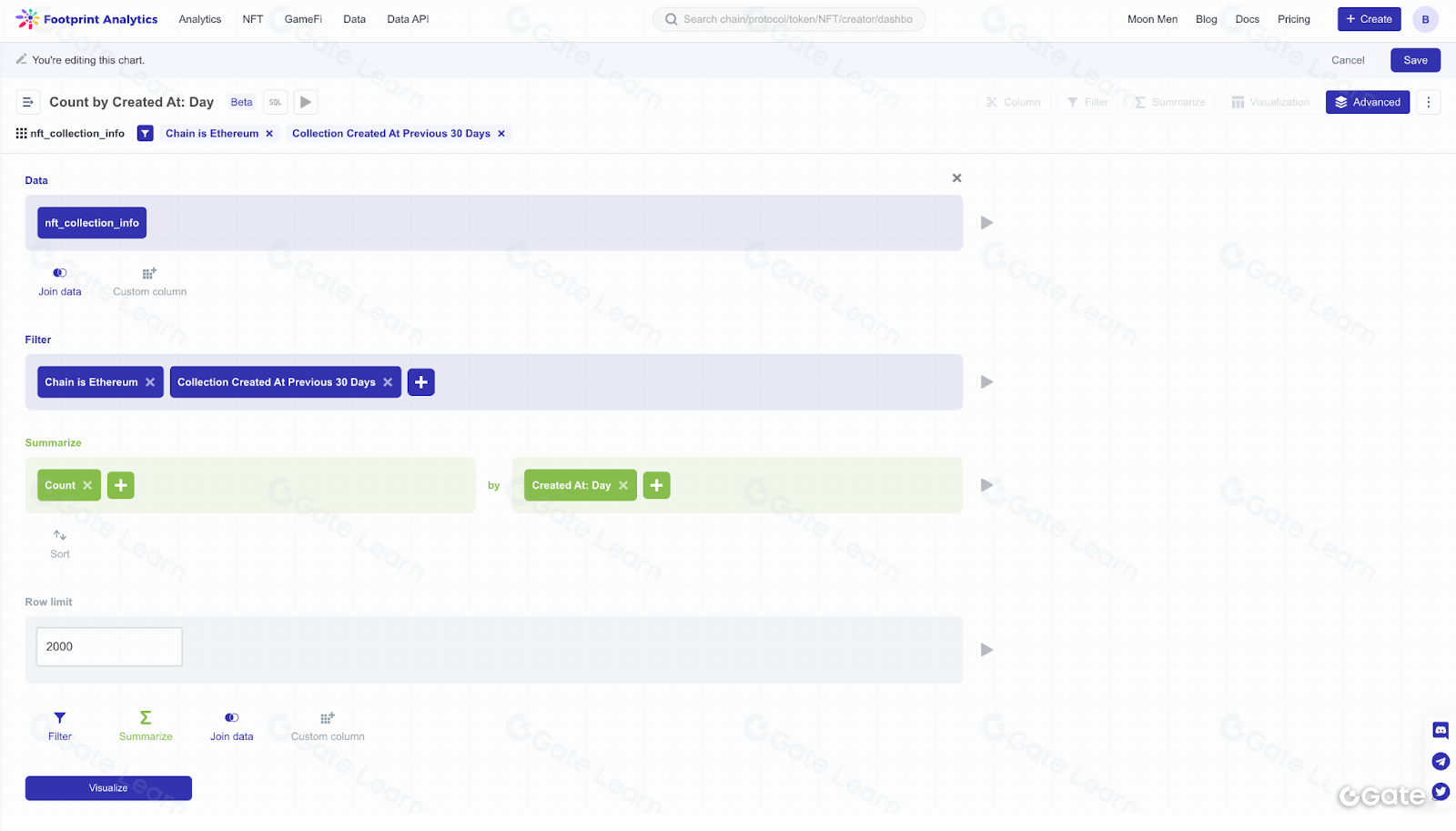
Cần lưu ý rằng, về mặt kiến trúc, Metabase là một lớp trừu tượng trên mã SQL; tức là mọi truy vấn được tạo ra bằng thao tác kéo thả đều có thể biểu diễn dưới dạng SQL. Vì vậy, người dùng muốn xây dựng truy vấn phức tạp hơn hoặc thích làm việc với dữ liệu bằng mã đều có thể sử dụng SQL ngay lập tức.
Nhiều giải pháp phân tích khác cho phép người dùng phân tích các mạng khác nhau theo nhiều mức độ yêu cầu. Tuy nhiên, phần lớn các giải pháp này thường đi đến cực đoan: hoặc rất linh hoạt, đòi hỏi kiến thức về ngôn ngữ truy vấn hoặc lập trình, hoặc là giao diện cực kỳ đơn giản với các kịch bản dựng sẵn và do đó, tính linh hoạt thấp.
Phạm vi
Chúng tôi có một trong những phạm vi bao phủ rộng nhất trên thị trường. Chúng tôi sẽ mô tả chi tiết phạm vi hiện tại, liên quan đến cách tổ chức dữ liệu (các cấp, lĩnh vực) trong phần tiếp theo.
Footprint Analytics phân tích được nhiều dữ liệu như vậy bằng cách nào?
Lợi thế cạnh tranh cốt lõi của chúng tôi là Nền tảng Footprint Analytics, được vận hành bởi Footprint Machine Learning Platform.
“Nền tảng Footprint Analytics” có thể chỉ website mà người dùng truy cập tại footprint.network. Tuy nhiên, khi nhắc đến Footprint Analytics Platform, chúng tôi còn nói đến bộ máy xử lý dữ liệu phía sau.
