Google выпустила Gemini 3.1 Pro, результаты тестирования ARC-AGI-2 (логические способности модели при решении новых задач) удвоились по сравнению с предыдущим поколением, достигнув 77.1%. В 16 тестовых стандартах модель заняла 13 первых мест. Цены на API остались без изменений, а гонка за ИИ ускоряет сокращение жизненного цикла каждой новой модели.
(Предыстория: Gemini запустила бесплатную функцию «Моделирование SAT», ИИ-репетитор предлагает персонализированные учебные планы)
(Дополнительный фон: Google официально представила «Gemini 3»! Вершина мировых умных ИИ — в чем ее особенности?)
Содержание статьи
- «Настраиваемое рассуждение»: позволяя разработчикам самим выбирать уровень интеллекта модели
- Цены без изменений, эффективность удвоена: кто субсидирует эту гонку?
- Нет победителя, захватывающего всё, но есть ясная конкурентная структура
В ночь с 19-го числа Google официально выпустила предварительную версию Gemini 3.1 Pro. В тесте ARC-AGI-2 модель достигла 77.1%, что более чем в два раза превышает показатели предыдущего Gemini 3 Pro.
На следующем изображении, в списке из 16 оценочных стандартов, Gemini 3.1 Pro заняла первое место в 13 из них.
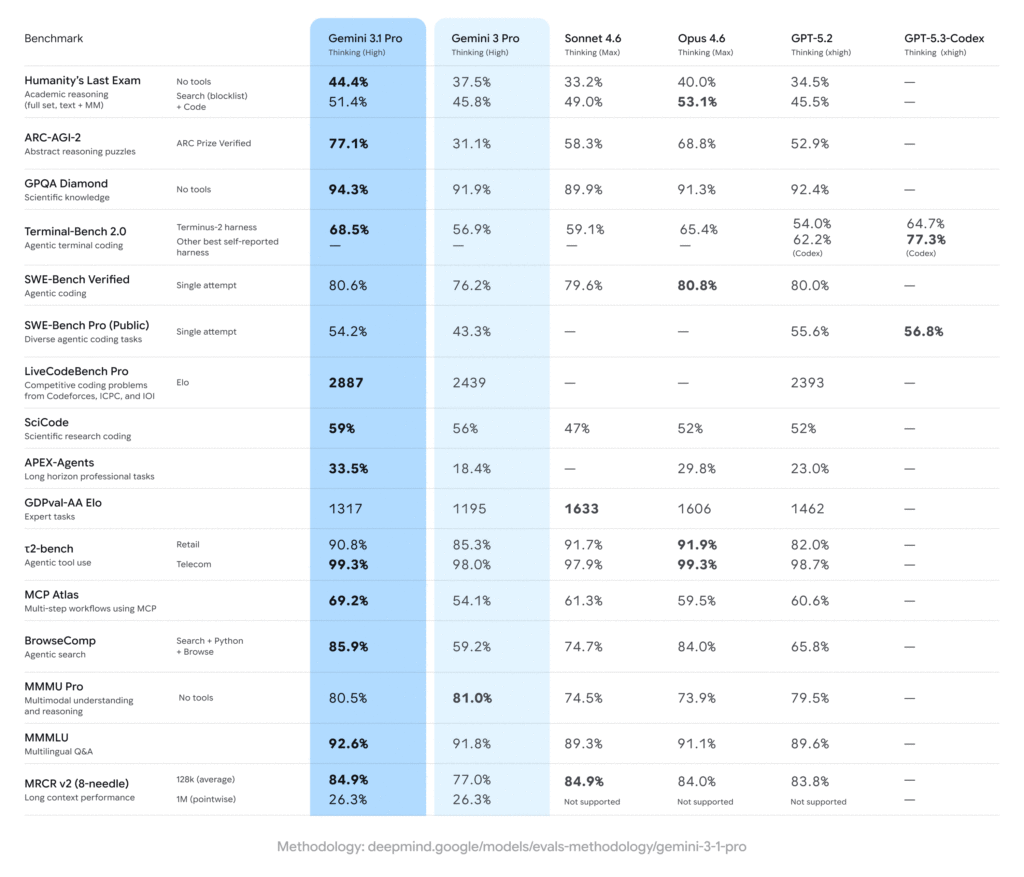
Другие важные показатели также впечатляют: GPQA Diamond (экспертные научные знания) 94.3%, SWE-Bench Verified (автоматическая исправление кода) 80.6%, Humanity’s Last Exam 44.4%, MMMLU 92.6%.
