PhyrexNi
用户暂无简介
😂X 的中文区越来越像 + 小红书 了
- 赞赏
- 点赞
- 评论
- 转发
- 分享

话说我最近两天发现 X 发文的图片不能拖拽了,应该是 X 不太喜欢用常规发长文,希望长文都跑去文章吧。但文章最大的问题就是文章不能引用文章,能把这个改了就好。
- 赞赏
- 1
- 评论
- 转发
- 分享
刚刚看到在以色列对德黑兰主要机场发动打击,有目击者称甚至有一架客机被击中。本来战争涉及到平民是应该被谴责的,但伊朗袭击了迪拜机场的时候就应该想到会有报复性的打击,今天川普也公开表示,伊朗接下来会面对之前三倍的攻击力度。
愿世界和平,我不太愿意被动赞助战争
愿世界和平,我不太愿意被动赞助战争
- 赞赏
- 点赞
- 评论
- 转发
- 分享
以色列称伊朗最高领袖哈梅内伊已死亡,其遗体已被找到。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
希望迪拜和阿布扎比的小伙伴们都安然无恙。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
以色列🇮🇱对伊朗🇮🇷实施预防性打击
本次打击由 @PhyrexNi 非主动赞助
本次打击由 @PhyrexNi 非主动赞助
- 赞赏
- 点赞
- 评论
- 转发
- 分享
😂今天写的累成汪汪了,本来按照 X 的规则我这么发是吃亏的,毕竟短期发较多的长文权重和推荐会降低,但对我来说,重要的并不是 X 的规则能给我带来多少收入,而是我能不能在需要的时间做需要的事情。
链上数据的解读后如果不动了,可能自然扩散量是最大的,但是看到很多小伙伴在研究换个生活环境的时候,我就想聊聊可能大家没注意的事情,放在明天也没事,但明天我觉得可能还有明天需要写的东西。
看到 $CRCL 的财报,我也可以等到明天再写,但明天写完的时效和当前是完全不同的,今天整整写了12个小时,中间就吃了一顿饭。很累,但很有成就感。
当然我写的很多小伙伴觉得又臭又长,没事,我写的内容涵盖了从宏观到数据,从生活到生存,也许以后能适合你,写的详细一些,最起码当有需要的小伙伴查看的时候能一站式的解决问题,这我就知足了。
做内容创造,并不应该被框架束缚,做自己觉得是正确的事情,会让身心愉悦,虽然可能会慢,但会在正确的路上前进。
休息一两个小时,回来继续写 ETF 和作业。
@ VIP,费率更低,福利更狠
链上数据的解读后如果不动了,可能自然扩散量是最大的,但是看到很多小伙伴在研究换个生活环境的时候,我就想聊聊可能大家没注意的事情,放在明天也没事,但明天我觉得可能还有明天需要写的东西。
看到 $CRCL 的财报,我也可以等到明天再写,但明天写完的时效和当前是完全不同的,今天整整写了12个小时,中间就吃了一顿饭。很累,但很有成就感。
当然我写的很多小伙伴觉得又臭又长,没事,我写的内容涵盖了从宏观到数据,从生活到生存,也许以后能适合你,写的详细一些,最起码当有需要的小伙伴查看的时候能一站式的解决问题,这我就知足了。
做内容创造,并不应该被框架束缚,做自己觉得是正确的事情,会让身心愉悦,虽然可能会慢,但会在正确的路上前进。
休息一两个小时,回来继续写 ETF 和作业。
@ VIP,费率更低,福利更狠
- 赞赏
- 点赞
- 评论
- 转发
- 分享
川普的和平委员会正在研究为加沙发行稳定币
据 Financial Times 的报道,川普阵营推动的“和平委员会 正在讨论为加沙引入一个美元挂钩稳定币,用途不是替代加沙币或成为一种新的巴勒斯坦货币,而是作为在银行体系和现金流受损情况下的数字支付与电子金融工具,同时希望减少哈马斯对实体现金流的接触空间。
当然现在还在讨论的初级阶段,该想法的工作由以色列科技企业家、前预备役军人 Liran Tancman 主导,他目前作为川普和平委员会的无薪顾问工作,该委员会是负责重建加沙的美国领导机构。
