Gate Ventures Forschungsinsights: Der dritte Browserkrieg: Die Eintrittsschlacht im Zeitalter der KI-Agenten
TL;DR
Der dritte Browserkrieg entfaltet sich still und leise. Wenn man auf die Geschichte zurückblickt, von Netscape und Microsofts Internet Explorer in den 1990er Jahren bis hin zum Open-Source-Firefox und Googles Chrome, war der Browserkrieg immer eine konzentrierte Manifestation von Plattformkontrolle und technologischen Paradigmenwechseln. Chrome hat seine dominant Position dank seiner schnellen Updategeschwindigkeit und des integrierten Ökosystems gesichert, während Google durch sein Such- und Browser-Duopol einen geschlossenen Informationszugangskreislauf gebildet hat.
Aber heute wackelt diese Landschaft. Der Aufstieg großer Sprachmodelle (LLMs) ermöglicht es immer mehr Nutzern, Aufgaben zu erledigen, ohne auf die Suchergebnisseite zu klicken, während die traditionellen Webseitenklicks zurückgehen. In der Zwischenzeit bedrohen Gerüchte, dass Apple beabsichtigt, die Standard-Suchmaschine in Safari zu ersetzen, die Gewinnbasis von Alphabet (Muttergesellschaft von Google) weiter, und der Markt beginnt, Unbehagen über die "Orthodoxie der Suche" auszudrücken.
Der Browser selbst steht ebenfalls vor einer Neugestaltung seiner Rolle. Er ist nicht nur ein Werkzeug zum Anzeigen von Webseiten, sondern auch ein Container für multiple Fähigkeiten, einschließlich Dateneingabe, Benutzerverhalten und privater Identität. Während KI-Agenten leistungsstark sind, sind sie weiterhin auf die Vertrauensgrenze und die funktionale Sandbox des Browsers angewiesen, um komplexe Seiteninteraktionen abzuschließen, auf lokale Identitätsdaten zuzugreifen und Webseitenelemente zu steuern. Browser entwickeln sich von menschlichen Schnittstellen zu Systemaufrufplattformen für Agenten.
In diesem Artikel untersuchen wir, ob Browser noch notwendig sind. Wir glauben, dass das, was die aktuelle Browsermarktlandschaft wirklich stören könnte, nicht ein weiterer "besserer Chrome" ist, sondern eine neue Interaktionsstruktur: nicht nur Informationsanzeige, sondern Aufgabenaufruf. Zukünftige Browser müssen für KI-Agenten entworfen werden – die nicht nur lesen, sondern auch schreiben und ausführen können. Projekte wie Browser Use versuchen, die Seitenstruktur zu semantisieren, visuelle Schnittstellen in strukturierte Texte umzuwandeln, die von LLM aufrufbar sind, Seiten mit Befehlen zu verknüpfen und die Interaktionskosten erheblich zu senken.
Große Projekte testen bereits das Wasser: Perplexity baut einen nativen Browser, Comet, der traditionelle Suchergebnisse durch KI ersetzt; Brave kombiniert Datenschutz mit lokalem Denken und nutzt LLM, um die Such- und Blockierungsfähigkeiten zu verbessern; und krypto-native Projekte wie Donut zielen darauf ab, neue Einstiegspunkte für KI zu schaffen, um mit On-Chain-Assets zu interagieren. Ein gemeinsames Merkmal dieser Projekte ist ihr Versuch, die Eingabeschicht des Browsers umzugestalten, anstatt die Ausgabeschicht zu verschönern.
Für Unternehmer liegen die Chancen im Dreieck von Eingabe, Struktur und Agentenzugang. Als Schnittstelle für die zukünftige agentenbasierte Welt bedeutet der Browser, dass jeder, der strukturierte, aufrufbare und vertrauenswürdige "Fähigkeiten" bereitstellen kann, zu einer Komponente der nächsten Plattformgeneration wird. Von SEO bis AEO (Agent Engine Optimization), von Seitenverkehr bis zur Invocation von Aufgabenketten wird die Produktform und das Designdenken neu gestaltet. Der dritte Browserkrieg findet über "Eingabe" und nicht über "Anzeige" statt. Der Sieg wird nicht mehr dadurch bestimmt, wer die Aufmerksamkeit des Nutzers gewinnt, sondern wer das Vertrauen des Agenten erwirbt und Zugang erhält.
Eine kurze Geschichte der Browser-Entwicklung
In den frühen 1990er Jahren, bevor das Internet Teil des täglichen Lebens wurde, trat Netscape Navigator auf die Bühne, wie ein Segelboot, das Millionen von Nutzern die Tür zur digitalen Welt öffnete. Obwohl es nicht der erste Browser war, war es der erste, der tatsächlich die Massen erreichte und das Internet-Erlebnis prägte. Zum ersten Mal konnten Menschen mit solcher Leichtigkeit über eine grafische Benutzeroberfläche im Web surfen, als ob die gesamte Welt plötzlich zugänglich geworden wäre.
Allerdings ist Ruhm oft kurzlebig. Microsoft erkannte schnell die Bedeutung von Browsern und beschloss, Internet Explorer gewaltsam in das Windows-Betriebssystem zu integrieren und ihn zum Standardbrowser zu machen. Diese Strategie, ein echter "Plattform-Killer", untergrub direkt die Marktbeherrschung von Netscape. Viele Benutzer wählten IE nicht aktiv; vielmehr akzeptierten sie es einfach als den Standard. Durch die Vertriebsmöglichkeiten von Windows wurde IE schnell zum Branchenführer, während Netscape in den Rückgang fiel.

Inmitten von Widrigkeiten wählten die Ingenieure von Netscape einen radikalen und idealistischen Weg – sie öffneten den Quellcode des Browsers und riefen die Open-Source-Community auf. Diese Entscheidung war wie eine „Mazedonische Abdankung“ in der Tech-Welt, die das Ende einer alten Ära und den Aufstieg neuer Kräfte signalisierte. Dieser Code wurde später zur Grundlage des Mozilla-Browserprojekts, das zunächst Phoenix (symbolisiert Wiedergeburt) genannt wurde, aber nach mehreren Markenstreitigkeiten schließlich in Firefox umbenannt wurde.
Firefox war nicht nur ein bloßer Abklatsch von Netscape. Es machte Durchbrüche in der Benutzererfahrung, den Plugin-Ökosystemen und der Sicherheit. Seine Geburt markierte den Sieg des Open-Source-Geistes und injizierte frische Vitalität in die gesamte Branche. Einige beschrieben Firefox als den "spirituellen Nachfolger" von Netscape, ähnlich wie das Osmanische Reich den schwindenden Ruhm von Byzanz erbte. Obwohl übertrieben, ist der Vergleich bedeutungsvoll.
Doch bevor Firefox offiziell veröffentlicht wurde, hatte Microsoft bereits sechs Versionen des Internet Explorers herausgebracht. Durch die Nutzung seines frühen Zeitpunkts und der Strategie des Systembundlings wurde Firefox von Anfang an in eine Aufholposition versetzt, was sicherstellte, dass dieses Rennen niemals ein gleichwertiger Wettbewerb ab der gleichen Linie war.
Zur gleichen Zeit betrat ein weiterer früher Akteur leise die Bühne. 1994 wurde der Opera-Browser in Norwegen geboren, zunächst nur ein Experimentierprojekt. Aber ab Version 7.0 im Jahr 2003 führte er seine selbstentwickelte Presto-Engine ein, die Unterstützung für CSS, adaptive Layouts, Sprachsteuerung und Unicode-Codierung bahnbrechend machte. Obwohl die Nutzerbasis begrenzt war, führte er technologisch konstant die Branche an und wurde zu einem "Lieblingswerkzeug der Technikbegeisterten."
Im selben Jahr lancierte Apple den Safari-Browser – ein bedeutender Wendepunkt. Zu dieser Zeit hatte Microsoft 150 Millionen Dollar in ein angeschlagenes Apple investiert, um einen Anschein von Wettbewerb aufrechtzuerhalten und Antitrust-Prüfungen zu vermeiden. Obwohl die Standard-Suchmaschine von Safari von Anfang an Google war, symbolisierte dieses Verstrickung mit Microsoft die komplexen und subtilen Beziehungen unter den Internet-Riesen: Kooperation und Wettbewerb, immer miteinander verflochten.
Im Jahr 2007 wurde IE7 zusammen mit Windows Vista veröffentlicht, aber die Marktreaktion war verhalten. Firefox hingegen konnte seinen Marktanteil dank schnellerer Aktualisierungszyklen, einem benutzerfreundlicheren Erweiterungsmechanismus und einer natürlichen Anziehungskraft für Entwickler stetig auf etwa 20% erhöhen. Die Dominanz von IE begann zu schwinden, und die Winde drehten sich.
Google hingegen verfolgte einen anderen Ansatz. Obwohl es seit 2001 an seinem eigenen Browser arbeitete, dauerte es sechs Jahre, um CEO Eric Schmidt von dem Projekt zu überzeugen. Chrome debütierte 2008 und basierte auf dem Open-Source-Projekt Chromium und der von Safari verwendeten WebKit-Engine. Es wurde als „aufgeblähter“ Browser verspottet, aber mit Googles tiefem Fachwissen in Werbung und Markenbildung stieg es schnell auf.
Chromes wichtigste Waffe waren nicht seine Funktionen, sondern der häufige Aktualisierungszyklus (alle sechs Wochen) und das einheitliche plattformübergreifende Erlebnis. Im November 2011 überholte Chrome zum ersten Mal Firefox und erreichte einen Marktanteil von 27 %; sechs Monate später überholte es IE und vollendete seine Transformation vom Herausforderer zum dominierenden Marktführer.
