No momento em que este artigo é publicado, a Amazon Web Services enfrenta uma grande interrupção que volta a afetar a infraestrutura cripto. Desde cerca das 8:00 (hora do Reino Unido) de hoje, uma avaria na região US-EAST-1 da AWS (data centers da Virgínia do Norte) deixou indisponível a Coinbase e dezenas de outras plataformas cripto de referência, como Robinhood, Infura, Base e Solana.
A AWS já reconheceu “taxas de erro aumentadas” nos serviços Amazon DynamoDB e EC2—bases de dados e computação essenciais para milhares de empresas. Esta falha em tempo real valida de forma clara e imediata a tese central deste artigo: a dependência da infraestrutura cripto de provedores cloud centralizados expõe sistematicamente o setor a vulnerabilidades recorrentes em situações de stress.
O momento é elucidativo. Apenas dez dias após a cascata de liquidações de 19,3 mil milhões de dólares ter revelado fragilidades estruturais nas infraestruturas das exchanges, a avaria de hoje na AWS demonstra que o problema transcende plataformas individuais, atingindo a camada fundamental da cloud. Quando a AWS falha, o impacto em cascata afeta simultaneamente exchanges centralizadas, plataformas “descentralizadas” com dependências centrais e inúmeros serviços.
Este não é um caso isolado, mas sim parte de um padrão recorrente. A análise abaixo documenta interrupções semelhantes da AWS em abril de 2025, dezembro de 2021 e março de 2017, todas causadoras de grandes falhas nos serviços cripto. A questão não é se ocorrerá nova falha de infraestrutura, mas quando e qual será o fator de desencadeamento.
Cascata de liquidações de 10-11 de outubro de 2025: Caso de Estudo
A cascata de liquidações de 10-11 de outubro de 2025 constitui um exemplo paradigmático de falha de infraestrutura. Às 20:00 UTC, um anúncio geopolítico de grande impacto gerou vendas em todo o mercado. Em apenas uma hora, registaram-se liquidações no valor de 6 mil milhões de dólares. Quando os mercados asiáticos abriram, 19,3 mil milhões de dólares em posições alavancadas tinham sido eliminados em 1,6 milhão de contas de traders.
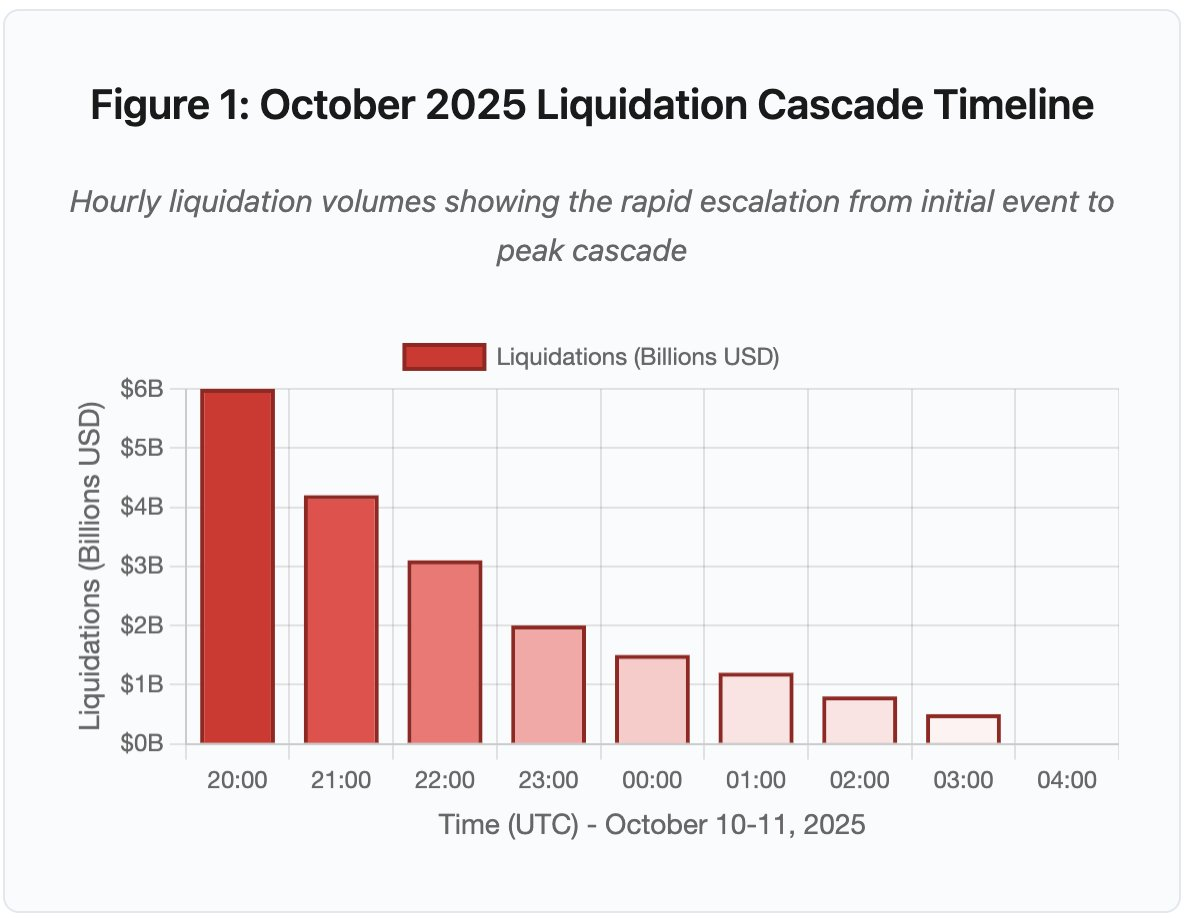
Figura 1: Linha temporal da cascata de liquidações de outubro de 2025
O gráfico interativo mostra a evolução dramática das liquidações hora a hora. Só na primeira hora evaporaram 6 mil milhões de dólares, seguindo-se uma segunda hora ainda mais intensa com aceleração da cascata. A visualização evidencia:
- 20:00-21:00: Choque inicial - 6 mil milhões liquidados (zona vermelha)
- 21:00-22:00: Pico da cascata - 4,2 mil milhões com início do throttling das APIs