В стандарте MCP Atlas (оценка рабочих процессов с использованием многошаговых инструментов) 3.1 Pro достигла 69.2%, опередив Claude и GPT-5.2 почти на 10 процентных пунктов.
«Настраиваемое рассуждение»: позволяя разработчикам самим выбирать уровень интеллекта модели
Ключевая новая функция Gemini 3.1 Pro — система трех уровней глубины мышления (thinking level). Разработчики могут переключать «бюджет рассуждения» между low, medium и high, чтобы экономить задержки и ресурсы при простых API-запросах или использовать высокий уровень при сложных задачах и отладке.
При выборе high поведение 3.1 Pro приближается к специализированной модели Google Gemini Deep Think, которая представляет собой «мини-версию» этой системы. Журнал VentureBeat описал это как «Deep Think Mini, активируемый по мере необходимости».
В стандарте BrowseComp (оценка способности ИИ-агента самостоятельно искать информацию в интернете) 3.1 Pro вырос с 59.2% до 85.9%. Такой агент, который может самостоятельно искать данные, выполнять многошаговые задачи и значительно повышать точность рассуждений — именно тот вектор, на который делают ставку все индустриальные игроки.
Цены без изменений, эффективность удвоена: кто субсидирует эту гонку?
Цены на API остались на уровне 2 долларов за миллион входных токенов и 12 долларов за миллион выходных токенов, полностью совпадая с Gemini 3 Pro. В пересчете, Gemini 3.1 Pro стоит на 60% дешевле Claude Opus 4.6 по стоимости входных данных и на 52% по стоимости вывода.
Эффективность удвоилась, цена осталась прежней — Google использует стратегию «ценообразовательного давления», чтобы захватить рынок разработчиков.
Объем контекстного окна остается 1 миллион токенов (в 5 раз больше Claude и в 2.5 раза больше GPT-5), лимит вывода увеличен до 65 000 токенов, а лимит загрузки API — с 20MB до 100MB. Также появилась возможность напрямую передавать URL YouTube для «просмотра» видео моделью.
За стратегией «без повышения цен» стоит структурное преимущество Google — собственные TPU-чипы и облачная инфраструктура. Компания показывает, что в гонке вооружений ИИ наличие собственных чипов — это главный барьер входа.
Нет победителя, захватывающего всё, но есть ясная конкурентная структура
Конечно, Gemini 3.1 Pro не является лидером во всех областях.
Claude Sonnet 4.6 (режим Thinking Max) в задачах с длинной памятью (MRCR v2) сравнялся с 3.1 Pro, а в экспертной задаче GDPval-AA Elo значительно опередил (1633 против 1317).
OpenAI GPT-5.3-Codex в задачах программирования на терминале (Terminal-Bench 2.0) лидирует с результатом 77.3%, опережая 3.1 Pro с 68.5%. Уровень галлюцинаций у серии Claude (около 3%) заметно ниже, чем у Gemini и GPT (в среднем около 6%).
На 2026 год структура AI-гонки такова: Google лидирует в рассуждениях и задачах-агентах, Anthropic — в точности и безопасности, OpenAI — в генерации кода и экосистеме. Победитель, скорее всего, не будет захватывать всё, а «каждые три месяца будет происходить перетасовка».
Гонка вооружений в области ИИ не остановится. Единственный вопрос — кому в итоге достанутся все выгоды: разработчикам, платформам или тем, кто готов платить больше всего.
Сегодня Google отвечает: сначала сделать так, чтобы разработчики могли позволить себе использовать, а остальное — потом. Этот подход уже сработал в эпоху облачных вычислений, и повторит ли он успех в ИИ — зависит от того, сможет ли ИИ действительно приносить бизнесу ценность, оправдывающую затраты, а не только повышать показатели.

Отказ от ответственности: Информация на этой странице может поступать от третьих лиц и не отражает взгляды или мнения Gate. Содержание, представленное на этой странице, предназначено исключительно для справки и не является финансовой, инвестиционной или юридической консультацией. Gate не гарантирует точность или полноту информации и не несет ответственности за любые убытки, возникшие от использования этой информации. Инвестиции в виртуальные активы несут высокие риски и подвержены значительной ценовой волатильности. Вы можете потерять весь инвестированный капитал. Пожалуйста, полностью понимайте соответствующие риски и принимайте разумные решения, исходя из собственного финансового положения и толерантности к риску. Для получения подробностей, пожалуйста, обратитесь к
Отказу от ответственности.