Les enjeux de la data stack blockchain moderne
Une startup spécialisée dans l’indexation de la blockchain moderne doit relever plusieurs défis majeurs, parmi lesquels :
- Des volumes de données considérables. À mesure que les données sur la blockchain augmentent, l’index doit évoluer pour absorber cette charge croissante et garantir un accès efficace. Cela entraîne une hausse des coûts de stockage, ralentit le calcul des métriques et accentue la sollicitation du serveur de base de données.
- Un pipeline de traitement de données complexe. La technologie blockchain présente une grande complexité, et la création d’un index de données fiable et exhaustif exige une compréhension pointue des structures et algorithmes sous-jacents. Cette complexité découle de la diversité des implémentations blockchain. Par exemple, sur Ethereum, les NFTs sont généralement créés via des smart contracts respectant les formats ERC721 et ERC1155, tandis que sur Polkadot, ils sont souvent intégrés directement dans le runtime de la blockchain. Au final, ces actifs doivent être considérés et stockés comme des NFTs.
- Des capacités d’intégration. Pour maximiser la valeur offerte aux utilisateurs, une solution d’indexation blockchain doit pouvoir intégrer son index à d’autres systèmes, comme des plateformes d’analyse ou des API. Cela représente un défi qui requiert un effort conséquent dans la conception architecturale.
Avec la démocratisation de la blockchain, le volume de données stockées sur les réseaux n’a cessé d’augmenter. Cela résulte de l’adoption croissante de la technologie, chaque transaction générant de nouvelles données. Par ailleurs, la blockchain a évolué, passant d’applications de simple transfert de fonds (comme Bitcoin) à des usages complexes intégrant de la logique métier dans les smart contracts. Ces derniers peuvent générer d’importants volumes de données, ce qui accroît la complexité et la taille des blockchains. Progressivement, les blockchains sont devenues plus volumineuses et sophistiquées.
Dans cet article, nous retraçons l’évolution de l’architecture technique de Footprint Analytics, étape par étape, pour illustrer comment la stack Iceberg-Trino répond aux défis des données on-chain.
Footprint Analytics a indexé près de 22 blockchains publiques, 17 marketplaces NFT, 1 900 projets GameFi et plus de 100 000 collections NFT dans une couche d’abstraction sémantique des données. Il s’agit de la solution d’entrepôt de données blockchain la plus complète au monde.
Les données blockchain, qui comprennent plus de 20 milliards de lignes de transactions financières fréquemment consultées par les data analysts, se distinguent fondamentalement des logs d’ingestion des entrepôts de données traditionnels.
Nous avons mené trois grandes évolutions de notre architecture ces derniers mois pour répondre à la croissance de nos besoins métiers :
Architecture 1.0 Bigquery
Au lancement de Footprint Analytics, nous avons utilisé Google Bigquery comme moteur de stockage et de requête. Bigquery est un excellent produit : il offre une rapidité remarquable, une grande simplicité d’utilisation, une puissance de calcul dynamique et une syntaxe UDF flexible qui nous ont permis de traiter rapidement nos besoins.
Cependant, Bigquery présente aussi plusieurs limites.
- Les données ne sont pas compressées, ce qui génère des coûts de stockage élevés, notamment pour les données brutes de plus de 22 blockchains indexées par Footprint Analytics.
- Concurrence limitée : Bigquery ne gère que 100 requêtes simultanées, ce qui est insuffisant pour Footprint Analytics dans des contextes de forte sollicitation par de nombreux analysts et utilisateurs.
- Dépendance à Google Bigquery, un produit propriétaire et fermé.
Nous avons donc décidé d’explorer d’autres architectures alternatives.
Architecture 2.0 OLAP
Nous nous sommes tournés vers les solutions OLAP, très en vogue. Leur principal atout est un temps de réponse quasi instantané, même sur de très grands volumes de données, tout en supportant des milliers de requêtes en simultané.
