Современные вызовы архитектуры данных блокчейна
Современные стартапы по индексации данных блокчейна сталкиваются с рядом задач, среди которых:
- Колоссальные объемы данных. С увеличением количества данных в блокчейне индекс должен масштабироваться для эффективной обработки нагрузки и обеспечения быстрого доступа. Это приводит к росту расходов на хранение, замедляет вычисление метрик и увеличивает нагрузку на сервер базы данных.
- Сложная цепочка обработки данных. Блокчейн-технология отличается высокой сложностью, а для создания надежного и полного индекса данных требуется глубокое понимание внутренних структур и алгоритмов. Это связано с разнообразием реализаций блокчейнов. Например, NFT в Ethereum обычно создаются в смарт-контрактах по стандартам ERC721 и ERC1155, а в Polkadot их реализация, как правило, встроена в runtime блокчейна. В итоге такие объекты должны определяться и сохраняться как NFT.
- Интеграционные возможности. Для максимальной ценности для пользователей индексация данных блокчейна может потребовать интеграции с другими системами, такими как аналитические платформы или API. Это требует значительных усилий при проектировании архитектуры.
С распространением блокчейн-технологий объем данных в блокчейне существенно вырос. Причина — рост числа пользователей, ведь каждая транзакция добавляет новые данные. Кроме того, сфера применения блокчейна расширилась: от простых переводов, как в случае с биткоином, до сложных решений с бизнес-логикой в смарт-контрактах. Такие контракты генерируют большие объемы данных, что усложняет и увеличивает блокчейн. Со временем это приводит к еще большей сложности и масштабам блокчейна.
В этой статье мы рассмотрим поэтапную эволюцию архитектуры Footprint Analytics, чтобы показать, как стек Iceberg-Trino решает задачи работы с ончейн-данными.
Footprint Analytics индексировал данные 22 публичных блокчейнов, 17 NFT-маркетплейсов, 1900 GameFi-проектов и более 100 000 NFT-коллекций в слой семантической абстракции данных. Это самое комплексное хранилище данных блокчейна в мире.
Блокчейн-данные включают более 20 миллиардов строк записей финансовых транзакций, которые часто запрашиваются аналитиками. Это отличается от логов поступления в традиционных хранилищах данных.
За последние месяцы мы провели три крупных обновления, чтобы соответствовать растущим бизнес-требованиям:
Архитектура 1.0 Bigquery
На старте Footprint Analytics мы использовали Google Bigquery как движок хранения и обработки запросов. Bigquery — высокоэффективный продукт: он очень быстрый, удобный в использовании, поддерживает динамические вычисления и гибкий синтаксис UDF, что позволяет решать задачи максимально оперативно.
Однако у Bigquery есть ряд недостатков.
- Данные не сжимаются, что приводит к высоким затратам на хранение, особенно при необходимости сохранять необработанные данные более 22 блокчейнов, которые индексирует Footprint Analytics.
- Ограниченная параллельность: Bigquery поддерживает только 100 одновременных запросов, что недостаточно для сценариев высокой нагрузки с большим количеством аналитиков и пользователей.
- Привязка к закрытому продукту Google Bigquery.
Поэтому мы решили рассмотреть альтернативные архитектурные решения.
Архитектура 2.0 OLAP
Мы заинтересовались OLAP-решениями, которые стали очень популярны. Главное преимущество OLAP — быстрый отклик на запросы: результаты по большим объемам данных возвращаются за доли секунды, а также поддерживаются тысячи параллельных запросов.
Для тестирования мы выбрали одну из лучших OLAP-баз данных — Doris. Движок показал хорошие результаты, но вскоре появились новые проблемы:
- Типы данных, такие как Array и JSON, не поддерживались (ноябрь 2022 г.). Массивы — стандартный тип данных в ряде блокчейнов, например, поле topic в evm-логах. Отсутствие поддержки массивов напрямую ограничивает вычисление бизнес-метрик.
- Ограниченная поддержка DBT и операторов merge. Это стандартные требования для ETL/ELT-сценариев, где требуется обновлять индексированные данные.
В результате Doris не подошел для всей цепочки обработки данных в продакшене. Мы использовали Doris как OLAP-базу данных для решения части задач, предоставляя быстрый и масштабируемый движок запросов.
Однако заменить Bigquery на Doris полностью не удалось, поэтому мы периодически синхронизировали данные из Bigquery в Doris, используя Doris только как движок запросов. Этот процесс сопровождался рядом проблем: при высокой нагрузке на OLAP-движок запросы на запись накапливались, что замедляло процесс и иногда делало синхронизацию невозможной.
Мы пришли к выводу, что OLAP решает только часть задач, но не может быть универсальным решением для Footprint Analytics, особенно в части обработки данных. Наша задача оказалась сложнее, и OLAP как отдельный движок запросов не был достаточен.
Архитектура 3.0 Iceberg + Trino
В архитектуре Footprint Analytics 3.0 мы полностью обновили базовую структуру. Вся архитектура была переработана: хранение, вычисления и запросы разделены на три независимых компонента. Мы учли опыт предыдущих версий Footprint Analytics и лучшие практики крупных data-проектов — Uber, Netflix, Databricks.