Inzwischen bildete Chinas mobile Internet sein eigenes Ökosystem. Der UC Browser von Alibaba gewann in den frühen 2010er Jahren, insbesondere in aufstrebenden Märkten wie Indien, Indonesien und China, an Beliebtheit. Mit seinem leichten Design und den Datenkomprimierungsfunktionen, die Bandbreite einsparten, gewann er Nutzer auf Geräten der unteren Preisklasse. Bis 2015 überstieg sein globaler Marktanteil für mobile Browser 17 %, und in Indien erreichte er einmal sogar 46 %. Doch dieser Sieg war nicht von langer Dauer. Als die indische Regierung die Sicherheitsüberprüfungen chinesischer Apps verschärfte, war der UC Browser gezwungen, wichtige Märkte zu verlassen und verlor allmählich seinen ehemaligen Glanz.
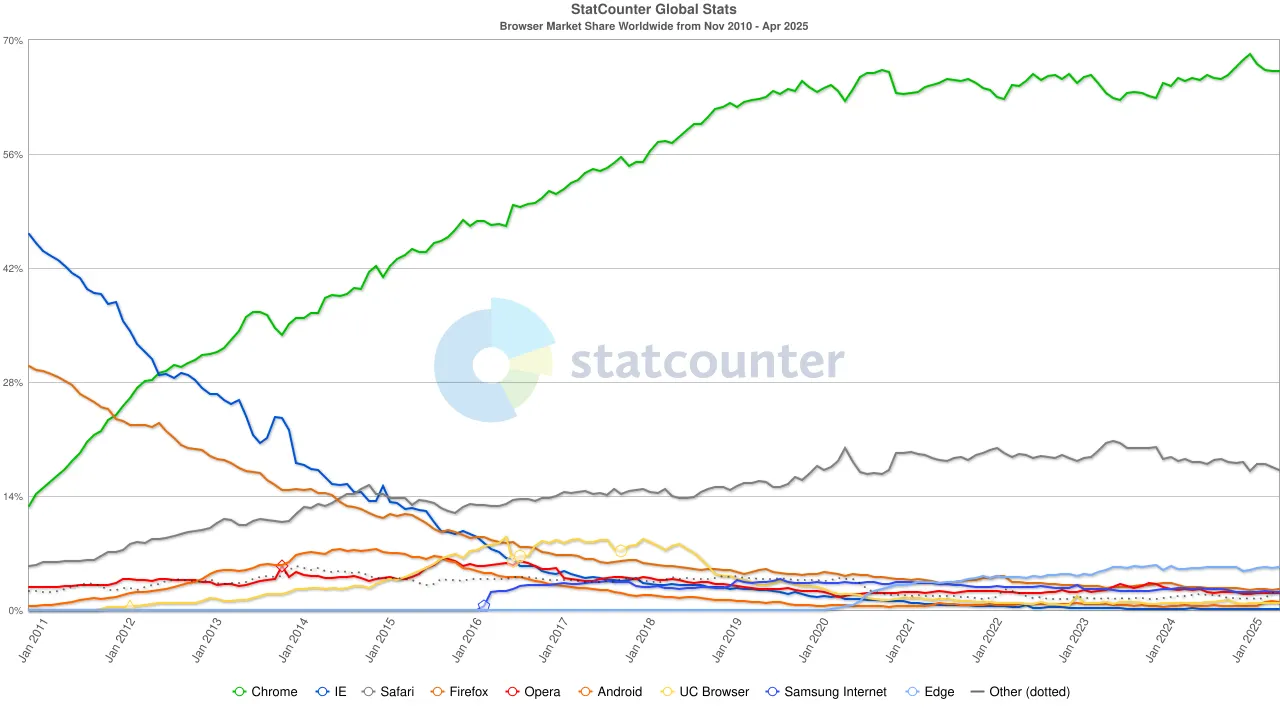
Bis in die 2020er Jahre war die Dominanz von Chrome fest etabliert, wobei sich der globale Marktanteil bei etwa 65 % stabilisierte. Bemerkenswert ist, dass, obwohl die Suchmaschine von Google und der Chrome-Browser beide zu Alphabet gehören, sie aus Marktperspektive zwei unabhängige Hegemonien darstellen – erstere kontrolliert etwa 90 % des globalen Suchverkehrs, und letzterer dient als das "erste Fenster", durch das die meisten Benutzer auf das Internet zugreifen.
Um diese duale Monopolstruktur aufrechtzuerhalten, hat Google keine Kosten gescheut. Im Jahr 2022 zahlte Alphabet Apple etwa 20 Milliarden Dollar, nur um Google als Standardsuchmaschine in Safari zu behalten. Analysten haben darauf hingewiesen, dass diese Ausgabe etwa 36 % der Suchanzeigenumsätze ausmachte, die Google durch den Safari-Verkehr erzielte. Mit anderen Worten, Google zahlte effektiv eine "Schutzgebühr", um seinen Vorteil zu verteidigen.
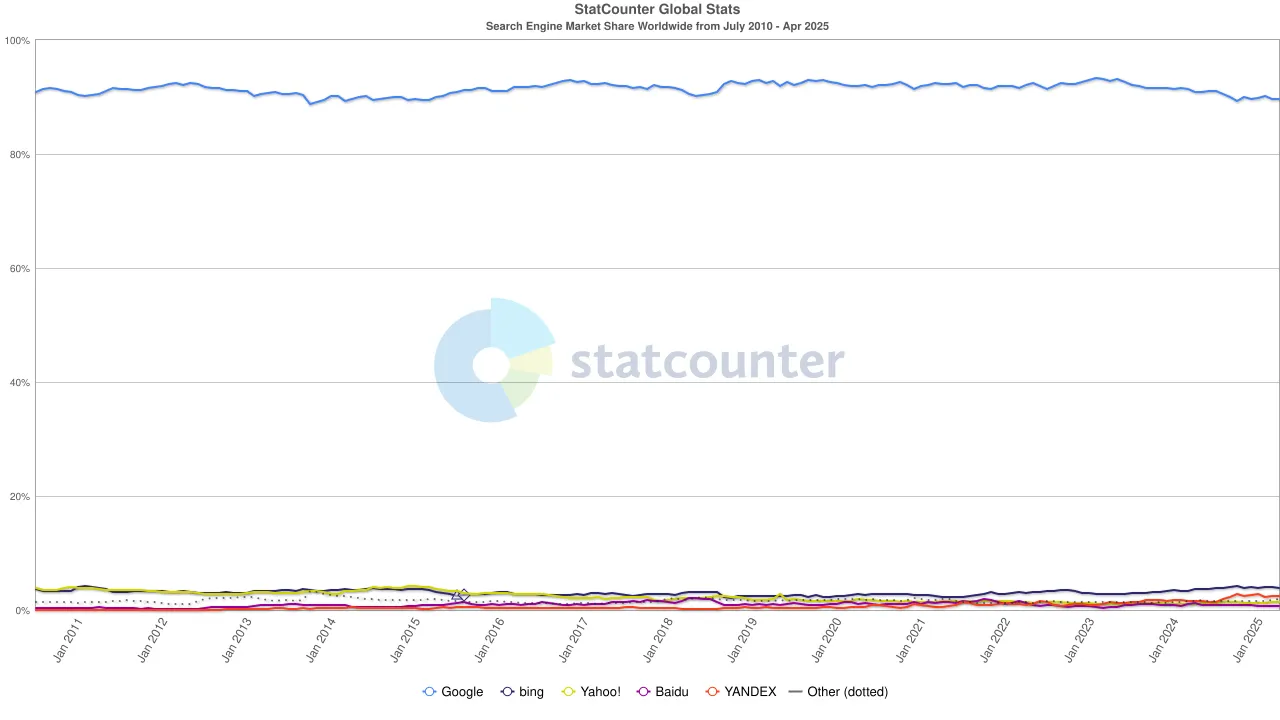
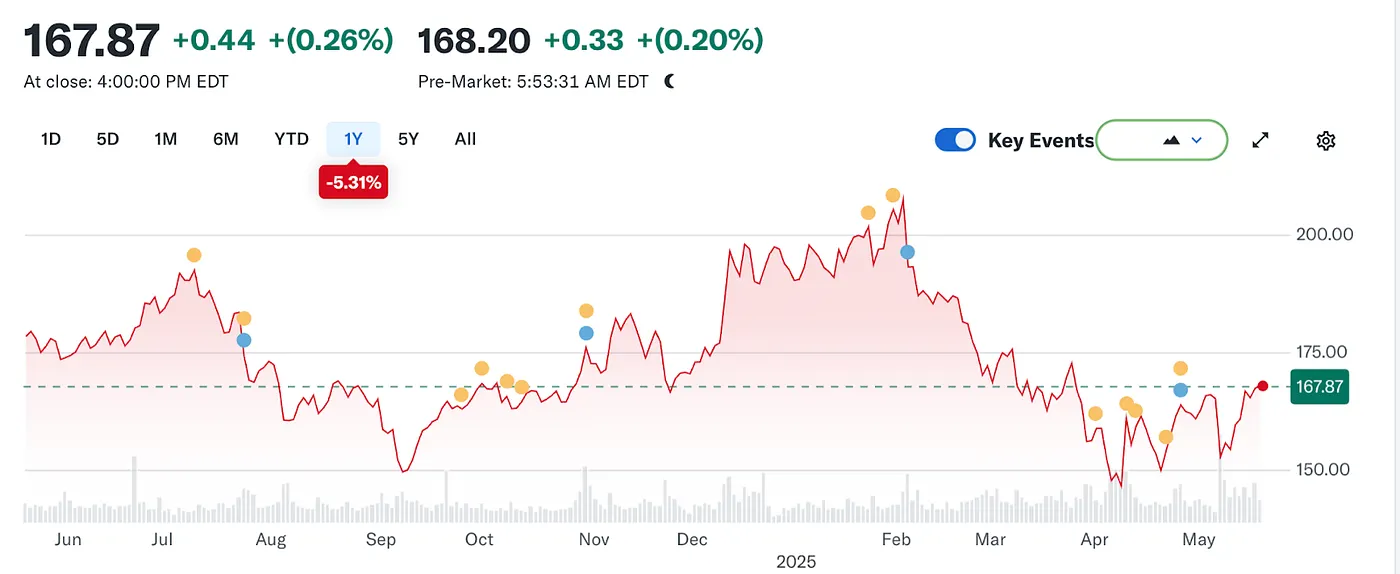
Aber die Tide änderte sich erneut. Mit dem Aufstieg großer Sprachmodelle (LLMs) begann die traditionelle Suche, die Auswirkungen zu spüren. Im Jahr 2024 fiel Googles Anteil am Suchmarkt von 93 % auf 89 %. Obwohl es immer noch dominierte, begannen Risse sichtbar zu werden. Noch disruptiver waren Gerüchte, dass Apple möglicherweise seine eigene KI-gesteuerte Suchmaschine auf den Markt bringen könnte. Wenn die Standard-Suche von Safari auf Apples eigenes Ökosystem umschalten würde, würde dies nicht nur die Wettbewerbslandschaft neu gestalten, sondern könnte auch das Fundament von Alphabets Gewinnen erschüttern. Der Markt reagierte schnell: Der Aktienkurs von Alphabet fiel von 170 $ auf 140 $, was nicht nur die Panik der Investoren widerspiegelte, sondern auch eine tiefgreifende Unruhe über die zukünftige Richtung der Suchära.
