PhyrexNi
現在、コンテンツはありません
😂X の中国語圏はますます + 小红书 のようになっている
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
The activity around USD1 recently has been non-stop, with another month-long extension. I'm not sure if it's due to a structural bill being passed, or if it's been stimulated by $CRCL . USD1 continues to gain user support through subsidies. In this situation, being able to earn stable returns with interest rates higher than financial management products is already quite good.
USD10.03%

- 報酬
- 1
- コメント
- リポスト
- 共有
米国銀行のアナリストは、ビットコインは過売りセクターにあると指摘しています。マイケル・ハーテネット氏は、S&P 500がさらに約6600ポイントまで下落した場合、ホワイトハウスやFRBの政策対応が引き金となる可能性があると警告しています。ハーテネット氏は、油価の急騰、イラン戦争の長期化、そして世界的な不安定性を引き金として挙げています。また、金、半導体、欧州株などの資産はすでに過熱状態にある一方、ソフトウェア、銀行融資、ビットコインなどの過売りセクターは、政策立案者の介入後に安定する可能性があると指摘しています。潜在的な介入策には、関税の緩和、紛争のエスカレーション抑止、またはFRBによる利下げや資産買い入れなどの刺激策が含まれます。
BTC0.04%
- 報酬
- 2
- コメント
- リポスト
- 共有
最近の2日間で、Xに投稿された画像がドラッグできなくなったことに気づきました。おそらくXは長文を通常の投稿ではあまり使いたがらず、長文はすべて記事に移行させたいのだと思います。でも、記事の最大の問題は、記事同士を引用できないことです。これを改善してもらえればと思います。
原文表示- 報酬
- 1
- コメント
- リポスト
- 共有
先ほど、イスラエルがテヘランの主要空港に攻撃を仕掛けたのを見ました。目撃者によると、1機の旅客機も攻撃を受けたとのことです。戦争が民間人に被害をもたらすのは非難されるべきですが、イランがドバイ空港を攻撃したときには報復攻撃があることを覚悟すべきでした。今日、トランプも公に、イランは今後、以前の3倍の攻撃を受けるだろうと述べました。世界の平和を願います。私は戦争を受け身で支援したくありません。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
トランプ:我々は基本的にイラン海軍司令部を破壊し、米軍は9隻のイラン海軍艦艇を撃沈したと述べており、現在残存しているイラン海軍の艦隊を追跡している。
原文表示- 報酬
- 2
- コメント
- リポスト
- 共有
イスラエルは、イランの最高指導者ハメネイが死亡したと称し、その遺体が見つかった。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
希望迪拜とアブダビの皆さんが無事でありますように。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
イスラエル🇮🇱がイラン🇮🇷に対して予防的攻撃を実施
この攻撃は@PhyrexNiによる非自主的な後援です
原文表示この攻撃は@PhyrexNiによる非自主的な後援です
- 報酬
- いいね
- コメント
- リポスト
- 共有
😂今日は疲れ果てて書き疲れました。もともとXのルールに従ってこれを投稿すると損をすることになります。短期的に多くの長文を投稿すると、重みや推薦が下がるからです。でも私にとって重要なのは、Xのルールがどれだけ収入をもたらすかではなく、必要なときに必要なことができるかどうかです。オンチェーンデータの解釈をやめたら、自然拡散量が最大になるかもしれませんが、多くの仲間たちが生活環境を変える研究をしているのを見ると、皆さんが気づいていないかもしれないことについて話したいと思います。明日にしても問題ありませんが、明日もまた書くべきことがあると思います。$CRCL の財務報告を見て、明日まで待って書くこともできますが、明日書き終えるタイミングと今は全く異なります。今日は12時間しっかり書き続けて、中間に一度だけ食事をしました。とても疲れましたが、達成感もあります。もちろん、多くの仲間たちは私の書いた内容が臭くて長いと感じるかもしれません。でも気にしないでください。私が書いた内容はマクロからデータ、生活から生存まで幅広くカバーしています。もしかしたら将来的にあなたに合うかもしれません。詳細に書くことで、必要な仲間たちが一度に問題を解決できるようにしたいだけです。それで私は満足です。コンテンツ制作は枠にとらわれるべきではありません。自分が正しいと思うことをやることで、心も体も喜びを感じます。たとえ
