Iceberg+Spark+Trino:区块链的现代开源数据堆栈
在本章中,你将认识 Footprint 的关键架构更新、特色功能;以及它在数据收集和整理方面的表现
现代区块链数据堆栈面临的挑战
现代区块链索引初创公司可能面临几个挑战,包括:
- 巨大的数据量。随着区块链上数据量的增加,数据索引将需要扩展以处理增加的负载并提供高效的数据访问。这会导致更高的存储成本、缓慢的指标计算和数据库服务器负载的增加。
- 复杂的数据处理管道。区块链技术很复杂,构建全面可靠的数据索引需要深入了解底层数据结构和算法。这也受到区块链实现方案多样性的影响。举个具体的例子,以太坊中的 NFT 通常是在遵循 ERC721 和 ERC1155 格式的智能合约中创建的,而 Polkadot 上的 NFT 通常是直接在区块链运行时构建的。但最终,它们都应被视为 NFT 并应以此方式保存。
- 集成能力。为了为用户提供最大价值,区块链索引解决方案可能需要将其数据索引与其他系统(如分析平台或 API)集成。这是具有挑战性的,需要在架构设计上投入大量努力。
随着区块链技术的使用越来越广泛,存储在区块链上的数据量也增加了。这是因为随着越来越多的人使用该技术,每笔交易都会向区块链添加新数据。此外,区块链技术的使用已经从简单的货币转移应用(如关于比特币使用的应用)发展到在智能合约中实现业务逻辑的更复杂的应用。这些智能合约会产生大量数据,导致区块链更加复杂、更加庞大。
在本文中,我们分阶段回顾了 Footprint Analytics 技术架构的演变,并以此为例,探讨了 Iceberg-Trino 技术堆栈如何应对链上数据的挑战。
Footprint Analytics 已经将大约 22 个公链数据、17 个 NFT 市场、1900 个 GameFi 项目和超过 10 万个 NFT 集合索引到语义抽象数据层中。它是世界上最全面的区块链数据仓库解决方案。
区块链数据包括超过 200 亿行的金融交易记录,经常被数据分析师查询。
为满足不断增长的业务需求,在过去的几个月中,我们进行了 3 次重大升级,包括:
架构 1.0 Bigquery
在 Footprint Analytics 最初,我们使用谷歌 Bigquery 作为我们的存储和查询引擎。Bigquery 是一个很棒的产品,它速度极快,易于使用,并提供动态算术能力和灵活的 UDF 语法,能够帮助我们快速完成工作。
然而,Bigquery 也存在一些问题。
- 数据没有压缩,导致存储成本很高,特别是在存储 Footprint Analytics 超过 22 个区块链的原始数据时。
- 并发能力不足:Bigquery 仅同时支持 100 条查询,不适用于 Footprint Analytics 的高并发场景,因为需要为大量分析师和用户提供服务。
- 非开源产品,绑定 Google 一家供应商。
因此,我们决定探索其他替代架构。
架构 2.0 OLAP
我们对一些非常流行的 OLAP(联机分析处理)产品感兴趣,OLAP 最吸引人的优势是它的查询响应时间,通常能在亚秒内返回大量数据的查询结果,并且还支持数千个同时查询。
我们选择了最好的 OLAP 数据库之一 Doris。这个引擎表现不错,但我们很快遇到了一些其他问题:
- 尚不支持数组或 JSON 等数据类型(截至 2022 年 11 月)。数组是某些区块链中常见的数据类型。例如,evm 日志中的 topic 字段。无法直接对数组进行计算,会影响我们计算许多业务指标。
- 对 DBT 和 merge 语法的支持有限。它们是数据工程师在 ETL/ELT( 数据提取 - 加载 - 转换 ) 场景中常见的需求,我们需要更新一些新索引的数据。
话虽如此,我们无法在生产中完全使用 Doris 作为整个数据管道,因此我们尝试将 Doris 作为 OLAP 数据库来解决我们在数据生产管道中的一部分问题,作为查询引擎并提供快速和高并发的查询能力。
然而,我们无法用 Doris 替代 Bigquery,因此需要定期将数据从 Bigquery 同步到 Doris,仅将 Doris 作为查询引擎。这个同步过程存在许多问题,其中之一是当 OLAP 引擎忙于向前端客户端提供查询时,写入数据会迅速堆积起来。随后,写入过程的速度受到影响,同步会花费更长的时间,有时甚至无法完成。
我们意识到,OLAP 可以解决我们面临的几个问题,但无法成为 Footprint Analytics 的一站式解决方案,特别是对于数据处理管道而言。我们的问题更大更复杂,可以说,OLAP 仅仅作为一个查询引擎对我们来说还不够。
架构 3.0 Iceberg + Trino
欢迎来到 Footprint Analytics 架构 3.0,这是对底层架构的全面重构。我们从头开始重新设计了整个架构,将数据的存储、计算和查询分成三个不同的部分,从 Footprint Analytics 早期的两个架构中吸取教训,并从其他成功的大数据项目如 Uber、Netflix 和 Databricks 中学习经验。
数据湖的引入
我们首先将注意力转向了数据湖,这是一种用于结构化和非结构化数据的新型数据存储方式。数据湖非常适合链上数据的存储,因为链上数据的格式范围广泛,包括非结构化原始数据和 Footprint Analytics 所著名的结构化抽象数据。我们期望用数据湖来解决数据存储问题,理想情况下,它还将支持 Spark 和 Flink 等主流计算引擎,这样,随着 Footprint Analytics 的发展,在与不同类型的处理引擎集成就不会出现额外问题。
Iceberg 与 Spark、Flink、Trino 和其他计算引擎可以非常好地集成到一起,我们可以为每个指标选择最合适的计算方式。例如:
- 对于需要复杂计算逻辑的指标,Spark 将是首选。
- Flink 适用于实时计算。
- 对于可以用 SQL 执行的简单 ETL 任务,我们使用 Trino。
查询引擎
Iceberg 解决了存储和计算问题,接下来,我们将需要考虑如何选择查询引擎。可用的选项并不多,我们考虑的替代方案包括:
- Trino:SQL 查询引擎
- Presto:SQL 查询引擎
- Kyuubi:无服务器 Spark SQL
在深入研究之前,我们考虑的最重要的事情是,未来的查询引擎必须与我们当前的架构兼容。
- 支持 Bigquery 作为数据源
- 支持 DBT(我们依赖它来生成许多指标)
- 支持 BI(商业智能)工具 Metabase
基于以上考虑,我们选择了 Trino,它对 Iceberg 有很好的支持,团队响应非常迅速,我们曾提出的 bug 在第二天便修复了,并在第二周发布了最新版本。对于需要较高响应能力的团队 Footprint 而言,这绝对是 Footprint 的最佳选择。
性能测试
定好方向之后,我们就对 Trino+Iceberg 组合进行了性能测试,看看它是否能满足我们的需求。出乎意料的是,它的查询速度非常快。
我们知道多年来,Presto+Hive 一直是 OLAP 领域中性能最差的对手,但 Trino+Iceberg 组合完全颠覆了我们的认知。
我们的测试结果如下。
示例 1:连接大型数据集
将一个 800 GB 的表 1 与另一个 50 GB 的表 2 连接,并进行复杂的业务计算。示例 2:大表单执行不重复查询
测试用的 sql:从表中按日期分组选择不同的地址