Tancman 在上周于华盛顿举行的和平委员会会议上表示,NCAG 正在构建一条安全的数字骨干网,一个开放平台,支持电子支付、金融服务、电子学习和医疗保健,并让用户控制数据,但未作详细说明。
@ VIP,费率更低,福利更狠
据 Financial Times 的报道,川普阵营推动的“和平委员会 正在讨论为加沙引入一个美元挂钩稳定币,用途不是替代加沙币或成为一种新的巴勒斯坦货币,而是作为在银行体系和现金流受损情况下的数字支付与电子金融工具,同时希望减少哈马斯对实体现金流的接触空间。
当然现在还在讨论的初级阶段,该想法的工作由以色列科技企业家、前预备役军人 Liran Tancman 主导,他目前作为川普和平委员会的无薪顾问工作,该委员会是负责重建加沙的美国领导机构。
Tancman 在上周于华盛顿举行的和平委员会会议上表示,NCAG 正在构建一条安全的数字骨干网,一个开放平台,支持电子支付、金融服务、电子学习和医疗保健,并让用户控制数据,但未作详细说明。
@ VIP,费率更低,福利更狠
- 赞赏
- 点赞
- 评论
- 转发
- 分享
解读 SEC 稳定币折价率松绑 — — 是利好,还是利空?
就在今天,SEC 交易与市场部门更新了常见问题解答,明确表示在券商净资本规则的计算中,合规“支付型稳定币”可以按 2% 折价率处理(工作人员不反对)。随后 SEC 委员 Hester Peirce 发声明回应,稳定币在监管资本计量里,终于从几乎不可用资产,开始走向更接近低风险现金类工具。
1. 什么是折价率?
折价率就是监管对资产风险的定价。
为了防止券商破产,监管要求他们必须持有一定的净资本。在计算这些资本时,手里的资产不能按市价 100% 计算,必须打个折。
以往稳定币 100% 折价率就意味着监管认为稳定币风险极高,价值计为 0。比如券商持有 100 万美元稳定币,为了维持合规不仅花了 100 万美元去购买稳定币,还需要额外准备 100 万美元的现金来作为“保证金”。
而现在更改成 2% 折价率就意味着监管认为稳定币作为资产非常安全,价值计为 98%。这和货币市场基金(MMF)的待遇是一样的。再持有 100 万美元的稳定币,监管承认价值是 98 万美元。只需要额外准备 2 万美元的保证金就可以。
资本利用效率瞬间提升了 50 倍。
2. 利好于谁?
对于高盛、摩根大通或 Robinhood 这种受监管的持牌机构来说,以前 100% 的折价率对于机构来说,配置稳定币是一种自残,而修改后对于机构来说,配置稳定币几乎就没有
就在今天,SEC 交易与市场部门更新了常见问题解答,明确表示在券商净资本规则的计算中,合规“支付型稳定币”可以按 2% 折价率处理(工作人员不反对)。随后 SEC 委员 Hester Peirce 发声明回应,稳定币在监管资本计量里,终于从几乎不可用资产,开始走向更接近低风险现金类工具。
1. 什么是折价率?
折价率就是监管对资产风险的定价。
为了防止券商破产,监管要求他们必须持有一定的净资本。在计算这些资本时,手里的资产不能按市价 100% 计算,必须打个折。
以往稳定币 100% 折价率就意味着监管认为稳定币风险极高,价值计为 0。比如券商持有 100 万美元稳定币,为了维持合规不仅花了 100 万美元去购买稳定币,还需要额外准备 100 万美元的现金来作为“保证金”。
而现在更改成 2% 折价率就意味着监管认为稳定币作为资产非常安全,价值计为 98%。这和货币市场基金(MMF)的待遇是一样的。再持有 100 万美元的稳定币,监管承认价值是 98 万美元。只需要额外准备 2 万美元的保证金就可以。
资本利用效率瞬间提升了 50 倍。
2. 利好于谁?