Введение в data lake
Мы сфокусировались на data lake — новом типе хранилища для структурированных и неструктурированных данных. Data lake идеально подходит для хранения ончейн-данных, так как их форматы варьируются от неструктурированных до структурированных, что характерно для Footprint Analytics. Мы рассчитывали, что data lake решит задачу хранения и будет поддерживать ведущие вычислительные движки (Spark, Flink), чтобы интеграция с разными обработчиками была простой по мере развития Footprint Analytics.
Iceberg интегрируется со Spark, Flink, Trino и другими вычислительными движками, позволяя выбирать оптимальный инструмент для каждой задачи. Например:
- Для сложных вычислений используем Spark.
- Для потоковых расчетов в реальном времени — Flink.
- Для простых ETL-задач на SQL — Trino.
Движок запросов
С помощью Iceberg мы решили вопросы хранения и вычислений, после чего перешли к выбору движка запросов. Вариантов было немного, мы рассматривали:
- Trino: SQL Query Engine
- Presto: SQL Query Engine
- Kyuubi: Serverless Spark SQL
Ключевым требованием была совместимость будущего движка запросов с нашей архитектурой.
- Поддержка Bigquery как источника данных
- Поддержка DBT, на котором строится множество метрик
- Интеграция с BI-инструментом Metabase
Мы выбрали Trino, который отлично поддерживает Iceberg, а команда оперативно реагирует на обращения: после обращения баг был исправлен на следующий день и вошел в релиз на следующей неделе. Это был оптимальный выбор для Footprint, где важна скорость внедрения изменений.
Тестирование производительности
Определившись с выбором, мы протестировали связку Trino + Iceberg, чтобы убедиться, что она соответствует нашим требованиям. Результаты превзошли ожидания — запросы выполнялись очень быстро.
Учитывая, что Presto + Hive долгое время считались наименее эффективным вариантом среди OLAP-решений, связка Trino + Iceberg показала себя с лучшей стороны.
Результаты наших тестов:
Кейс 1: объединение больших наборов данных
Таблица 800 ГБ (table1) объединяется с таблицей 50 ГБ (table2), выполняются сложные бизнес-вычисления
Кейс 2: distinct-запрос по большой таблице
Тестовый SQL: select distinct(address) from table group by day

Связка Trino+Iceberg примерно в 3 раза быстрее Doris при одинаковой конфигурации.
Кроме того, Iceberg поддерживает такие форматы, как Parquet, ORC и другие, что позволяет эффективно сжимать и хранить данные. Таблицы в Iceberg занимают около 1/5 места по сравнению с другими хранилищами. Размер таблицы в трех базах данных следующий:

Примечание: приведенные тесты — отдельные примеры из реального продакшена и приведены для справки.
・Результаты обновления
Тесты производительности подтвердили эффективность архитектуры, и на миграцию ушло около двух месяцев. Вот схема архитектуры после обновления.
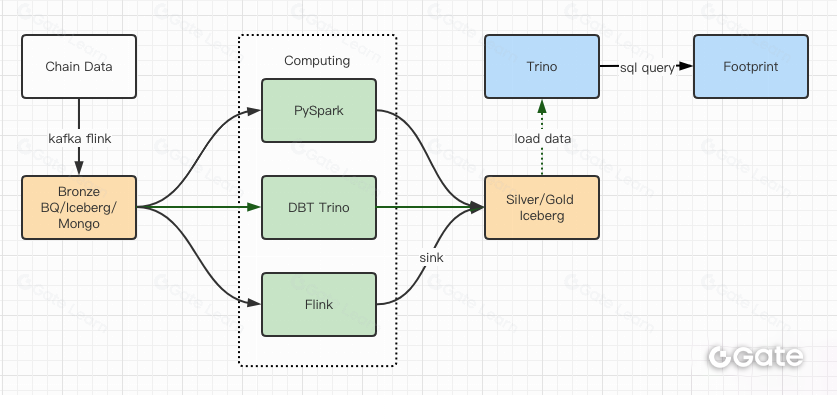
- Несколько вычислительных движков соответствуют нашим разным задачам.
- Trino поддерживает DBT и может напрямую обращаться к Iceberg, поэтому синхронизация данных больше не требуется.
- Высокая производительность Trino + Iceberg позволяет открывать все Bronze-данные (сырые данные) для пользователей.
Итоги
С момента запуска в августе 2021 года команда Footprint Analytics провела три архитектурных обновления менее чем за полтора года — благодаря стремлению внедрять лучшие технологии баз данных для крипто-сообщества и последовательной реализации обновлений инфраструктуры и архитектуры.
Обновление архитектуры Footprint Analytics 3.0 дало пользователям новый опыт и позволило получать инсайты в различных сценариях и областях применения:
- Интеграция с Metabase BI позволяет аналитикам работать с декодированными ончейн-данными, использовать любые инструменты (no-code или hardcode), делать запросы по всей истории, сопоставлять наборы данных и получать инсайты максимально быстро.
- Анализ как ончейн-, так и оффчейн-данных для сценариев web2 + web3;
- Построение и запрос метрик на бизнес-абстракции Footprint позволяет аналитикам и разработчикам экономить до 80% времени на рутинной обработке данных и сосредоточиться на ключевых метриках, исследованиях и продуктовых решениях.
- Бесшовный переход от Footprint Web к REST API, все на базе SQL
- Оповещения и уведомления в реальном времени по ключевым сигналам для поддержки инвестиционных решений