Von Navigator zu Chrome, von Open-Source-Idealen zur werbegestützten Kommerzialisierung, von leichten Browsern zu KI-Suchassistenten, der Kampf der Browser war immer ein Krieg um Technologie, Plattformen, Inhalte und Kontrolle. Das Schlachtfeld verschiebt sich ständig, aber das Wesen hat sich nie verändert: Wer das Gateway kontrolliert, definiert die Zukunft.
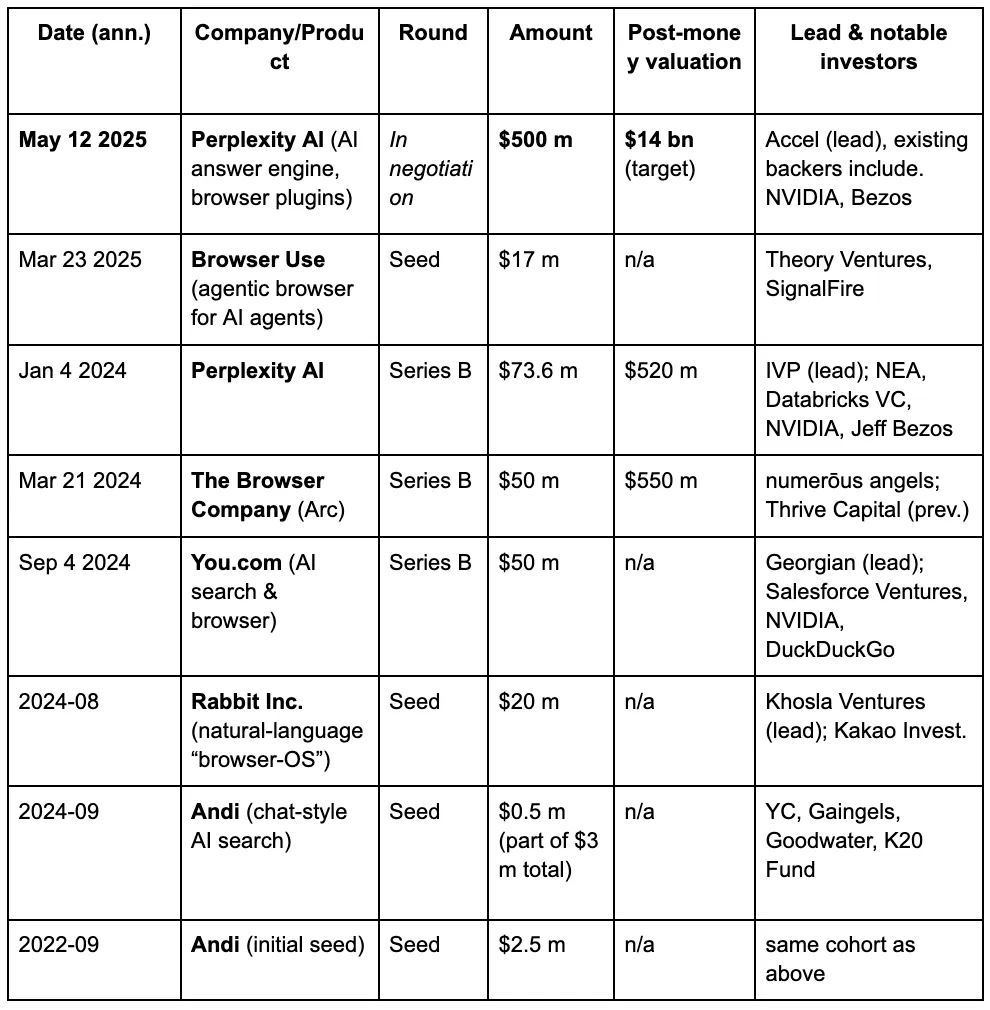
In den Augen der Risikokapitalgeber entfaltet sich allmählich ein dritter Browserkrieg, der durch die neuen Anforderungen, die Menschen an Suchmaschinen im Zeitalter von LLMs und KI stellen, vorangetrieben wird. Im Folgenden sind die Finanzierungsdetails einiger bekannter Projekte im Bereich der KI-Browser aufgeführt.
Die veraltete Architektur moderner Browser
Wenn es um die Architektur von Browsern geht, ist die klassische traditionelle Struktur im folgenden Diagramm dargestellt:
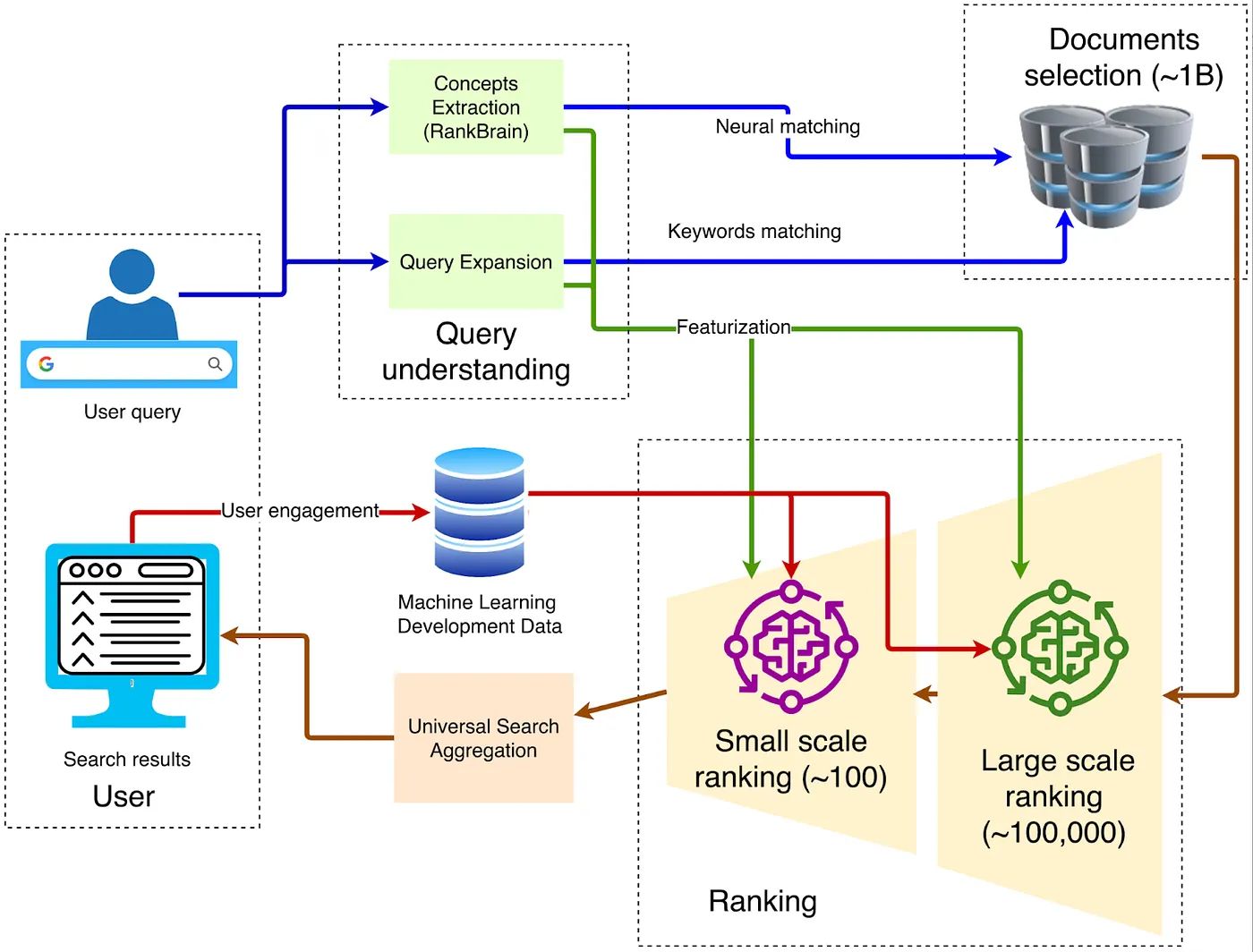
1. Client — Front-End Entry
Die Anfrage wird über HTTPS an das nächstgelegene Google Front End gesendet, wo TLS-Dekodierung, QoS-Sampling und geografische Routenplanung durchgeführt werden. Wenn abnormaler Datenverkehr erkannt wird (wie DDoS-Angriffe oder automatisches Scraping), können in dieser Schicht Ratenbegrenzungen oder Herausforderungen angewendet werden.