对于高盛、摩根大通或 Robinhood 这种受监管的持牌机构来说,以前 100% 的折价率对于机构来说,配置稳定币是一种自残,而修改后对于机构来说,配置稳定币几乎就没有
USD1-0.01%
- 赞赏
- 点赞
- 评论
- 转发
- 分享
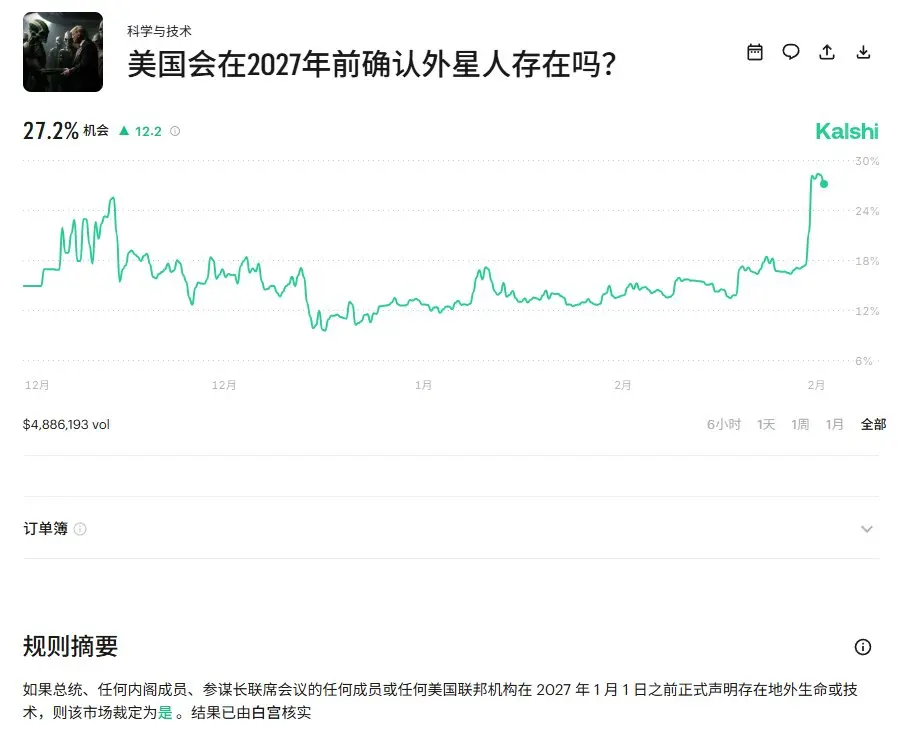
我估计川普在玩 Kalshi ,本来看到一个概率很低的预测,“美国不会不会在2027年前公布外星人的存在”,我还在想不可能呢,即便是美国有证据,也不太可能会现在现在公布,结果没想到今天早晨川普直接来了这么一手。现在 Kalshi 上的概率已经大幅提升了。
- 赞赏
- 1
- 评论
- 转发
- 分享
CME 将于 2026年5月29日 推出 7×24 小时加密货币期货和期权交易
CME 集团今日宣布,其受监管的加密货币期货和期权将在经监管审查后于5月29日起实现全天候(每周七天、每天 24 小时)交易。
“客户对在数字资产市场进行风险管理的需求处于历史高位,推动我们 2025 年加密货币期货和期权名义成交额创下 3 万亿美元的纪录,”CME 集团全球股票、外汇与另类产品负责人 Tim McCourt 表示。
“尽管并非所有市场都适合 24/7 运行,但为我们的受监管、透明的加密货币产品提供随时可用的访问,能够确保客户在任何时间管理敞口并自信交易。”
自5月29日星期五中部时间下午 4:00 起,CME Group 加密货币期货和期权将在 CME Globex 上持续交易,周末至少保留两小时的每周维护时间。
从周五晚上到周日晚间的所有节假日或周末交易的交易日期均为下一个营业日,结算、交收和监管报告也将在下一个营业日处理。
CME 集团今日宣布,其受监管的加密货币期货和期权将在经监管审查后于5月29日起实现全天候(每周七天、每天 24 小时)交易。
“客户对在数字资产市场进行风险管理的需求处于历史高位,推动我们 2025 年加密货币期货和期权名义成交额创下 3 万亿美元的纪录,”CME 集团全球股票、外汇与另类产品负责人 Tim McCourt 表示。
“尽管并非所有市场都适合 24/7 运行,但为我们的受监管、透明的加密货币产品提供随时可用的访问,能够确保客户在任何时间管理敞口并自信交易。”
自5月29日星期五中部时间下午 4:00 起,CME Group 加密货币期货和期权将在 CME Globex 上持续交易,周末至少保留两小时的每周维护时间。
从周五晚上到周日晚间的所有节假日或周末交易的交易日期均为下一个营业日,结算、交收和监管报告也将在下一个营业日处理。
- 赞赏
- 2
- 评论
- 转发
- 分享
美国与伊朗开战的风险上升。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
热门 Gate Fun
查看更多- 市值:$2241.37持有人数:10.00%
- 市值:$0.1持有人数:10.00%