Nous avons sélectionné Doris, l’une des meilleures bases de données OLAP, pour la tester. Ce moteur s’est révélé performant. Toutefois, nous avons été rapidement confrontés à d’autres difficultés :
- Les types de données comme Array ou JSON n’étaient pas encore pris en charge (novembre 2022). Or, les Arrays sont fréquents dans certaines blockchains, par exemple le champ topic dans les logs EVM. L’impossibilité de traiter ces Arrays limite notre capacité à calculer de nombreux indicateurs métiers.
- Prise en charge limitée de DBT et des instructions merge, pourtant essentielles pour les data engineers dans les scénarios ETL/ELT où il s’agit de mettre à jour de nouvelles données indexées.
Dès lors, il n’était pas possible d’utiliser Doris pour l’ensemble de notre pipeline de données en production. Nous l’avons donc cantonné à un rôle de base OLAP, résolvant une partie des problématiques dans la chaîne de production, en tant que moteur de requête rapide et hautement concurrent.
Malheureusement, Doris n’a pas pu remplacer Bigquery : nous avons dû synchroniser régulièrement les données de Bigquery vers Doris, utilisé uniquement comme moteur de requête. Ce processus de synchronisation a posé plusieurs difficultés, notamment des accumulations d’écritures lors des pics d’utilisation de Doris par les clients front-end, ce qui ralentissait les traitements et pouvait rendre la synchronisation impossible à terminer.
Nous avons réalisé qu’OLAP pouvait résoudre certains de nos problèmes, mais ne pouvait constituer la solution clé-en-main pour Footprint Analytics, en particulier pour le pipeline de traitement de données. Notre problématique était plus vaste et complexe : un moteur OLAP seul ne suffisait pas.
Architecture 3.0 Iceberg + Trino
Bienvenue dans l’architecture 3.0 de Footprint Analytics, une refonte totale de notre socle technique. Nous avons repensé l’architecture pour dissocier stockage, calcul et requête en trois couches distinctes, tirant les leçons de nos précédentes architectures et de l’expérience de grands acteurs du big data tels qu’Uber, Netflix ou Databricks.
Introduction au data lake
Nous avons d’abord orienté notre réflexion vers le data lake, une nouvelle forme de stockage adaptée aux données structurées comme non structurées. Le data lake est idéal pour les données on-chain, dont les formats varient de données brutes non structurées à des abstractions structurées, spécialité reconnue de Footprint Analytics. Notre objectif était de résoudre les enjeux de stockage, tout en assurant la compatibilité avec les moteurs de calcul majeurs comme Spark ou Flink, pour faciliter les intégrations futures au fil de l’évolution de Footprint Analytics.
Iceberg s’intègre parfaitement avec Spark, Flink, Trino et d’autres moteurs de calcul, ce qui nous permet de choisir la solution la plus adaptée à chaque métrique. Par exemple :
- Spark pour les calculs complexes,
- Flink pour le temps réel,
- Trino pour les tâches ETL simples réalisables en SQL.
Moteur de requête
Avec Iceberg, les questions de stockage et de calcul étaient résolues. Restait à choisir le moteur de requête. Les options étaient limitées ; nous avons envisagé :
- Trino : moteur SQL,
- Presto : moteur SQL,
- Kyuubi : Spark SQL serverless.
L’exigence principale était la compatibilité avec notre architecture existante :
- Prise en charge de Bigquery comme source,
- Support de DBT, essentiel pour la production de nombreuses métriques,
- Compatibilité avec l’outil BI Metabase.
Nous avons donc choisi Trino, qui offre un excellent support d’Iceberg et dont l’équipe s’est montrée extrêmement réactive : un bug que nous avons signalé a été corrigé le lendemain et intégré à la version suivante la semaine d’après. C’était le choix idéal pour l’équipe Footprint, qui exige une grande réactivité d’implémentation.
Tests de performance
Après avoir défini notre orientation, nous avons testé les performances de la combinaison Trino + Iceberg pour vérifier qu’elle répondait à nos besoins. À notre grande surprise, les requêtes se sont révélées extrêmement rapides.