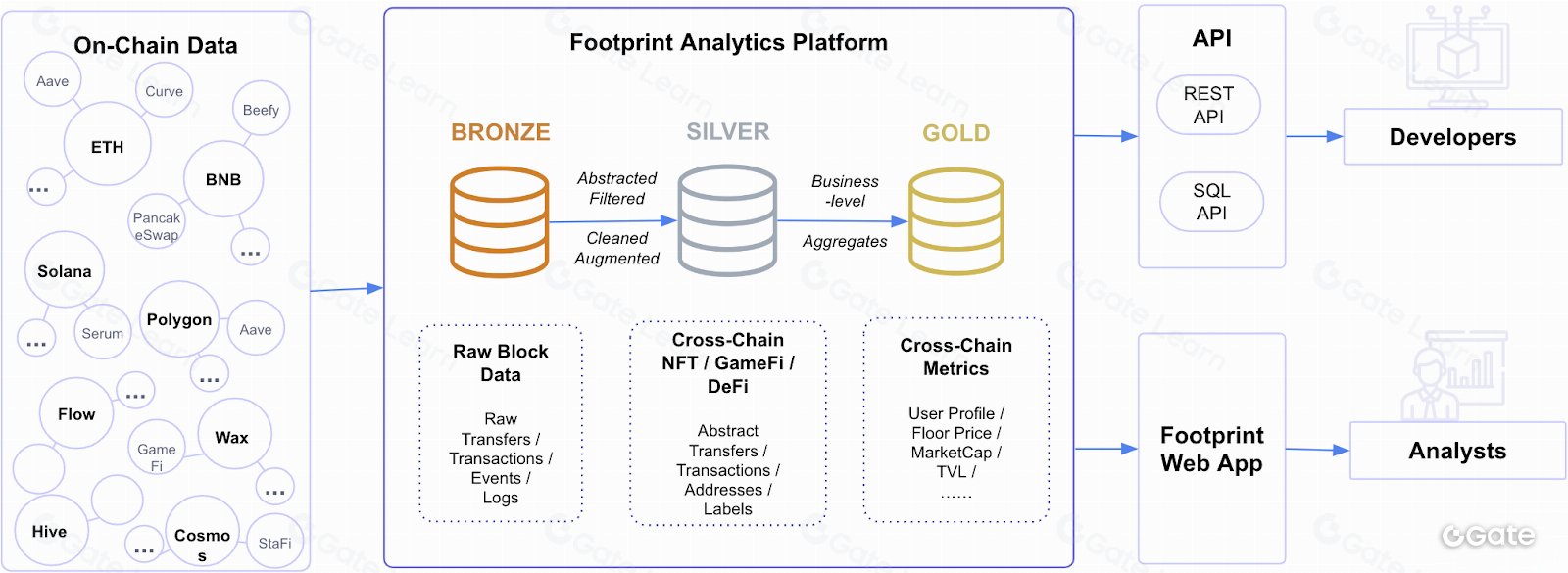
Các cấp độ
Chúng tôi chuyển đổi Dữ liệu Bronze thành Silver, rồi thành Gold bằng các phương pháp ETL như Python và SQL. Trong tương lai, chúng tôi dự định sẽ mở mã nguồn cho phần mã ETL, bao gồm cả mã chuyển từ Bronze sang Silver.
Chúng tôi cũng cho phép bất kỳ tổ chức nào truy cập kho dữ liệu có cấu trúc này thông qua API dữ liệu blockchain của mình.
Sở hữu dữ liệu blockchain phong phú nhất thế giới với Footprint Data API
Giao diện người dùng không phải là cách duy nhất để truy cập dữ liệu. Tất cả các giao diện được hỗ trợ hiện tại đều được liệt kê tại đây: Interfaces
Trước khi có Footprint Analytics, việc phân tích blockchain bị giới hạn bởi dữ liệu không đầy đủ và chưa có cấu trúc. Hơn nữa, các tổ chức sử dụng các giải pháp hàng đầu vẫn gặp phải tình trạng truy cập chậm, hiệu suất hạn chế và chi phí tổng hợp API cao.
Nhờ nền tảng của chúng tôi phân tích dữ liệu on-chain từ 23 blockchain thành các cấp Silver và Gold như đã đề cập, bất cứ tổ chức nào cũng có thể tiếp cận phần lớn dữ liệu GameFi, NFT và DeFi trên thế giới chỉ với một API duy nhất. Cả REST API và SQL API đều được hỗ trợ tại Footprint Analytics.
Có thể xây dựng những ứng dụng nào với loại dữ liệu này? Dưới đây là một số ví dụ:
- Theo dõi tỷ lệ duy trì người chơi tốt nhất và tệ nhất trên mọi tựa GameFi
- Kích hoạt cảnh báo khi ví cá voi đưa tiền vào hoặc rút tiền khỏi các blockchain hoặc giao thức quan tâm
- So sánh biến động TVL giữa các chuỗi với giá hàng hóa
- Tạo giao diện tùy chỉnh cho bộ sưu tập NFT từ nhiều mạng lưới
- Khám phá các bộ sưu tập hot mới nhất và truy cập phân tích chuyên sâu cho hơn 15.000 dự án
- Theo dõi dòng tiền của cá voi để xác định cơ hội đầu tư và rủi ro tiềm ẩn
Với Footprint, bất kỳ ai cũng có thể tiếp cận gần hơn với phân tích blockchain, dù bạn là nhà đầu tư, nhà phân tích, nhà giao dịch cá nhân, nhà phát triển hay chỉ đơn giản là đang khám phá dự án tiền điện tử yêu thích.