- 22:00-04:00: Degradação prolongada - 9,1 mil milhões em mercados de baixa liquidez
- Pontos de inflexão críticos: limitação de taxa nas APIs, retirada dos market makers, redução da profundidade do livro de ordens
A escala do evento supera qualquer precedente no setor cripto por uma ordem de grandeza. A comparação histórica mostra a natureza exponencial deste episódio:
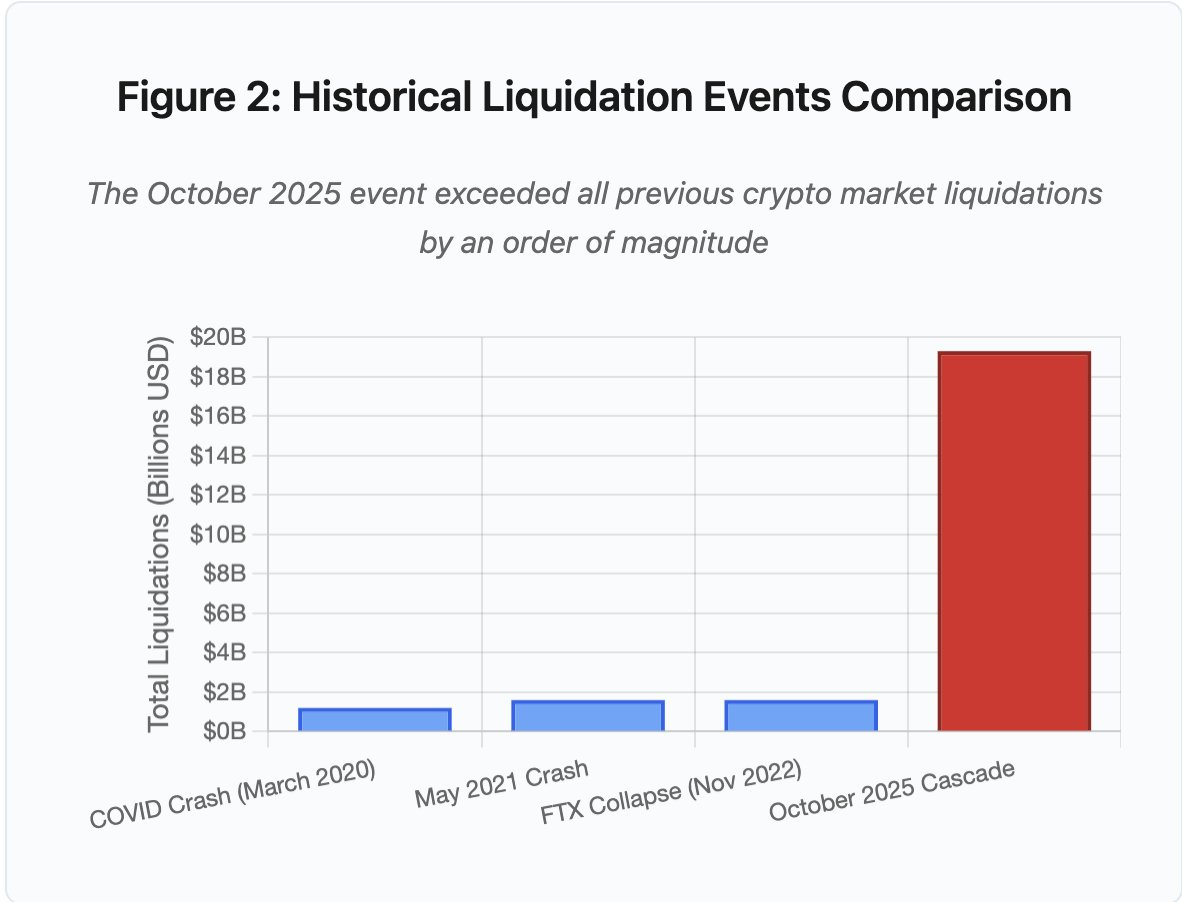
Figura 2: Comparação histórica de eventos de liquidação
O gráfico de barras ilustra de forma inequívoca a excecionalidade de outubro de 2025:
- Março de 2020 (COVID): 1,2 mil milhões
- Maio de 2021 (Crash): 1,6 mil milhões
- Novembro de 2022 (FTX): 1,6 mil milhões
- Outubro de 2025: 19,3 mil milhões ⚠️ 16 vezes superior ao recorde anterior
Os números das liquidações representam apenas parte do fenómeno. O ponto crítico reside no mecanismo: como é que fatores externos desencadearam esta falha específica? A resposta revela fragilidades sistémicas tanto na infraestrutura das exchanges centralizadas como no design dos protocolos blockchain.
Falhas Off-Chain: Arquitetura das Exchanges Centralizadas
Sobrecarga de Infraestrutura e Limitação de Taxa
As APIs das exchanges implementam limites de taxa para prevenir abusos e gerir a carga dos servidores. Em condições normais, estes limites permitem trading legítimo e bloqueiam potenciais ataques. Sob volatilidade extrema, quando milhares de traders tentam simultaneamente ajustar posições, estes limites tornam-se gargalos críticos.
As CEX limitam notificações de liquidação a uma ordem por segundo, mesmo quando processam milhares por segundo. Durante a cascata de outubro, isto gerou opacidade. Os utilizadores não conseguiam avaliar a gravidade da situação em tempo real. Ferramentas externas mostravam centenas de liquidações por minuto, enquanto os feeds oficiais reportavam valores muito inferiores.
Os limites de taxa das APIs impediram traders de modificar posições na hora crítica inicial. Os pedidos de ligação expiravam. Submissões de ordens falhavam. Ordens stop-loss não eram executadas. Consultas devolviam dados desatualizados. Este estrangulamento transformou um evento de mercado numa crise operacional.
As exchanges tradicionais dimensionam a infraestrutura para carga normal e margem de segurança. No entanto, a carga sob stress é exponencialmente superior. O volume médio diário de trading não antecipa picos extremos. Durante cascatas, o volume de transações pode disparar 100 vezes ou mais. Consultas de posição aumentam 1 000 vezes, pois todos os utilizadores verificam simultaneamente as suas contas.