Alors que Presto + Hive était historiquement le moins performant des moteurs OLAP, la combinaison Trino + Iceberg nous a bluffés.
Voici les résultats de nos tests :
Cas 1 : jointure de grands ensembles de données
Table de 800 Go (table1) jointe à une autre de 50 Go (table2), avec calculs métier complexes
Cas 2 : requête distinct sur une grande table
SQL de test : select distinct(address) from table group by day

La combinaison Trino + Iceberg est environ trois fois plus rapide que Doris dans une configuration identique.
Autre point notable : Iceberg permet l’utilisation de formats comme Parquet ou ORC, qui compressent et stockent les données. Le stockage d’une table Iceberg occupe environ 1/5 de l’espace requis par les autres entrepôts de données. Comparatif de la taille de stockage pour une même table dans les trois bases :

Remarque : Les résultats ci-dessus sont issus de cas réels en production et sont donnés à titre indicatif uniquement.
・Effets de la migration
Les résultats de performance nous ont convaincus : la migration a duré environ deux mois. Voici le schéma de notre architecture après la mise à niveau.
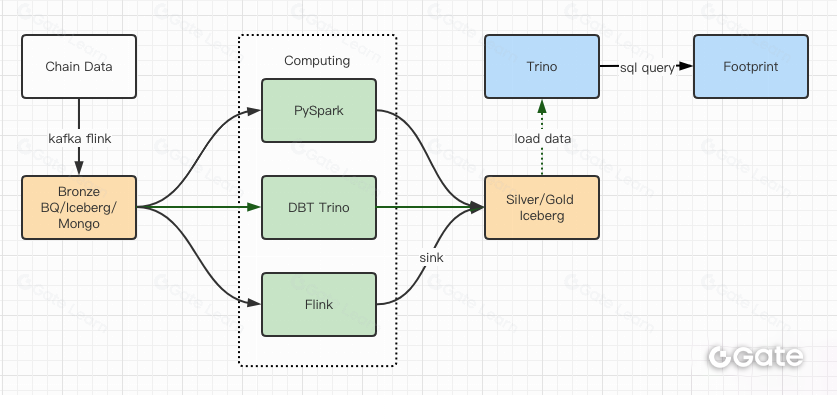
- Plusieurs moteurs de calcul répondent à nos différents besoins.
- Trino prend en charge DBT, interroge directement Iceberg, ce qui élimine les problématiques de synchronisation des données.
- Les performances exceptionnelles de Trino + Iceberg nous permettent d’ouvrir l’ensemble des données Bronze (raw data) à nos utilisateurs.
Synthèse
Depuis son lancement en août 2021, l’équipe Footprint Analytics a mené trois évolutions architecturales majeures en moins d’un an et demi, portée par sa volonté de faire bénéficier ses utilisateurs crypto des meilleures technologies de bases de données, et par sa capacité à exécuter et moderniser son infrastructure.
La migration Footprint Analytics architecture 3.0 a apporté une expérience renouvelée, permettant à des profils variés d’obtenir des insights pour des usages et applications diversifiés :
- Grâce à l’intégration de Metabase, Footprint donne aux analysts un accès direct aux données on-chain décodées, leur permettant d’explorer librement avec l’outil de leur choix (no-code ou code), d’interroger l’historique complet, de croiser les datasets et d’obtenir des insights instantanés.
- Analyse croisée de données on-chain et off-chain pour le web2 + web3 ;
- En construisant ou interrogeant des métriques sur la couche d’abstraction métier de Footprint, analysts ou développeurs économisent 80 % du travail répétitif de traitement de données et se concentrent sur les indicateurs pertinents, la recherche et les solutions produits adaptées à leur activité.
- Expérience fluide du web Footprint jusqu’aux appels REST API, entièrement basée sur SQL
- Alertes en temps réel et notifications exploitables sur les signaux clés pour accompagner les décisions d’investissement