2. Abfrageverständnis
Das Frontend muss die Bedeutung der vom Benutzer eingegebenen Wörter verstehen. Dies umfasst drei Schritte:
Neurale Rechtschreibkorrektur, wie das Umwandeln von "recpie" in "recipe".
Synonymerweiterung, zum Beispiel "wie man ein Fahrrad repariert" auf "Fahrrad reparieren" zu erweitern.
Die Intent-Analyse bestimmt, ob die Anfrage informativ, navigational oder transaktional ist, und weist dann die entsprechende vertikale Anfrage zu.
3. Kandidatenabholung
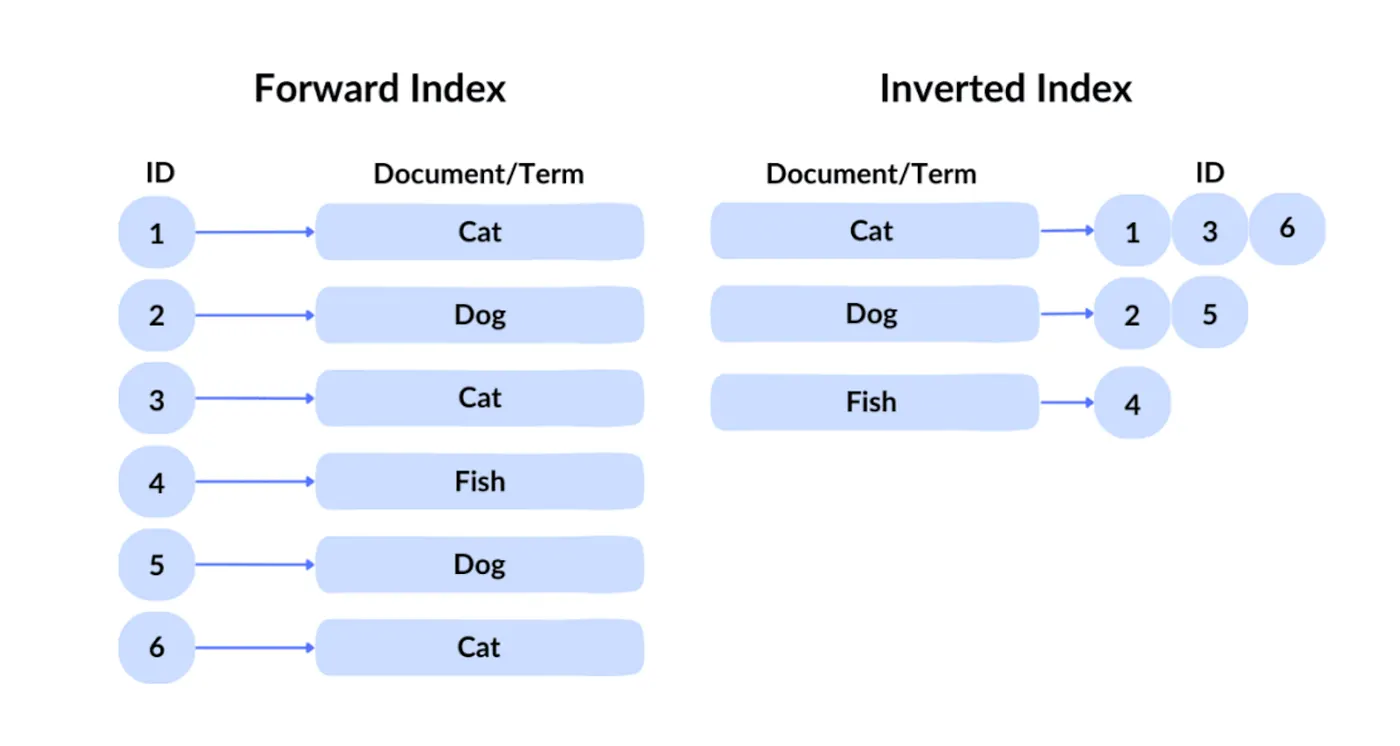
Die Abfragetechnologie von Google ist als invertierter Index bekannt. Bei einem Vorwärtsindex ruft man eine Datei anhand ihrer ID ab. Da die Nutzer jedoch unmöglich die Identifikatoren der gewünschten Inhalte aus Hunderten von Milliarden von Dateien kennen können, verwendet Google den traditionellen invertierten Index, der nach Inhalten abfragt, um zu identifizieren, welche Dateien die entsprechenden Schlüsselwörter enthalten.
Als Nächstes wendet Google die Vektorisierung an, um semantische Suche zu ermöglichen – das heißt, Inhalte zu finden, die in ihrer Bedeutung der Anfrage ähnlich sind. Es konvertiert Text, Bilder und andere Inhalte in hochdimensionale Vektoren (Einbettungen) und sucht dann basierend auf der Ähnlichkeit zwischen diesen Vektoren. Wenn ein Benutzer beispielsweise nach „wie man Pizzateig macht“ sucht, kann die Suchmaschine Ergebnisse zurückgeben, die mit „Anleitung zur Zubereitung von Pizzateig“ zusammenhängen, da die beiden semantisch ähnlich sind.
Durch invertierte Indizierung und Vektorindizierung werden in der ersten Screening-Phase grob Hunderttausende von Webseiten herausgefiltert.
4. Mehrstufige Rangliste
Das System verwendet typischerweise Tausende von leichtgewichtigen Funktionen wie BM25, TF-IDF und Seitenqualitätsbewertungen, um die Hunderttausenden von Kandidatenseiten auf etwa 1.000 zu filtern und ein anfängliches Kandidatenset zu bilden. Solche Systeme werden zusammenfassend als Empfehlungssysteme bezeichnet. Sie basieren auf massiven Merkmalen, die aus verschiedenen Entitäten generiert werden, einschließlich Benutzerverhalten, Seitenattributen, Abfrageabsicht und kontextuellen Signalen. Zum Beispiel kombiniert Google die Benutzerhistorie, Feedback von anderen Benutzern, Seitensemantik und die Bedeutung von Abfragen und berücksichtigt dabei auch kontextuelle Elemente wie Zeit (Tageszeit, Wochentag) und externe Ereignisse wie aktuelle Nachrichten.
5. Deep Learning für das primäre Ranking
In der initialen Abrufphase verwendet Google Technologien wie RankBrain und Neural Matching, um die Semantik von Anfragen zu verstehen und die relevantesten Ergebnisse aus massiven Dokumentensammlungen herauszufiltern.
RankBrain, 2015 von Google eingeführt, ist ein maschinelles Lernsystem, das entwickelt wurde, um die Bedeutung von Benutzeranfragen besser zu verstehen, insbesondere bei Anfragen, die noch nie zuvor gesehen wurden. Es transformiert Anfragen und Dokumente in Vektorrepresentationen und berechnet deren Ähnlichkeit, um die relevantesten Ergebnisse zu finden. Zum Beispiel kann RankBrain bei der Anfrage "wie man Pizzateig macht" sogar dann Inhalte identifizieren, die mit "Pizza-Grundlagen" oder "Teigzubereitung" in Verbindung stehen, selbst wenn kein Dokument eine genaue Übereinstimmung mit dem Schlüsselwort enthält.
Neural Matching, das 2018 eingeführt wurde, wurde entwickelt, um die semantische Beziehung zwischen Anfragen und Dokumenten weiter zu erfassen. Mithilfe von neuronalen Netzwerkmodellen identifiziert es unscharfe Beziehungen zwischen Wörtern, um Anfragen besser mit Webinhalten abzugleichen. Zum Beispiel kann Neural Matching bei der Anfrage „Warum ist mein Laptop-Lüfter so laut“ verstehen, dass der Benutzer möglicherweise nach Informationen zur Fehlersuche bei Überhitzung, Staubansammlung oder hoher CPU-Auslastung sucht – selbst wenn diese Begriffe nicht ausdrücklich in der Anfrage erscheinen.
6. Deep Re-Ranking: Die Anwendung von BERT
Nach der ersten Filterung relevanter Dokumente wendet Google BERT (Bidirectional Encoder Representations from Transformers) an, um das Ranking zu verfeinern und sicherzustellen, dass die relevantesten Ergebnisse an oberster Stelle erscheinen. BERT ist ein vortrainiertes Sprachmodell, das auf Transformers basiert und die kontextuellen Beziehungen von Wörtern innerhalb von Sätzen verstehen kann.