- 市值:$2241.37持有人数:10.00%
- 市值:$2306.66持有人数:20.36%
- 市值:$0.1持有人数:00.00%
置顶
📢 Gate 广场|4/4 热议:#三月非农数据来袭
🚨 美国三月非农就业数据已公布!市场波动或将加剧,你怎么看?
非农数据作为衡量美国经济的重要指标,每次公布都可能引发全球市场震荡。本次数据释放了哪些信号?是否会影响美联储后续政策与市场走势?
🎁 分享观点,抽 5 位锦鲤瓜分 $1,000 仓位体验券!
💬 本期讨论:
1️⃣ 本次非农数据透露了哪些经济信号?
2️⃣ 数据公布后,对加密市场会带来哪些影响?
分享你的观点 👉 https://www.gate.com/post
📅 4/3 15:00 - 4/5 18:00 (UTC+8)📢 GM!Gate 广场|4/5 热议:#假期持币指南
🌿 踏青还是盯盘?#假期持币指南 带你过个“松弛感”长假!
春光正好,你是选择在山间深呼吸,还是在 K 线里找时机?在这个清明假期,晒出你的持币态度,做个精神饱满的交易员!
🎁 分享生活/交易感悟,抽 5 位锦鲤瓜分 $1,000 仓位体验券!
💬 茶余饭后聊聊:
1️⃣ 休假心态: 你是“关掉通知、彻底失联”派,还是“每 30 分钟必刷行情”派?
2️⃣ 懒人秘籍: 假期不想盯盘?分享你的“挂机”策略(定投/网格/理财)。
3️⃣ 四月展望: 假期过后,你最看好哪个币种“春暖花开”?
分享你的假期姿态 👉 https://www.gate.com/post
📅 4/4 15:00 - 4/6 18:00 (UTC+8)✍️ Gate 广场「创作者认证激励计划」进行中!
我们欢迎优质创作者积极创作,申请认证
赢取豪华代币奖池、Gate 精美周边、流量曝光等超 $10,000+ 丰厚奖励!
立即报名 👉 https://www.gate.com/questionnaire/7159
📕 认证申请步骤:
1️⃣ App 首页底部进入【广场】 → 点击右上角头像进入个人主页
2️⃣ 点击头像右下角【申请认证】进入认证页面,等待审核
让优质内容被更多人看到,一起共建创作者社区!
活动详情:https://www.gate.com/announcements/article/47889#Gate广场四月发帖挑战 狂欢开启!🧧
发帖即赚,天天都有红包领,新人100%中奖!
🎁 福利亮点:
✅ 新人礼: 发布广场首帖,100% 必中红包!
✅ 发帖奖: 发帖越多,互动越多,红包金额越大!
✅ 分享王: 转发活动链接到广场或外部平台,送 Gate 开瓶器 + 200U!
✅ 冲榜单: Top 100 都有奖,Gate 13 周年限定礼盒、红牛夹克等您拿!
立即行动,发布你的四月广场第一帖!
👉️ https://www.gate.com/post
🗓 截止日期: 4 月 15 日
详情:https://www.gate.com/announcements/article/50520