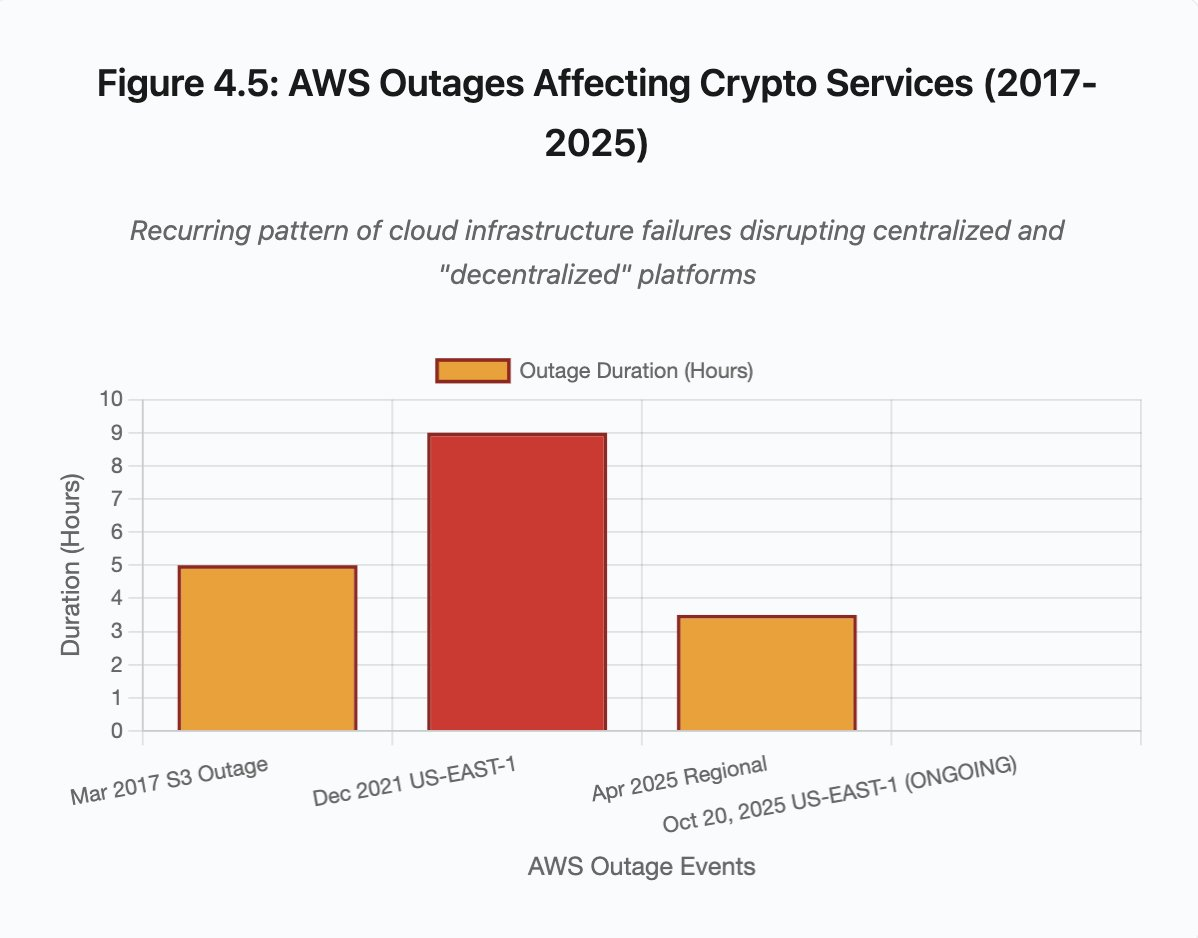
Figura 4.5: Interrupções AWS a afetar serviços cripto
A infraestrutura cloud com auto-escalamento ajuda, mas não responde instantaneamente. Ligar réplicas adicionais de bases de dados leva minutos. Criar novas instâncias de gateways de APIs demora minutos. Durante esse intervalo, os sistemas de margem continuam a marcar posições com dados de preços corrompidos de livros de ordens sobrecarregados.
Manipulação de Oráculos e Vulnerabilidades de Preço
Durante a cascata de outubro, uma decisão crítica nos sistemas de margem tornou-se evidente: algumas exchanges calculavam valores de colateral com base no preço spot interno, em vez de recorrerem a oráculos externos. Em condições normais, arbitradores mantêm o alinhamento de preços entre plataformas. Sob stress, esta ligação quebra-se.
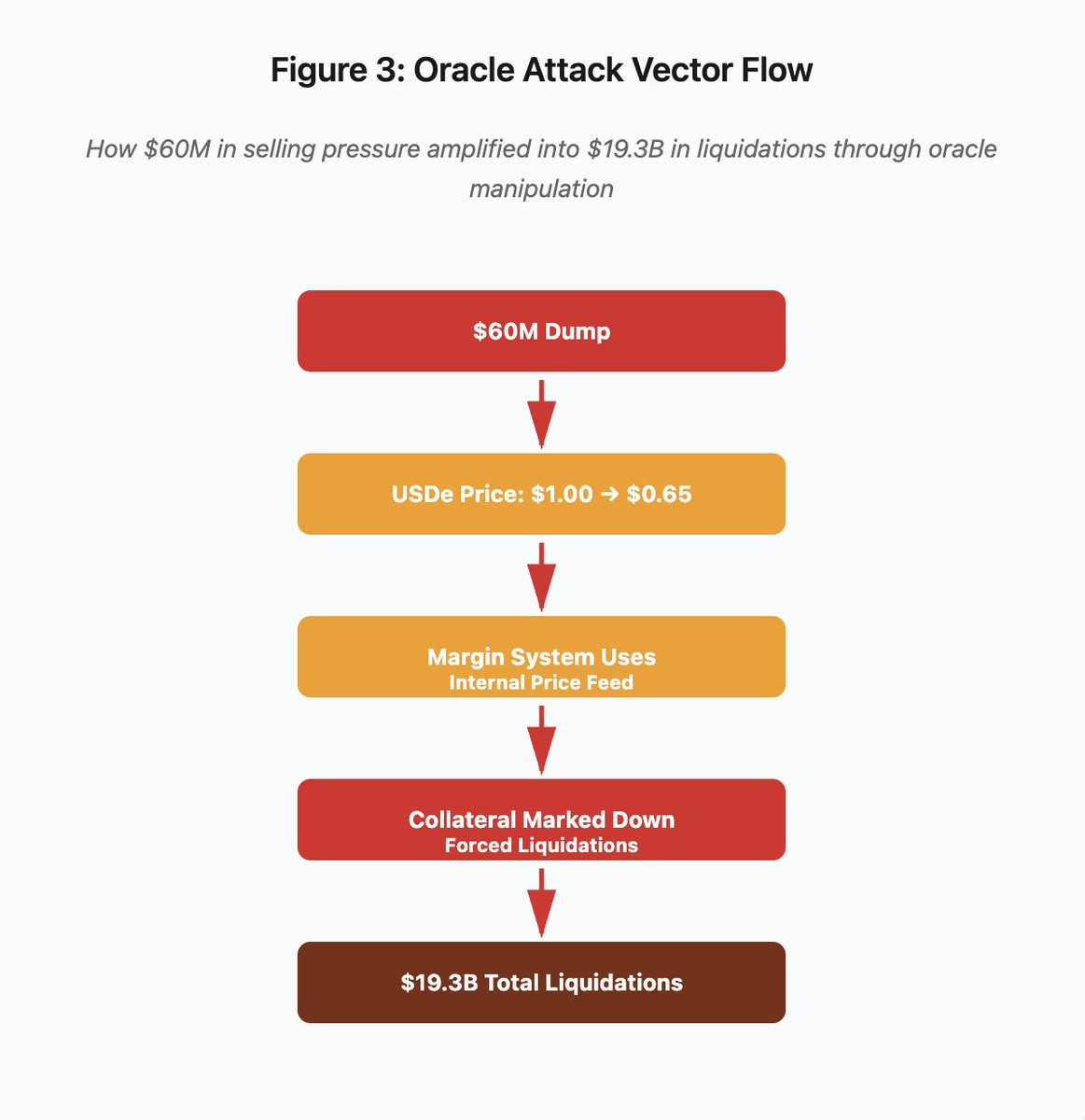
Figura 3: Diagrama de fluxo de manipulação de oráculos
O diagrama interativo apresenta o vetor de ataque em cinco etapas:
- Dump inicial: 60 milhões de pressão vendedora em USDe
- Manipulação de preço: USDe desce de 1,00 → 0,65 numa exchange
- Falha de oráculo: sistema de margem utiliza feed interno corrompido
- Desencadeamento da cascata: colateral marcado em baixa, liquidações forçadas
- Amplificação: 19,3 mil milhões em liquidações (amplificação de 322 vezes)
O ataque explorou o uso pela Binance dos preços spot para colateral sintético wrapped. Ao despejar 60 milhões de USDe em livros de ordens pouco líquidos, o preço spot caiu de 1,00 para 0,65. O sistema de margem, configurado para marcar colateral pelo preço spot, revalorizou todas as posições colateralizadas em USDe em baixa de 35%. Isso gerou chamadas de margem e liquidações forçadas em milhares de contas.