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
川普の平和委員会はガザ向けのステーブルコイン発行を検討中
Financial Times の報道によると、川普陣営が推進する「平和委員会」は、ガザにドル連動のステーブルコインを導入することを議論しており、その用途はガザコインの代替や新しいパレスチナ通貨になることではなく、銀行システムや現金流が損なわれている状況でのデジタル決済や電子金融ツールとしての役割を果たすことにあります。同時に、ハマスによる実体現金流への接触を減らすことも目的としています。
もちろん、これはまだ初期段階の議論であり、このアイデアの推進はイスラエルのテクノロジー企業家であり、元予備役軍人のリラン・タンクマンが主導しています。彼は現在、川普平和委員会の無給顧問として働いており、この委員会はアメリカ主導のガザ再建を担当しています。
タンクマンは先週ワシントンで開催された平和委員会の会議で、NCAGが安全なデジタル基幹ネットワークを構築していると述べました。これは電子決済、金融サービス、電子学習、医療をサポートするオープンプラットフォームであり、ユーザーがデータをコントロールできるようにするものですが、詳細については明らかにされていません。
@ VIP、レートが低く、福利厚生が充実
原文表示Financial Times の報道によると、川普陣営が推進する「平和委員会」は、ガザにドル連動のステーブルコインを導入することを議論しており、その用途はガザコインの代替や新しいパレスチナ通貨になることではなく、銀行システムや現金流が損なわれている状況でのデジタル決済や電子金融ツールとしての役割を果たすことにあります。同時に、ハマスによる実体現金流への接触を減らすことも目的としています。
もちろん、これはまだ初期段階の議論であり、このアイデアの推進はイスラエルのテクノロジー企業家であり、元予備役軍人のリラン・タンクマンが主導しています。彼は現在、川普平和委員会の無給顧問として働いており、この委員会はアメリカ主導のガザ再建を担当しています。
タンクマンは先週ワシントンで開催された平和委員会の会議で、NCAGが安全なデジタル基幹ネットワークを構築していると述べました。これは電子決済、金融サービス、電子学習、医療をサポートするオープンプラットフォームであり、ユーザーがデータをコントロールできるようにするものですが、詳細については明らかにされていません。
@ VIP、レートが低く、福利厚生が充実
- 報酬
- いいね
- コメント
- リポスト
- 共有
解読 SEC 安定コイン割引率緩和 — — これは好材料か、それとも悪材料か?
本日、SEC 取引・市場部門はよくある質問を更新し、規制の「支払い型安定コイン」の計算において、2%の割引率で処理できることを明示(スタッフは反対しない)。これに対し、SEC委員のHester Peirceは声明を出し、安定コインが規制資本計測において、ほぼ使えない資産から、より低リスクの現金類似ツールに近づき始めていることを示した。
1. 割引率とは何か?
割引率とは、規制が資産のリスクを評価するための価格付けである。
証券会社の破綻を防ぐため、規制は一定の純資本を保有することを求めている。これらの資本を計算する際、保有資産は市場価格の100%で計算されず、割引を適用しなければならない。
従来、安定コインの100%割引率は、規制当局が安定コインのリスクを非常に高いとみなしており、その価値をゼロと見なしていたことを意味した。例えば、証券会社が100万ドルの安定コインを保有している場合、規制を維持するために、100万ドルのコイン購入に加え、追加で100万ドルの現金を「保証金」として準備する必要があった。
しかし、今や2%の割引率に変更されたことで、規制当局は安定コインを非常に安全な資産とみなしており、その価値は98%と評価される。これは貨幣市場ファンド(MMF)の扱いと同じだ。100万ドルの安定コインを保
本日、SEC 取引・市場部門はよくある質問を更新し、規制の「支払い型安定コイン」の計算において、2%の割引率で処理できることを明示(スタッフは反対しない)。これに対し、SEC委員のHester Peirceは声明を出し、安定コインが規制資本計測において、ほぼ使えない資産から、より低リスクの現金類似ツールに近づき始めていることを示した。
1. 割引率とは何か?