Bei der Suche wird BERT verwendet, um die in früheren Phasen abgerufenen Dokumente neu zu bewerten. Es kodiert Abfragen und Dokumente gemeinsam, berechnet deren Relevanzwerte und sortiert dann die Dokumente neu. Zum Beispiel kann BERT für die Abfrage „Parken auf einem Hügel ohne Bordstein“ die Bedeutung von „ohne Bordstein“ korrekt interpretieren und Ergebnisse zurückgeben, die den Fahrern raten, ihre Räder zur Straße hin zu drehen, anstatt es fälschlicherweise als eine Situation mit einem Bordstein zu interpretieren.
Für SEO-Engineers bedeutet dies, dass sie die Ranking- und maschinellen Lernempfehlungsalgorithmen von Google sorgfältig studieren müssen, um Webinhalte gezielt zu optimieren und somit eine höhere Sichtbarkeit in den Suchrankings zu erlangen.
Warum KI die Browser neu gestalten wird
Zuerst müssen wir klären: Warum muss das Formular als Browser weiterhin existieren? Gibt es ein drittes Paradigma neben KI-Agenten und Browsern?
Wir glauben, dass Existenz Unersetzlichkeit impliziert. Warum kann künstliche Intelligenz Browser nutzen, sie aber nicht vollständig ersetzen? Weil der Browser eine universelle Plattform ist. Er ist nicht nur ein Zugangspunkt zum Lesen von Daten, sondern auch ein allgemeiner Zugangspunkt zum Eingeben von Daten. Die Welt kann nicht nur Informationen konsumieren – sie muss auch Daten produzieren und mit Websites interagieren. Daher werden Browser, die personalisierte Benutzerinformationen integrieren, weiterhin weit verbreitet existieren.
Hier ist der Schlüsselpunkt: Als universelles Gate ist der Browser nicht nur zum Lesen von Daten da; Benutzer müssen oft mit Daten interagieren. Der Browser selbst ist ein hervorragendes Repository zum Speichern von Benutzerfingerabdrücken. Komplexere Benutzerverhalten und automatisierte Aktionen müssen über den Browser durchgeführt werden. Der Browser kann alle Benutzerverhaltensfingerabdrücke, Anmeldeinformationen und andere private Informationen speichern, was eine vertrauenslose Invocation während der Automatisierung ermöglicht. Die Interaktion mit Daten könnte sich zu folgendem Muster entwickeln:
Benutzer → ruft KI-Agent → Browser.
Mit anderen Worten, der einzige Teil, der ersetzt werden könnte, liegt im natürlichen Trend der Welt – hin zu größerer Intelligenz, Personalisierung und Automatisierung. Sicherlich kann dieser Teil von KI-Agenten gehandhabt werden. Aber KI-Agenten selbst sind nicht gut geeignet, um personalisierte Benutzerinhalte zu tragen, da sie mit mehreren Herausforderungen bezüglich Datensicherheit und Benutzerfreundlichkeit konfrontiert sind. Konkret:
Der Browser ist das Repository für personalisierte Inhalte:
Die meisten großen Modelle werden in der Cloud gehostet, wobei die Sitzungs-Kontexte von der Server-Speicherung abhängen, was den direkten Zugriff auf lokale Passwörter, Wallets, Cookies und andere sensible Daten erschwert.
Das Senden aller Browsing- und Zahlungsdaten an Drittanbieter-Modelle erfordert eine erneute Benutzerautorisierung; die DMA der EU und die Datenschutzgesetze auf staatlicher Ebene in den USA verlangen beide eine Datenminimierung über Grenzen hinweg.
Das automatische Ausfüllen von Zwei-Faktor-Authentifizierungscodes, das Aufrufen von Kameras oder die Verwendung von GPUs für WebGPU-Inferenz muss alles innerhalb des Browser-Sandboxes erfolgen.
Der Datenkontext ist stark vom Browser abhängig. Tabs, Cookies, IndexedDB, Service Worker Cache, Passkey-Anmeldeinformationen und Erweiterungsdaten werden alle im Browser gespeichert.
Profound Changes in Interaction Forms
Zurück zum Thema von Anfang an kann unser Verhalten bei der Nutzung von Browsern allgemein in drei Kategorien unterteilt werden: Daten lesen, Daten eingeben und mit Daten interagieren. Große Sprachmodelle (LLMs) haben bereits die Effizienz und Methoden, mit denen wir Daten lesen, tiefgreifend verändert. Die alte Praxis, dass Benutzer Webseiten über Schlüsselwörter suchen, erscheint jetzt veraltet und ineffizient.
Wenn es um die Entwicklung des Suchverhaltens der Nutzer geht – ob das Ziel darin besteht, zusammengefasste Antworten zu erhalten oder auf Webseiten zu klicken – haben viele Studien bereits diese Verschiebung analysiert.
In Bezug auf Benutzerverhaltensmuster zeigte eine Studie aus dem Jahr 2024, dass in den USA von 1.000 Google-Anfragen nur 374 mit einem Klick auf eine offene Webseite endeten. Mit anderen Worten, fast 63 % waren "Zero-Click"-Verhaltensweisen. Benutzer haben sich daran gewöhnt, Informationen wie Wetter, Wechselkurse und Wissenskarten direkt von der Suchergebnisseite zu erhalten.
Was jedoch tatsächlich eine massive Transformation der Browser auslösen könnte, ist die Dateninteraktionsschicht. In der Vergangenheit interagierten die Menschen hauptsächlich mit Browsern, indem sie Schlüsselwörter eingaben – das maximale Verständnisniveau, das der Browser selbst bewältigen konnte. Jetzt ziehen es die Nutzer zunehmend vor, vollständige natürliche Sprache zu verwenden, um komplexe Aufgaben zu beschreiben, wie zum Beispiel:
„Finde mir Direktflüge von New York nach Los Angeles in einem bestimmten Zeitraum.“
„Finde mir einen Flug von New York nach Shanghai und dann nach Los Angeles.“
Selbst für Menschen erfordern solche Aufgaben viel Zeit, um mehrere Websites zu besuchen, Informationen zu sammeln und Ergebnisse zu vergleichen. Aber diese agentischen Aufgaben werden allmählich von KI-Agenten übernommen.
Dies steht auch im Einklang mit der historischen Entwicklung: Automatisierung und Intelligenz. Die Menschen möchten ihre Hände frei haben, und KI-Agenten werden zwangsläufig tief in Browser integriert sein. Zukünftige Browser müssen mit dem Gedanken an vollständige Automatisierung entworfen werden, insbesondere unter Berücksichtigung:
Wie man das Leseerlebnis für Menschen mit der maschinellen Interpretierbarkeit für KI-Agenten in Einklang bringt.
Wie man sicherstellt, dass eine einzelne Webseite sowohl dem Endbenutzer als auch dem Agentenmodell dient.
Nur wenn beide Designanforderungen erfüllt sind, können Browser wirklich stabile Träger für KI-Agenten werden, um Aufgaben auszuführen.
Als Nächstes werden wir uns auf fünf herausragende Projekte konzentrieren – Browser Use, Arc (The Browser Company), Perplexity, Brave und Donut. Diese Projekte repräsentieren zukünftige Richtungen für die Evolution von KI-Browsern sowie ihr Potenzial für eine native Integration in Web3- und Krypto-Kontexte.
Aus der Perspektive der Nutzerpsychologie ergab eine Umfrage aus dem Jahr 2023, dass 44 % der Befragten reguläre organische Ergebnisse vertrauenswürdiger einschätzten als hervorgehobene Snippets. Akademische Forschungen haben ebenfalls herausgefunden, dass Nutzer in Fällen von Kontroversen oder dem Fehlen einer einzigen autoritativen Wahrheit Ergebnisseiten bevorzugen, die Links von mehreren Quellen enthalten.
Mit anderen Worten, während ein Teil der Nutzer den KI-generierten Zusammenfassungen nicht voll vertraut, hat sich ein signifikanter Prozentsatz des Verhaltens bereits auf „Zero-Click“ verschoben. Daher müssen KI-Browser weiterhin das richtige Interaktionsparadigma erkunden – insbesondere im Bereich des Datenlesens. Da das Halluzinationsproblem in großen Modellen noch nicht vollständig gelöst ist, haben viele Nutzer weiterhin Schwierigkeiten, automatisch generierten Inhaltszusammenfassungen vollständig zu vertrauen. In dieser Hinsicht erfordert das Einbetten großer Modelle in Browser nicht unbedingt eine disruptive Transformation. Stattdessen sind einfach inkrementelle Verbesserungen in Genauigkeit und Kontrollierbarkeit erforderlich – ein Prozess, der bereits im Gange ist.
Browser Verwendung
Dies ist genau die Kernlogik hinter der massiven Finanzierung, die Perplexity und Browser Use erhalten haben. Insbesondere hat sich Browser Use als die zweitversprechendste Innovationsmöglichkeit für Anfang 2025 herauskristallisiert, mit sowohl Sicherheit als auch starkem Wachstumspotenzial.

Browser Use hat eine echte semantische Schicht aufgebaut, wobei der Schwerpunkt auf der Schaffung einer semantischen Erkennungsarchitektur für die nächste Generation von Browsern liegt.