Essas liquidações forçaram vendas adicionais no mesmo mercado ilíquido, pressionando ainda mais os preços. O sistema de margem observava preços mais baixos e marcava mais posições em baixa. O ciclo de feedback transformou 60 milhões de pressão vendedora em 19,3 mil milhões em liquidações forçadas.

Figura 4: Loop de feedback da cascata de liquidação
O diagrama circular evidencia a natureza auto-reforçada da cascata:
Queda de preço → Liquidações → Venda forçada → Nova queda de preço → [ciclo repete-se]
Este mecanismo não funcionaria com um sistema de oráculos robusto. Se a Binance utilizasse médias ponderadas pelo tempo (TWAP) de múltiplas exchanges, a manipulação momentânea não teria impacto sobre as avaliações do colateral. Se utilizasse feeds agregados da Chainlink ou outros oráculos multi-fonte, o ataque falharia.
O incidente com wBETH quatro dias antes demonstrou vulnerabilidade semelhante. O Wrapped Binance ETH (wBETH) deveria manter uma paridade 1:1 com ETH. Durante a cascata, a liquidez secou e o mercado spot wBETH/ETH apresentou um desconto de 20%. O sistema de margem marcou o colateral wBETH em baixa, liquidando posições que estavam totalmente colateralizadas por ETH.
Mecanismos de Auto-Deleveraging (ADL)
Quando liquidações não podem ser executadas ao preço de mercado, as exchanges implementam Auto-Deleveraging para socializar perdas entre traders lucrativos. O ADL encerra forçadamente posições lucrativas ao preço corrente para cobrir o défice das posições liquidadas.
Durante a cascata de outubro, a Binance executou ADL em múltiplos pares. Traders com posições long lucrativas viram as suas operações encerradas, não por falha própria, mas porque outras posições se tornaram insolventes.
O ADL resulta de uma escolha arquitetural fundamental no trading centralizado de derivados. As exchanges garantem que não perdem dinheiro. Assim, as perdas são absorvidas por:
- Fundos de seguro (capital da exchange reservado para liquidações deficitárias)
- ADL (encerramento forçado de traders lucrativos)
- Perda socializada (distribuição das perdas por todos os utilizadores)
A dimensão do fundo de seguro face ao interesse aberto determina a frequência de ADL. O fundo da Binance totalizava cerca de 2 mil milhões em outubro de 2025. Para 4 mil milhões de interesse aberto em futuros perpétuos BTC, ETH e BNB, garante 50% de cobertura. Porém, na cascata de outubro, o interesse aberto ultrapassou os 20 mil milhões em todos os pares. O fundo revelou-se insuficiente.
Após a cascata, a Binance anunciou que garantiria ausência de ADL para contratos BTC, ETH e BNB USDⓈ-M com interesse aberto total abaixo de 4 mil milhões. Isto cria um incentivo: exchanges podem aumentar fundos de seguro para evitar ADL, mas isso imobiliza capital que poderia ser usado de modo mais rentável.
Falhas On-Chain: Limitações dos Protocolos Blockchain
O gráfico de barras compara tempos de inatividade em diferentes incidentes:
- Solana (fev 2024): 5 horas - gargalo no throughput de votos
- Polygon (mar 2024): 11 horas - incompatibilidade de versões de validadores
- Optimism (jun 2024): 2,5 horas - sobrecarga do sequenciador (airdrop)
- Solana (set 2024): 4,5 horas - ataque de spam de transações
- Arbitrum (dez 2024): 1,5 horas - falha de fornecedor RPC
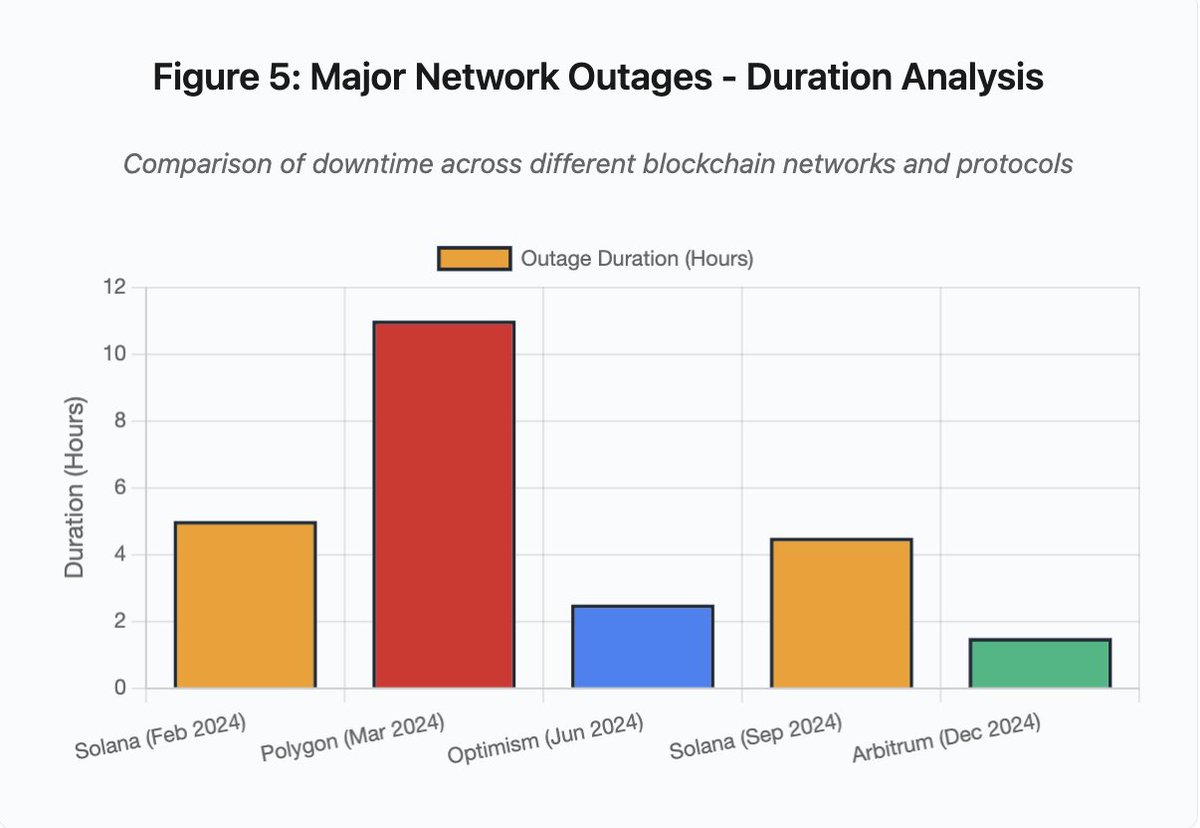
Figura 5: Grandes interrupções de rede - análise da duração
Solana: O Gargalo do Consenso
A Solana registou várias interrupções entre 2024 e 2025. A interrupção de fevereiro de 2024 durou cerca de 5 horas. Em setembro de 2024, registou-se outra interrupção de 4-5 horas. As causas são recorrentes: incapacidade da rede em processar volumes extremos de transações durante ataques de spam ou atividade excecional.