Trino+Iceberg 组合在相同配置下比 Doris 快约 3 倍。
此外,Iceberg 可以使用 Parquet、ORC 等数据格式,这些格式会对数据进行压缩存储。Iceberg 的表存储占用的空间仅为其他数据仓库的 1/5 左右,三个数据库中相同表的存储大小如下:

注:以上测试是我们在实际生产中遇到的个别示例,仅供参考。
升级效果
性能测试报告为我们提供了足够的性能,以至于我们的团队花了大约 2 个月的时间才完成迁移。以下是我们升级后的架构图。
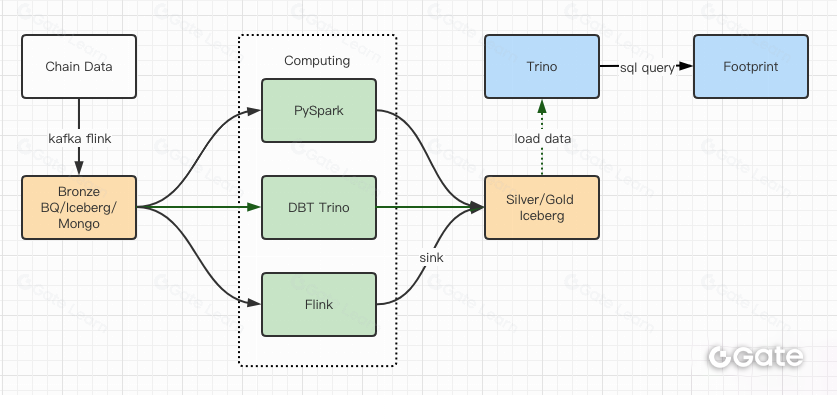
- 多个计算机引擎满足我们的各种需求。
- Trino 支持 DBT,可以直接查询 Iceberg,所以我们不再需要处理数据同步。
- Trino+Iceberg 的惊人性能使我们能够向用户开放所有黄铜数据(原始数据)。
小结
自 2021 年 8 月推出以来,Footprint Analytics 团队在不到一年半的时间内完成了三次架构升级,这要归功于团队为加密货币用户带来最佳数据库技术优势的渴望和决心,以及在实施和升级底层基础设施和架构方面的出色表现。
Footprint Analytics 架构 3.0 升级为用户带来了全新的体验,让具有不同背景的用户能够深入了解更多样化的用途和使用场景:
- Footprint 使用 Metabase BI 工具进行构建,有助于分析师访问解码的链上数据,完全自由地选择工具(无需代码或硬编码)进行探索,查询完整的历史记录,交叉检查数据集,及时获得深入分析。
- 将链上和链下数据整合到 Web2+Web3 的分析中。
- 通过在 Footprint 的业务抽象之上构建 / 查询指标,分析师或开发人员可以节省 80% 的重复数据处理时间,并专注于基于其业务的有意义的指标、研究和产品解决方案。
- 从 Footprint Web 到 REST API 调用的无缝体验,全部基于 SQL。
- 提供关键信号的实时警报和可操作通知,以支持投资决策。
相关课程

Aethir 介绍

加密货币领域的身份验证项目概览

加密领域自主研究指南(DYOR)
稳定币基础

解析 L1 区块链:Kaia