Browser Use interpretiert das traditionelle „DOM = ein Knotenbaum für Menschen zu sehen“ um in „Semantic DOM = ein Instruktionsbaum für LLMs zu lesen.“ Dies ermöglicht es Agenten, präzise zu klicken, auszufüllen und hochzuladen, ohne sich auf „Pixelkoordinaten“ zu verlassen. Anstelle von visuellem OCR oder koordinatenbasiertem Selenium verfolgt dieser Ansatz den Weg von „strukturiertem Text → Funktionsaufrufen“, was die Ausführung schneller macht, Token spart und Fehler reduziert. TechCrunch beschrieb es als „die Klebeschicht, die es KI wirklich ermöglicht, Webseiten zu verstehen.“ Im März schloss Browser Use eine Seed-Runde in Höhe von 17 Millionen Dollar und setzt auf diese grundlegende Innovation.
So funktioniert es:
Nachdem HTML gerendert wurde, bildet es einen standardmäßigen DOM-Baum. Der Browser leitet dann einen Zugänglichkeitsbaum ab, der reichhaltigere "Rollen" und "Zustände"-Bezeichnungen für Screenreader bereitstellt.
Jedes interaktive Element (Schaltfläche, Eingabe usw.) wird in einen JSON-Ausschnitt mit Metadaten wie Rolle, Sichtbarkeit, Koordinaten und ausführbaren Aktionen abstrahiert.
Die gesamte Seite wird in eine flache Liste von semantischen Knoten übersetzt, die das LLM in einem einzigen System-Prompt lesen kann.
Die LLM gibt hochrangige Anweisungen aus (zum Beispiel click(node_id="btn-Checkout")), die dann im echten Browser wiedergegeben werden.
Der offizielle Blog beschreibt diesen Prozess als „Umwandlung von Website-Oberflächen in strukturierte Texte, die von LLMs verarbeitet werden können.“
Darüber hinaus könnte, wenn dieser Standard jemals vom W3C angenommen wird, das Problem der Browser-Eingabe erheblich gelöst werden. Als Nächstes werden wir den offenen Brief und die Fallstudien von The Browser Company betrachten, um weiter zu erklären, warum ihr Ansatz fehlerhaft ist.
Bogen
Die Browser Company (das Mutterunternehmen von Arc) erklärte in ihrem offenen Brief, dass der Arc-Browser in den regulären Wartungsmodus übergehen wird, während sich das Team auf die Entwicklung von DIA konzentrieren wird, einem vollständig auf KI ausgerichteten Browser. In dem Brief räumten sie auch ein, dass der spezifische Implementierungsweg für DIA noch nicht festgelegt ist. Gleichzeitig skizzierte das Team mehrere Vorhersagen über die Zukunft des Browsermarktes.
Basierend auf diesen Vorhersagen glauben wir weiter, dass der Schlüssel zur Störung der aktuellen Browserlandschaft darin liegt, die Ausgabeseite der Interaktion zu ändern.
Nachfolgend sind drei der Vorhersagen über den zukünftigen Browsermarkt, die vom Arc-Team geteilt wurden.
https://browsercompany.substack.com/p/letter-to-arc-members-2025
Zunächst glaubt das Arc-Team, dass Webseiten nicht mehr die primäre Schnittstelle für Interaktionen sein werden. Zugegeben, das ist eine gewagte und herausfordernde Behauptung, und es ist auch der Hauptgrund, warum wir skeptisch gegenüber den Überlegungen ihres Gründers bleiben. Aus unserer Sicht unterschätzt diese Perspektive die Rolle des Browsers erheblich und hebt das zentrale Problem hervor, das das Team beim Erkunden des AI-Browser-Wegs übersehen hat.
Große Modelle sind hervorragend darin, Absichten zu erfassen – zum Beispiel Anweisungen wie „hilf mir, einen Flug zu buchen“. Sie sind jedoch unzureichend, wenn es darum geht, Informationsdichte zu transportieren. Wenn ein Benutzer etwas wie ein Dashboard, ein Bloomberg-Terminal-ähnliches Notizbuch oder eine visuelle Leinwand wie Figma benötigt, kann nichts eine fein abgestimmte Webseite mit pixelgenauer Präzision übertreffen. Die Ergonomie jedes Produkts – Diagramme, Drag-and-Drop-Funktionalität, Hotkeys – ist keine oberflächliche Dekoration, sondern wesentliche Merkmale, die die Kognition komprimieren. Diese Fähigkeiten können durch einfache konversationelle Interaktionen nicht reproduziert werden. Am Beispiel von Gate.com: Wenn ein Benutzer eine Investitionsaktion ausführen möchte, reicht es bei Weitem nicht aus, sich ausschließlich auf AI-Gespräche zu verlassen, da die Benutzer stark auf strukturierte Eingaben, Genauigkeit und klare Präsentation von Informationen angewiesen sind.
Das Roadmap-Team von Arc enthält einen grundlegenden Fehler: Es wird nicht klar unterschieden, dass "Interaktion" aus zwei Dimensionen besteht – Eingabe und Ausgabe. Auf der Eingabeseite hat ihre Sichtweise in bestimmten Szenarien eine gewisse Gültigkeit, da KI tatsächlich die Effizienz von befehlsbasierten Interaktionen verbessern kann. Aber auf der Ausgabeseite ist ihre Annahme eindeutig unausgewogen und übersieht die zentrale Rolle des Browsers bei der Informationspräsentation und personalisierten Erfahrungen. Zum Beispiel hat Reddit sein eigenes einzigartiges Layout und Informationsarchitektur, während AAVE eine völlig andere Benutzeroberfläche und Struktur hat. Als Plattform, die gleichzeitig hochprivate Daten speichert und verschiedene Produktoberflächen bereitstellt, hat der Browser auf der Eingabeseite eine begrenzte Substituierbarkeit, während seine Komplexität und nicht standardisierte Natur auf der Ausgabeseite es noch schwieriger machen, ihn zu disruptieren.
Im Gegensatz dazu konzentrieren sich die aktuellen KI-Browser hauptsächlich auf die Schicht der „Ausgabenzusammenfassung“: Seiten zusammenfassen, Informationen extrahieren, Schlussfolgerungen generieren. Das reicht nicht aus, um eine fundamentale Herausforderung für Mainstream-Browser oder Suchsysteme wie Google darzustellen – es verringert lediglich den Marktanteil für Suchzusammenfassungen.
Daher ist die einzige Technologie, die den 66% Marktanteil von Chrome wirklich erschüttern könnte, dazu bestimmt, nicht „das nächste Chrome“ zu sein. Um echte Störungen zu erreichen, muss das Rendering-Modell von Browsern grundlegend umstrukturiert werden, um sich an die Interaktionsbedürfnisse der AI-Agent-Ära anzupassen, insbesondere in Bezug auf das Design der Eingangsarchitektur. Deshalb finden wir den technischen Weg, den Browser Use eingeschlagen hat, weitaus überzeugender – er konzentriert sich auf strukturelle Veränderungen im zugrunde liegenden Mechanismus von Browsern. Sobald ein System ein „atomares“ oder „modulares“ Design erreicht, entfalten die Programmierbarkeit und Komponierbarkeit, die sich daraus ergeben, disruptives Potenzial. Das ist genau die Richtung, die Browser Use heute verfolgt.
Zusammenfassend lässt sich sagen, dass der Betrieb von KI-Agenten nach wie vor stark von der Existenz von Browsern abhängt. Browser sind nicht nur die Hauptspeicher für komplexe personalisierte Daten, sondern auch die universellen Rendering-Schnittstellen für verschiedene Anwendungen und werden daher auch in Zukunft als das zentrale Gate für Interaktionen dienen. Da KI-Agenten tief in Browser integriert werden, um feste Aufgaben zu erfüllen, werden sie hauptsächlich über die Eingabeseite mit Benutzerdaten und spezifischen Anwendungen interagieren. Aus diesem Grund muss das aktuelle Rendering-Modell von Browsern innoviert werden, um maximale Kompatibilität und Anpassungsfähigkeit mit KI-Agenten zu erreichen – letztendlich, um ihnen zu ermöglichen, Anwendungen effektiver zu erfassen.
Verwirrung
Perplexity ist eine KI-Suchmaschine, die für ihr Empfehlungssystem bekannt ist. Ihre neueste Bewertung ist auf 14 Milliarden Dollar gestiegen, fast eine Verfünffachung im Vergleich zu 3 Milliarden Dollar im Juni 2024. Sie bearbeitet jetzt mehr als 400 Millionen Suchanfragen pro Monat. Im September 2024 allein verarbeitete sie rund 250 Millionen Anfragen, was einem achtfachen Anstieg des Suchvolumens der Nutzer im Jahresvergleich entspricht, mit über 30 Millionen monatlich aktiven Nutzern.
Das Hauptmerkmal ist die Fähigkeit, Seiten in Echtzeit zusammenzufassen, was ihm einen starken Vorteil beim Zugriff auf aktuelle Informationen verschafft. Anfang dieses Jahres begann Perplexity mit dem Aufbau seines eigenen nativen Browsers, Comet. Das Unternehmen beschreibt Comet als einen Browser, der nicht nur Webseiten "anzeigt", sondern auch darüber "nachdenkt". Offiziell behaupten sie, dass es die Antwortmaschine von Perplexity tief im Browser selbst einbetten wird, gemäß einem "ganzheitlichen Maschinenansatz", der an Steve Jobs' Philosophie erinnert: KI-Aufgaben tief in das grundlegende Browserebene zu integrieren, anstatt lediglich Sidebar-Plugins zu erstellen.
Mit prägnanten Antworten, die durch Zitationen untermauert sind, zielt Comet darauf ab, die traditionellen "zehn blauen Links" zu ersetzen und direkt mit Chrome zu konkurrieren.