Na Figura 5, as interrupções Solana (5 horas em fev, 4,5 horas em set) evidenciam problemas recorrentes de resiliência sob stress.
A arquitetura Solana privilegia throughput. Em condições ideais, processa 3 000-5 000 transações por segundo com finalização sub-segundo, superando largamente o Ethereum. Contudo, sob stress, esta otimização torna-se vulnerabilidade.
O colapso de setembro de 2024 resultou de um fluxo massivo de transações spam que saturou o mecanismo de votação dos validadores. Os validadores têm de votar em blocos para alcançar consenso. Em condições normais, priorizam transações de voto. O protocolo, porém, tratava estas transações como regulares para efeitos de taxas.
Com o mempool saturado de milhões de transações spam, os validadores não conseguiam propagar votos. Sem votos suficientes, os blocos não eram finalizados e a cadeia parava. Utilizadores com transações pendentes viam-nas bloqueadas. Novas transações falhavam ao submeter.
A StatusGator documentou várias interrupções nos serviços Solana em 2024-2025 não reconhecidas oficialmente. Isto gera assimetria informativa: os utilizadores não distinguem problemas locais de falhas de rede globais. Serviços externos garantem transparência, mas as plataformas deviam manter páginas de estado completas.
Ethereum: Explosão das Taxas de Gas
O Ethereum registou picos extremos nas taxas de gas durante o boom DeFi em 2021. Transações simples ultrapassavam os 100. Interações complexas com smart contracts custavam 500-1 000. Estes valores tornaram a rede impraticável para pequenas operações e abriram espaço à extração de MEV.
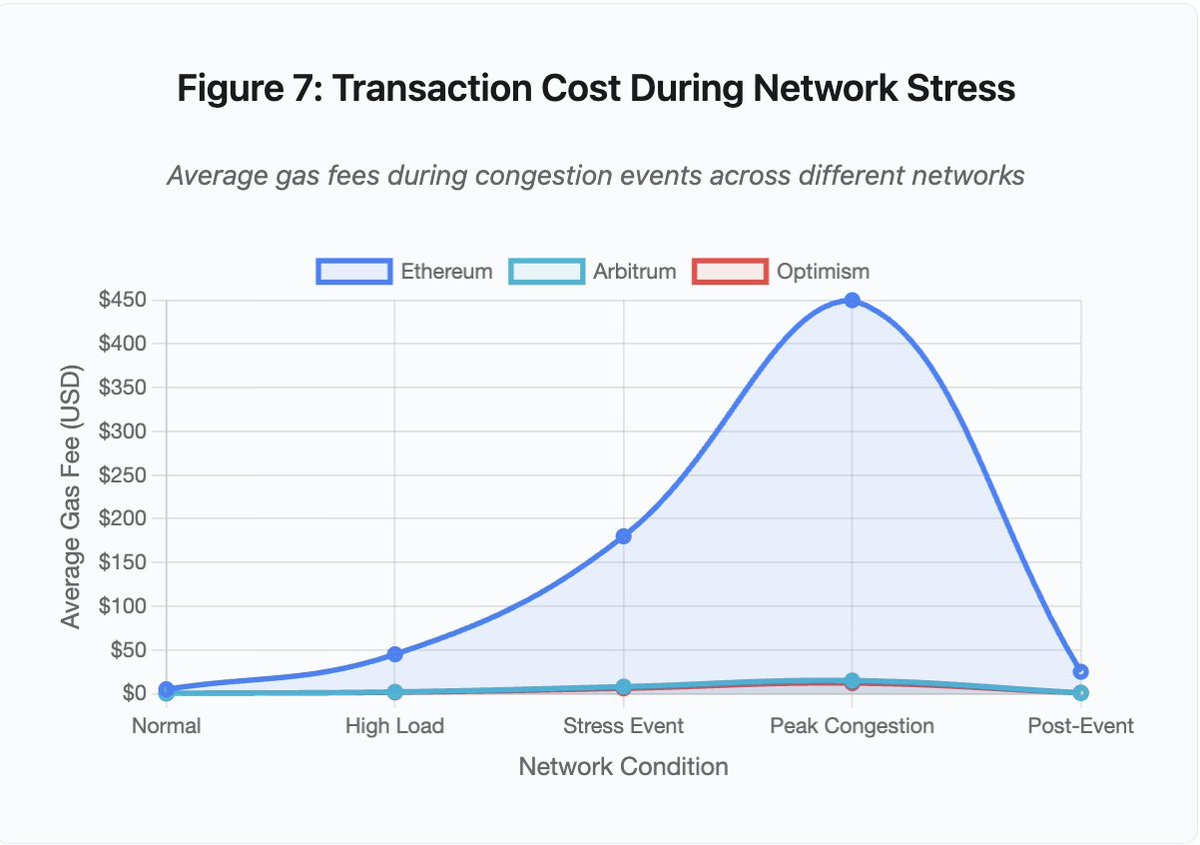
Figura 7: Custos de transação sob stress na rede
O gráfico de linhas ilustra a escalada das taxas de gas sob stress:
- Ethereum: 5 (normal) → 450 (congestionamento máximo) - subida de 90 vezes
- Arbitrum: 0,50 → 15 - subida de 30 vezes
- Optimism: 0,30 → 12 - subida de 40 vezes
A visualização mostra que mesmo Layer 2 sofre aumentos significativos, embora com base inferior.