割引率とは、規制が資産のリスクを評価するための価格付けである。
証券会社の破綻を防ぐため、規制は一定の純資本を保有することを求めている。これらの資本を計算する際、保有資産は市場価格の100%で計算されず、割引を適用しなければならない。
従来、安定コインの100%割引率は、規制当局が安定コインのリスクを非常に高いとみなしており、その価値をゼロと見なしていたことを意味した。例えば、証券会社が100万ドルの安定コインを保有している場合、規制を維持するために、100万ドルのコイン購入に加え、追加で100万ドルの現金を「保証金」として準備する必要があった。
しかし、今や2%の割引率に変更されたことで、規制当局は安定コインを非常に安全な資産とみなしており、その価値は98%と評価される。これは貨幣市場ファンド(MMF)の扱いと同じだ。100万ドルの安定コインを保
USD10.03%
- 報酬
- いいね
- コメント
- リポスト
- 共有
私はトランプがKalshiを使っていると推測しています。もともと、「アメリカは2027年前に宇宙人の存在を公表しないだろう」という確率の低い予測を見て、あり得ないと思っていました。たとえアメリカに証拠があったとしても、今すぐ公表する可能性は低いと考えていましたが、今朝トランプが直接このような動きを見せるとは思いませんでした。現在、Kalshi上の確率は大幅に上昇しています。
原文表示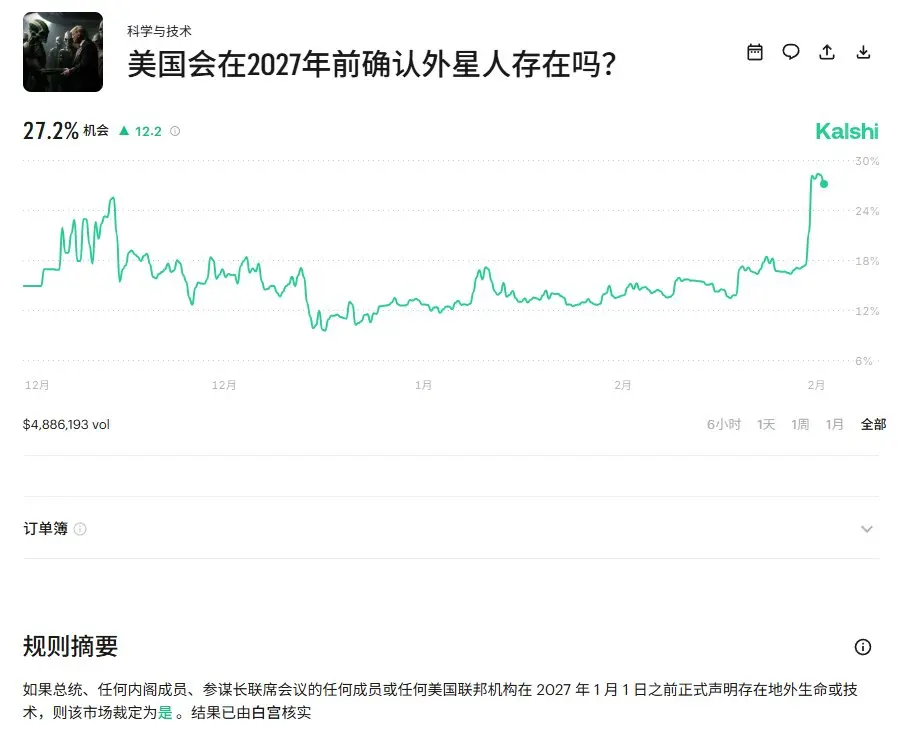
- 報酬
- 1
- コメント
- リポスト
- 共有
CMEは2026年5月29日に7×24時間の暗号通貨先物およびオプション取引を開始します
CMEグループは本日、規制された暗号資産先物およびオプション取引が規制審査後、5月29日から週7日、毎日24時間の取引を実現すると発表しました。
「デジタル資産市場におけるリスク管理の需要は史上最高水準にあり、2025年の暗号通貨先物およびオプションの名目取引高は3兆ドルを超えました」と、CMEグループのグローバル株式・外国為替・オルタナティブ商品責任者のTim McCourtは述べています。
「すべての市場が24/7運用に適しているわけではありませんが、規制された透明性の高い暗号資産商品へのいつでもアクセスできることは、顧客がいつでもエクスポージャーを管理し、自信を持って取引できることを保証します。」
5月29日金曜日の中部時間午後4時から、CMEグループの暗号通貨先物およびオプションはCME Globex上で継続的に取引され、週末には少なくとも2時間のメンテナンス時間が確保されます。
金曜日の夜から日曜日の夜までのすべての祝日や週末の取引日は次の営業日となり、決済、引き渡し、規制報告も次の営業日に処理されます。
原文表示CMEグループは本日、規制された暗号資産先物およびオプション取引が規制審査後、5月29日から週7日、毎日24時間の取引を実現すると発表しました。
「デジタル資産市場におけるリスク管理の需要は史上最高水準にあり、2025年の暗号通貨先物およびオプションの名目取引高は3兆ドルを超えました」と、CMEグループのグローバル株式・外国為替・オルタナティブ商品責任者のTim McCourtは述べています。
「すべての市場が24/7運用に適しているわけではありませんが、規制された透明性の高い暗号資産商品へのいつでもアクセスできることは、顧客がいつでもエクスポージャーを管理し、自信を持って取引できることを保証します。」
5月29日金曜日の中部時間午後4時から、CMEグループの暗号通貨先物およびオプションはCME Globex上で継続的に取引され、週末には少なくとも2時間のメンテナンス時間が確保されます。
金曜日の夜から日曜日の夜までのすべての祝日や週末の取引日は次の営業日となり、決済、引き渡し、規制報告も次の営業日に処理されます。
- 報酬
- 2
- コメント
- リポスト
- 共有
米国とイランの戦争リスクが高まっています。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有