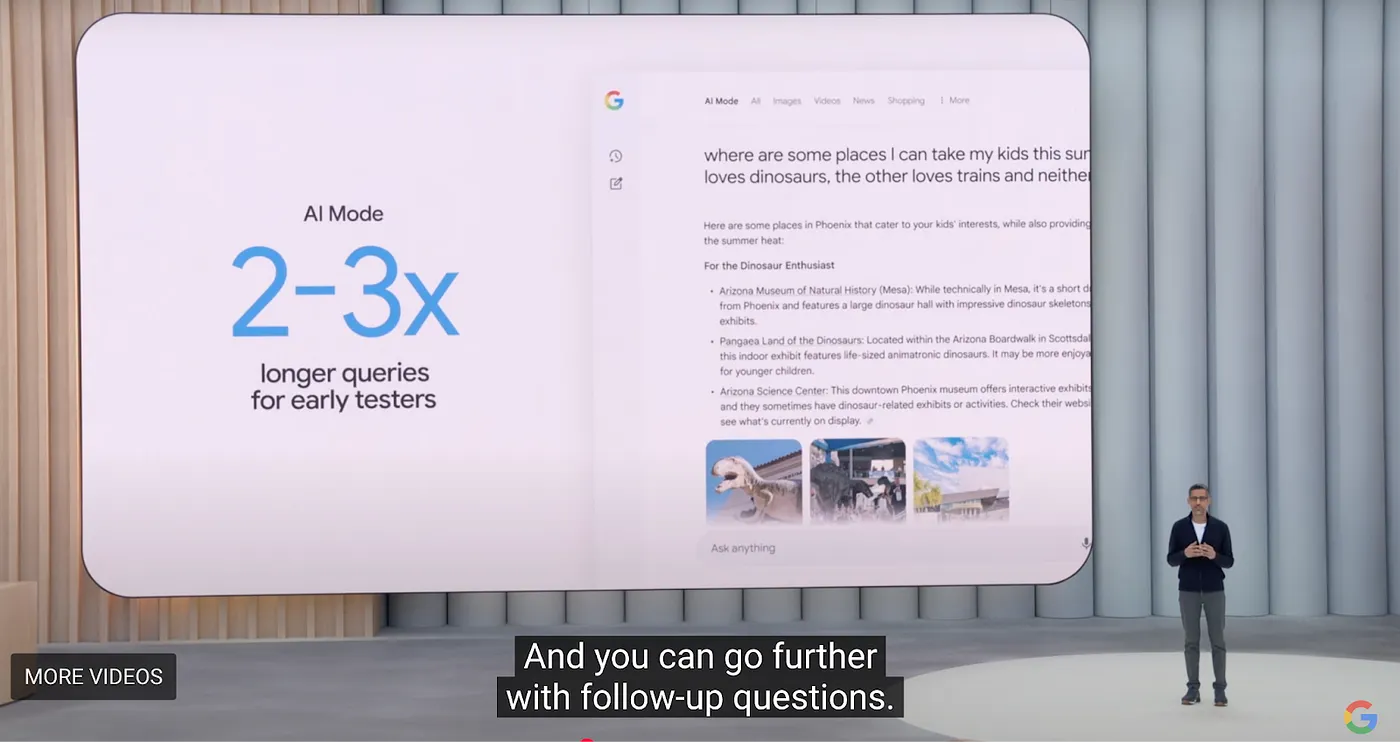
Aber Perplexity muss noch zwei Kernprobleme lösen: hohe Suchkosten und niedrige Gewinnmargen bei marginalen Nutzern. Obwohl Perplexity derzeit im Bereich der KI-Suche führend ist, kündigte Google auf seiner I/O-Konferenz 2025 eine umfassende intelligente Überarbeitung seiner Kernprodukte an. Für Browser hat Google eine neue Browser-Tab-Erfahrung namens AI Model eingeführt, die Übersicht, tiefgehende Forschung und zukünftige agentische Fähigkeiten integriert. Die gesamte Initiative wird als "Projekt Mariner" bezeichnet.
Google treibt aktiv seine KI-Transformation voran, was bedeutet, dass oberflächliche Funktionen wie Übersicht, Tiefenforschung oder Agentik kaum eine echte Bedrohung darstellen werden. Was inmitten des Chaos wirklich eine neue Ordnung etablieren könnte, ist der Wiederaufbau der Browserarchitektur von Grund auf, das tiefe Einbetten großer Sprachmodelle (LLMs) in den Browserkernel und die grundlegende Transformation der Interaktionsmethoden.
Brave
Brave ist einer der frühesten und erfolgreichsten Browser in der Krypto-Industrie. Er basiert auf der Chromium-Architektur und ist mit Erweiterungen aus dem Google Store kompatibel. Brave zieht Benutzer mit einem Modell an, das auf Datenschutz basiert und das Verdienen von Token durch Surfen ermöglicht. Sein Entwicklungspfad zeigt ein gewisses Wachstumspotenzial. Aus Produktperspektive bleibt jedoch die Nachfrage, obwohl Datenschutz in der Tat wichtig ist, innerhalb spezifischer Benutzergruppen konzentriert. Für die breitere Öffentlichkeit ist das Bewusstsein für Datenschutz noch nicht zu einem Mainstream-Entscheidungsfaktor geworden. Daher ist es unwahrscheinlich, dass der Versuch, sich allein auf dieses Merkmal zu verlassen, um bestehende Giganten zu stören, erfolgreich sein wird.
Stand jetzt hat Brave 82,7 Millionen monatlich aktive Nutzer (MAU) und 35,6 Millionen täglich aktive Nutzer (DAU) erreicht, was einem Marktanteil von etwa 1 %–1,5 % entspricht. Die Nutzerbasis hat ein stetiges Wachstum gezeigt: von 6 Millionen im Juli 2019, über 25 Millionen im Januar 2021, bis hin zu 57 Millionen im Januar 2023, und bis Februar 2025 überschritt sie 82 Millionen. Die jährliche Wachstumsrate liegt weiterhin im zweistelligen Bereich.
Brave verarbeitet etwa 1,34 Milliarden Suchanfragen pro Monat, was etwa 0,3 % des Volumens von Google entspricht.
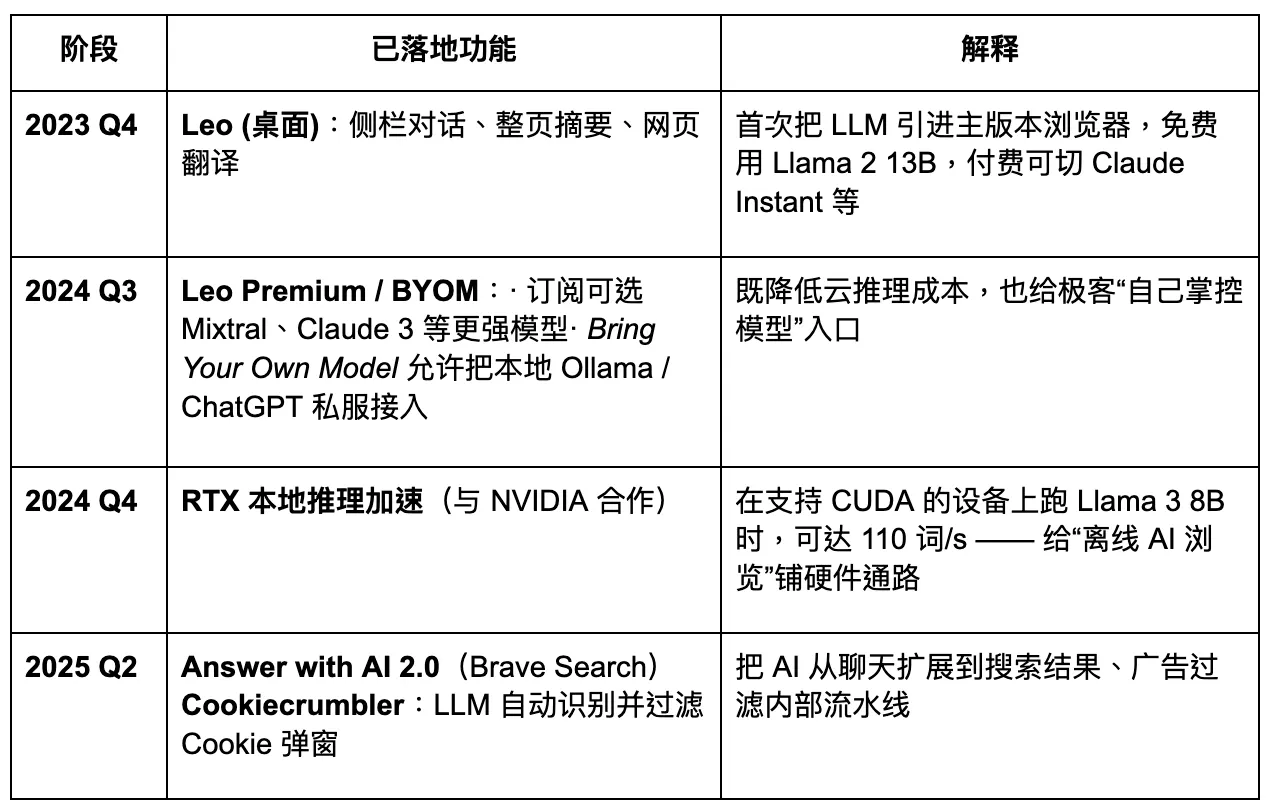
Brave plant, in einen datenschutzorientierten AI-Browser aufzurüsten. Allerdings reduziert der begrenzte Zugang zu Nutzerdaten das Maß an Anpassungsmöglichkeiten für große Modelle, was wiederum schnelle und präzise Produktiteration behindert. In der kommenden Ära des Agentic Browsers könnte Brave einen stabilen Anteil unter bestimmten datenschutzorientierten Nutzergruppen halten, aber es wird schwierig sein, ein dominanter Akteur zu werden. Sein AI-Assistent Leo funktioniert eher wie eine Plugin-Erweiterung – bietet einige Funktionen zur Inhaltszusammenfassung, hat jedoch keine klare Strategie für einen vollständigen Übergang zu AI-Agenten. Innovation in der Interaktion bleibt unzureichend.