Maximal Extractable Value (MEV) corresponde ao lucro que validadores extraem ao reorganizar, incluir ou excluir transações. Com taxas elevadas, MEV torna-se especialmente lucrativo. Arbitradores competem para antecipar grandes operações em DEX. Bots de liquidação disputam liquidação de posições subcolateralizadas. Esta competição resulta em guerras de licitação de gas.
Utilizadores que pretendem garantir inclusão de transações em congestionamento têm de superar bots MEV. Por vezes, a taxa supera o valor da operação. Para reclamar um airdrop de 100, paga-se 150 em gas. Para reforçar colateral e evitar liquidação, há que competir com bots que pagam 500 pela prioridade.
O limite de gas do Ethereum restringe a computação por bloco. Em congestionamento, os utilizadores disputam espaço no bloco. O mercado de taxas privilegia ofertas superiores. Este sistema eleva os custos quando o acesso é mais urgente.
Layer 2 tentou solucionar o problema transferindo computação off-chain, herdando a segurança Ethereum por liquidação periódica. Optimism, Arbitrum e outros rollups processam milhares de transações off-chain e submetem provas comprimidas ao Ethereum. O custo por transação reduz-se em operações normais.
Layer 2: O Gargalo do Sequenciador
Soluções Layer 2 criam novos gargalos. Optimism sofreu uma interrupção quando 250 000 endereços reclamaram airdrops em junho de 2024. O sequenciador—responsável por ordenar transações antes de submeter ao Ethereum—ficou sobrecarregado. Os utilizadores não conseguiam submeter transações durante horas.
Esta falha mostra que transferir computação off-chain não elimina requisitos de infraestrutura. Sequenciadores processam, ordenam, executam transações e geram provas para liquidação Ethereum. Sob tráfego extremo, enfrentam desafios idênticos aos blockchains autónomos.
É essencial que existam vários fornecedores RPC funcionais. Se o principal falha, o sistema deve alternar automaticamente. Na falha Optimism, alguns fornecedores mantiveram serviço, outros falharam. Utilizadores cujas wallets dependiam dos fornecedores indisponíveis não conseguiam interagir com a rede, mesmo estando esta operacional.
As falhas AWS evidenciam repetidamente o risco de dependência concentrada no ecossistema cripto:
- 20 de outubro de 2025 (hoje): falha US-EAST-1 afeta Coinbase, Venmo, Robinhood e Chime. AWS reconhece erros em DynamoDB e EC2.
- Abril de 2025: interrupção regional afeta Binance, KuCoin e MEXC. Múltiplas exchanges ficam indisponíveis após falha AWS.
- Dezembro de 2021: falha US-EAST-1 derruba Coinbase, Binance.US e dYdX por 8-9 horas, afetando também armazéns Amazon e serviços de streaming.
- Março de 2017: falha do S3 impede acesso a Coinbase e GDAX por cinco horas e provoca disrupção global na internet.
O padrão é inequívoco: exchanges hospedam componentes críticos na AWS. Quando a AWS sofre falhas regionais, várias exchanges e serviços tornam-se indisponíveis em simultâneo. Os utilizadores ficam sem acesso a fundos, trades ou posições—precisamente quando a volatilidade exige resposta imediata.
Polygon: Incompatibilidade de Versão de Consenso
A Polygon (antiga Matic) registou uma falha de 11 horas em março de 2024. A raiz do problema foi a incompatibilidade de versões de validadores. Alguns corriam software antigo, outros versões atualizadas, e calculavam transições de estado de forma divergente.
Na Figura 5, a interrupção Polygon (11 horas) é a mais longa entre os incidentes analisados, evidenciando o impacto das falhas de consenso.
Quando validadores divergiam sobre o estado correto, o consenso falhava. A cadeia deixava de produzir blocos pois não havia acordo sobre a validade. Isto gerou um impasse: validadores antigos rejeitavam blocos novos e vice-versa.
A resolução exigiu atualizações coordenadas dos validadores. Em redes descentralizadas com centenas de operadores, este processo pode demorar horas ou dias.
Hard forks baseiam-se em triggers por altura de bloco. Todos os validadores atualizam até um bloco específico, garantindo ativação simultânea. Isso exige coordenação prévia. Atualizações incrementais, com adoção gradual de versões, podem gerar precisamente a incompatibilidade que precipitou a falha Polygon.
Compromissos Arquiteturais
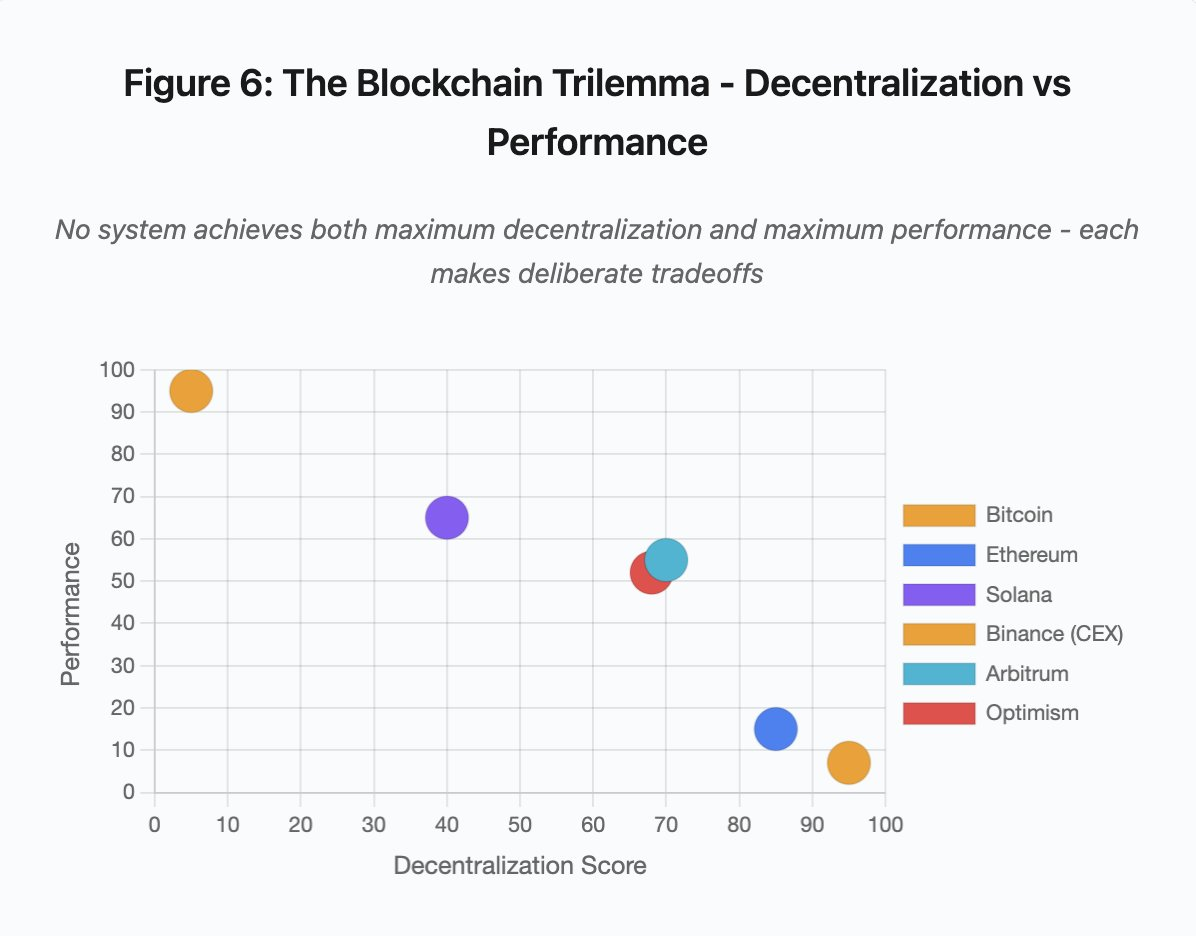
Figura 6: O trilema do blockchain - descentralização vs desempenho
Este gráfico de dispersão posiciona os sistemas em duas dimensões críticas:
- Bitcoin: Elevada descentralização, desempenho reduzido
- Ethereum: Elevada descentralização, desempenho moderado
- Solana: Descentralização média, desempenho elevado
- Binance (CEX): Descentralização mínima, desempenho máximo
- Arbitrum/Optimism: Descentralização média-alta, desempenho médio
Conclusão: Nenhuma solução oferece simultaneamente máxima descentralização e máximo desempenho. Cada arquitetura faz escolhas deliberadas consoante o uso pretendido.
Exchanges centralizadas garantem latência mínima através de simplicidade arquitetural. Motores de matching processam ordens em microssegundos. O estado reside em bases de dados centralizadas. Sem overhead de consenso. Esta simplicidade, contudo, cria pontos únicos de falha. Sob stress, as falhas propagam-se rapidamente em sistemas altamente acoplados.
Protocolos descentralizados distribuem o estado entre validadores, eliminando pontos únicos de falha. Blockchains de elevado throughput mantêm a propriedade durante falhas (fundos não são perdidos, apenas liveness comprometido). O consenso distribuído gera overhead computacional. Validadores devem concordar antes de concluir transições. Se correm versões incompatíveis ou enfrentam tráfego excessivo, os processos de consenso podem ser interrompidos temporariamente.
Adicionar réplicas aumenta a tolerância a falhas, mas eleva custos de coordenação. Cada validador adicional num sistema tolerante a falhas bizantinas implica mais overhead de comunicação. Arquiteturas otimizadas para throughput minimizam o overhead, permitindo desempenho superior mas introduzindo vulnerabilidades específicas. Arquiteturas orientadas para segurança privilegiam diversidade de validadores e robustez de consenso, limitando o throughput mas maximizando a resiliência.
Layer 2 procura unir as duas propriedades com design hierárquico. Herda a segurança Ethereum através de liquidação L1 e garante throughput elevado por computação off-chain. Contudo, introduz novos gargalos no sequenciador e RPC, evidenciando que a complexidade cria novos modos de falha ao mesmo tempo que resolve outros.
A escalabilidade é o problema fundamental
Os incidentes revelam um padrão: os sistemas são dimensionados para carga normal e falham catastroficamente sob stress. Solana lida bem com tráfego rotineiro, mas colapsa com aumento de 10 000% no volume. As taxas de gas Ethereum mantêm-se razoáveis até a adoção DeFi gerar congestionamento. Optimism funciona até 250 000 endereços reclamarem airdrops. APIs Binance funcionam no trading normal, mas bloqueiam sob cascatas de liquidação.
O evento de outubro de 2025 demonstra esta dinâmica ao nível da exchange. Em condições normais, limites de taxa e ligações de base de dados da Binance são suficientes. Sob cascatas de liquidação, quando todos os traders tentam simultaneamente ajustar posições, estes limites tornam-se gargalos. O sistema de margem, desenhado para proteger a exchange por liquidações forçadas, agravou a crise ao criar vendedores forçados no pior momento.
O auto-escalamento não protege contra aumentos abruptos de carga. Ligar servidores adicionais demora minutos. Durante esse tempo, sistemas de margem marcam posições com dados corrompidos de livros de ordens ilíquidos. Quando a nova capacidade entra em funcionamento, a cascata já se propagou.
Dimensionar para eventos raros de stress é caro em operações correntes. Operadores de exchanges otimizam para carga típica, aceitando falhas ocasionais por racionalidade económica. O custo do downtime é transferido para os utilizadores, que enfrentam liquidações, transações bloqueadas ou inacessibilidade de fundos em momentos críticos.