Donut
In letzter Zeit hat die Kryptoindustrie auch Fortschritte im Bereich der Agentic Browsers gemacht. Das frühphasige Projekt Donut hat in einer Pre-Seed-Runde 7 Millionen US-Dollar gesammelt, angeführt von Hongshan (Sequoia China), HackVC und Bitkraft Ventures. Das Projekt befindet sich noch in der frühen Konzeptionsphase, mit dem Ziel, eine integrierte Fähigkeit zur "Entdeckung – Entscheidungsfindung – und Krypto-nativen Ausführung" zu erreichen.
Die Kernrichtung besteht darin, kryptonative automatisierte Ausführungspfade zu kombinieren. Wie a16z vorhergesagt hat, könnten Agenten in Zukunft die Hauptverkehrs-Gateways ersetzen. Unternehmer werden nicht mehr um die Ranking-Algorithmen von Google konkurrieren, sondern vielmehr um den Verkehr und die Konversionen, die aus der Ausführung durch Agenten resultieren. Die Branche hat diesen Trend bereits als "AEO" (Answer / Agent Engine Optimization) bezeichnet, oder sogar weiter als "ATF" (Agentic Task Fulfillment) – wobei das Ziel nicht mehr darin besteht, die Suchrankings zu optimieren, sondern direkt intelligente Modelle zu bedienen, die Aufgaben für Nutzer erledigen können, wie z.B. Bestellungen aufzugeben, Tickets zu buchen oder Briefe zu schreiben.
Für Unternehmer
Zunächst muss anerkannt werden: Der Browser selbst bleibt das größte nicht rekonstruierte „Gateway“ in der Internetwelt. Mit rund 2,1 Milliarden Desktop-Nutzern und über 4,3 Milliarden mobilen Nutzern weltweit dient er als gemeinsamer Träger für Dateneingaben, interaktive Verhaltensweisen und die Speicherung personalisierter Fingerabdrücke. Der Grund für seine Persistenz ist nicht Trägheit, sondern die inhärente Dualität des Browsers: Er ist sowohl der Einstiegspunkt zum Lesen von Daten als auch der Ausgangspunkt für Schreibaktionen.
Daher liegt das wahre disruptive Potenzial für Unternehmer nicht in der Optimierung der "Seitenausgabe"-Ebene. Selbst wenn man Google-ähnliche KI-Überblicksfunktionen in einem neuen Tab replizieren könnte, wäre das immer noch nur eine Iteration auf der Plugin-Ebene, kein grundlegender Paradigmenwechsel. Der wahre Durchbruch liegt auf der "Eingabeseite" – wie man KI-Agenten aktiv dazu bringt, Ihr Produkt aufzurufen, um spezifische Aufgaben zu erledigen. Das wird bestimmen, ob ein Produkt in das Agenten-Ökosystem eingebettet werden kann, um Traffic zu erfassen und an der Wertverteilung teilzuhaben.
In der Suchära ging es um Klicks; in der Agentenära geht es um Anrufe.
Wenn Sie ein Unternehmer sind, sollten Sie Ihr Produkt als API-Komponente neu denken – etwas, das ein intelligenter Agent nicht nur verstehen, sondern auch aufrufen kann. Dies erfordert, dass Sie bereits zu Beginn des Produktdesigns drei Dimensionen berücksichtigen:
1. Schnittstellenstrukturstandardisierung: Ist Ihr Produkt anrufbar?
Die Fähigkeit eines Agenten, ein Produkt zu aktivieren, hängt davon ab, ob seine Informationsstruktur standardisiert und in ein klares Schema abstrahiert werden kann. Zum Beispiel, können wichtige Aktionen wie die Benutzerregistrierung, die Bestellung oder die Einreichung von Kommentaren durch eine semantische DOM-Struktur oder JSON-Mapping beschrieben werden? Bietet das System eine Zustandsmaschine, damit der Agent Benutzer-Workflows zuverlässig replizieren kann? Können Benutzerinteraktionen auf der Seite skriptiert werden? Bietet das Produkt stabile Webhooks oder API-Endpunkte?
Genau aus diesem Grund ist es Browser Use gelungen, Kapital zu beschaffen – es verwandelte den Browser von einem flachen HTML-Renderer in einen semantischen Baum, der von LLMs aufgerufen werden kann. Für Unternehmer bedeutet die Annahme einer ähnlichen Designphilosophie in Webprodukten, sich auf eine strukturierte Anpassung in der Ära der KI-Agenten vorzubereiten.
2. Identität und Zugriff: Können Sie den Agenten helfen, die "Vertrauensbarriere" zu überwinden?
Um Transaktionen abzuschließen oder Zahlungs- und Vermögensfunktionen aufzurufen, benötigen Agenten einen vertrauenswürdigen Vermittler – könnten Sie dieser Vermittler werden? Browser haben von Natur aus die Fähigkeit, lokalen Speicher zu lesen, auf Wallets zuzugreifen, CAPTCHAs zu bearbeiten und die Zwei-Faktor-Authentifizierung zu integrieren. Dies macht sie geeigneter als cloudbasierte Modelle zur Ausführung von Aufgaben. Dies gilt insbesondere für Web3, wo Schnittstellen zur Interaktion mit Vermögenswerten nicht standardisiert sind. Ohne „Identität“ oder „Unterzeichnungsfähigkeit“ kann ein Agent nicht weiterkommen.
Für Krypto-Unternehmer eröffnet dies einen äußerst kreativen Freiraum: die „MCP (Multi Capability Platform) der Blockchain-Welt.“ Dies könnte in Form einer universellen Befehlsoberfläche (die es Agenten ermöglicht, Dapps aufzurufen), eines standardisierten Vertragsinterface-Sets oder sogar einer leichten lokalen Wallet + Identitäts-Hub erfolgen.
3. Überdenken von Verkehrsmechanismen: Die Zukunft ist nicht SEO, sondern AEO / ATF.
In der Vergangenheit mussten Sie den Algorithmus von Google gewinnen; jetzt müssen Sie in die Aufgabenketten von KI-Agenten eingebettet sein. Das bedeutet, dass Ihr Produkt eine klare Aufgaben-Granularität haben muss: nicht eine "Seite", sondern eine Reihe von aufrufbaren Fähigkeitseinheiten. Es bedeutet auch, dass Sie mit der Optimierung für Agent Engine Optimization (AEO) beginnen oder sich an Agentic Task Fulfillment (ATF) anpassen müssen. Zum Beispiel, kann der Registrierungsprozess in strukturierte Schritte vereinfacht werden? Kann die Preisgestaltung über eine API abgerufen werden? Ist der Bestand in Echtzeit zugänglich?
Sie müssen möglicherweise sogar lernen, sich an unterschiedliche Aufrufsyntaxen in verschiedenen LLM-Frameworks anzupassen – da OpenAI und Claude beispielsweise unterschiedliche Vorlieben für Funktionsaufrufe und die Nutzung von Tools haben. Chrome ist das Terminal der alten Welt, nicht das Gate zur neuen. Die Projekte der Zukunft werden keine Browser neu aufbauen, sondern Browser dazu bringen, Agenten zu dienen – Brücken für die neue Generation von "Instruktionsflüssen" zu bauen.
Was Sie aufbauen müssen, ist die "Schnittstellensprache", über die Agenten Ihre Welt aufrufen.
Was Sie verdienen müssen, ist ein Platz in der Vertrauenskette intelligenter Systeme.
Was Sie konstruieren müssen, ist ein "API-Schloss" im nächsten Suchparadigma.
Wenn Web2 die Aufmerksamkeit der Nutzer durch UI erfasste, wird die Web3 + KI-Agenten-Ära nun die Ausführungsabsicht der Agenten durch Anrufketten erfassen.
Haftungsausschluss
Dieser Inhalt stellt kein Angebot, keine Aufforderung oder Empfehlung dar. Sie sollten immer unabhängige professionelle Beratung einholen, bevor Sie eine Investitionsentscheidung treffen. Bitte beachten Sie, dass Gate und/oder Gate Ventures einige oder alle Dienstleistungen in eingeschränkten Regionen einschränken oder verbieten können. Bitte lesen Sie die geltenden Nutzungsbedingungen für weitere Einzelheiten.
Über Gate Ventures
Gate Ventures ist der Risikokapitalzweig von Gate, der sich auf Investitionen in dezentrale Infrastruktur, Ökosysteme und Anwendungen konzentriert – Technologien, die die Welt im Web 3.0-Zeitalter umgestalten werden. Gate Ventures arbeitet mit globalen Branchenführern zusammen, um Teams und Startups mit innovativem Denken und Fähigkeiten zu stärken, um die Interaktion zwischen Gesellschaft und Finanzen neu zu definieren.
Website: https://www.gate.com/ventures