Melhorias de Infraestrutura
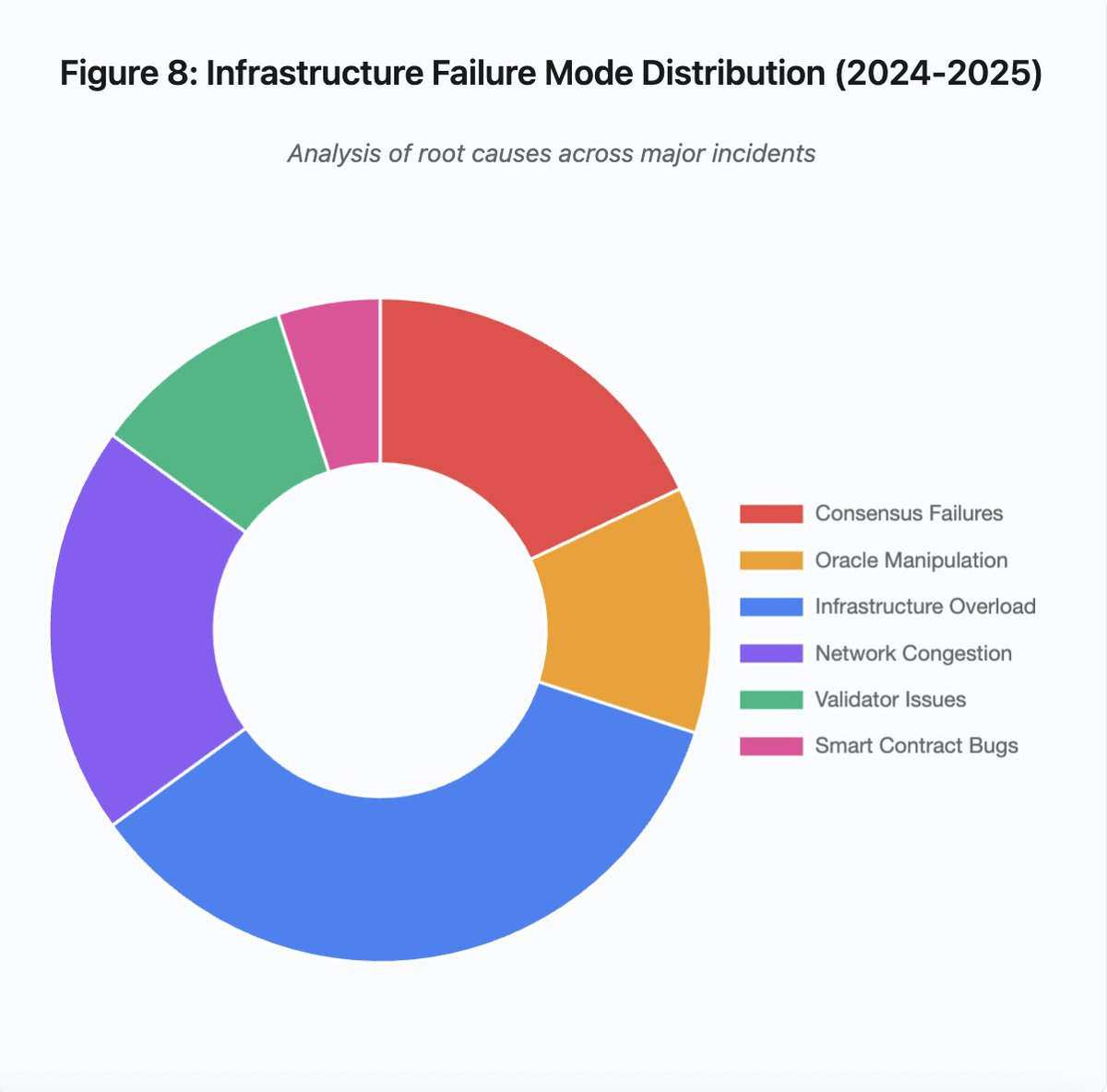
Figura 8: Distribuição dos modos de falha de infraestrutura (2024-2025)
O gráfico de setores revela os fatores principais:
- Sobrecarga de infraestrutura: 35% (maior incidência)
- Congestionamento de rede: 20%
- Falhas de consenso: 18%
- Manipulação de oráculos: 12%
- Problemas de validadores: 10%
- Erros em smart contracts: 5%
Mudanças arquiteturais podem mitigar frequência e gravidade das falhas, mas cada solução implica compromissos:
1. Separação entre sistemas de preço e liquidação
O problema de outubro resultou em parte da dependência do cálculo de margens nos preços spot. Utilizar rácios de conversão para ativos wrapped, em vez de preços spot, teria evitado a má avaliação do wBETH. Sistemas críticos de gestão de risco não devem depender de dados manipuláveis. Oráculos independentes, com agregação multi-fonte e cálculo TWAP, garantem feeds de preço robustos.
2. Dimensionamento excessivo e infraestrutura redundante
A falha AWS de abril de 2025, que afetou Binance, KuCoin e MEXC, evidencia o risco de dependências concentradas. Executar componentes críticos em vários provedores cloud aumenta a complexidade e custo, mas elimina falhas correlacionadas. Layer 2 pode manter vários fornecedores RPC com failover automático. O custo adicional parece excessivo em operações normais, mas evita downtime prolongado em picos de procura.
3. Testes de stress e planeamento de capacidade reforçados
Os sistemas que funcionam até falharem sugerem falta de testes de stress. Simular 100 vezes a carga normal devia ser prática padrão. Identificar gargalos em desenvolvimento é mais económico do que em falhas reais. Testes realistas continuam um desafio: padrões de tráfego real e comportamento de utilizadores diferem em situações reais versus simulações.
O Futuro
Dimensionar excessivamente é a solução mais fiável, mas entra em conflito com incentivos económicos. Manter excesso de capacidade para eventos raros implica custos diários para evitar falhas anuais. Até que falhas catastróficas justifiquem o investimento, os sistemas continuarão vulneráveis sob stress.
A pressão regulatória pode forçar mudanças. Se regulamentos exigirem 99,9% de uptime ou limitarem o downtime, exchanges terão de dimensionar em excesso. Regulamentos normalmente surgem após desastres, não para os prevenir. O colapso Mt. Gox em 2014 levou o Japão a regulamentar exchanges cripto. A cascata de outubro de 2025 deverá gerar respostas regulatórias semelhantes. Resta saber se essas medidas definirão resultados (downtime máximo, slippage em liquidações) ou implementações (oráculos, thresholds de circuit breaker).
O desafio reside no facto de estes sistemas operarem continuamente em mercados globais, mas dependerem de infraestrutura desenhada para horários comerciais tradicionais. Quando o stress surge às 02:00, equipas correm para corrigir enquanto utilizadores acumulam perdas. Mercados tradicionais suspendem trading sob stress; mercados cripto entram em colapso. Se isto é uma feature ou um bug depende da perspetiva.
Os sistemas blockchain atingiram um nível técnico notável em poucos anos. Manter consenso distribuído entre milhares de nós é um feito de engenharia. Para garantir fiabilidade sob stress, é preciso evoluir para infraestrutura de produção robusta, priorizando estabilidade em detrimento da velocidade de lançamento de funcionalidades.
O desafio é priorizar robustez em bull markets, quando todos lucram e o downtime parece alheio. Quando o próximo ciclo testar o sistema, novas fragilidades surgirão. Se o setor aprende com outubro de 2025 ou repete padrões, é uma incógnita. A história sugere que a próxima vulnerabilidade será descoberta numa nova falha multibilionária sob stress.
Análise baseada em dados públicos de mercado e declarações de plataformas. As opiniões aqui expressas são exclusivamente do autor e não representam nenhuma entidade.
Aviso Legal:
- Este artigo é republicado de [yq_acc]. Todos os direitos de autor pertencem ao autor original [yq_acc]. Para qualquer objeção a esta republicação, contacte a equipa Gate Learn, que tratará do assunto prontamente.
- Renúncia de responsabilidade: As opiniões e pontos de vista expressos neste artigo são exclusivamente do autor e não constituem aconselhamento de investimento.
- As traduções do artigo para outros idiomas são feitas pela equipa Gate Learn. Salvo indicação em contrário, é proibida a cópia, distribuição ou plágio dos artigos traduzidos.








