DegenSing
Web3 Degen | 通貨分析 & トレーディングインサイト | #メモコイントレーダー
DegenSing
実際に私の構築方法を変えたツール:
コーディング用:→ cursor。
もう文法をググる必要はない → claude。話すラバーダック → copilot。
自動補完で考える → perplexity。
調査用:→ notebookLM。
Googleだけど読むだけ → notebookLM。
何でも質問、何も忘れない
原文表示コーディング用:→ cursor。
もう文法をググる必要はない → claude。話すラバーダック → copilot。
自動補完で考える → perplexity。
調査用:→ notebookLM。
Googleだけど読むだけ → notebookLM。
何でも質問、何も忘れない
- 報酬
- いいね
- コメント
- リポスト
- 共有
六ヶ月前、私はおそらく週に一度の投稿をしていました。
アイデアがなかったわけではありません。アイデアを読む価値のあるものに変えるのに永遠にかかっていたからです。
下書き。削除。夜11時に真っ白な画面を見つめながら、これ全体が意味をなしているのか疑問に思う。
それから私はAIを使い始めて、自分の考えを整理するのに役立てました。
私のために書くのではなく。自分の邪魔を取り除くために。
その違いは即座に現れました。
今では週に四回投稿しています。投稿は私らしく聞こえます。アイデアはより鋭くなっています。考えることに時間を使っているからです。フォーマットに時間を取られていません。
ソロの創業者には編集者がいません。コンテンツチームもありません。
AIはあなたの声を置き換えるのではありません。大きなチームがすでに持っていたインフラをあなたに提供しているのです。
原文表示アイデアがなかったわけではありません。アイデアを読む価値のあるものに変えるのに永遠にかかっていたからです。
下書き。削除。夜11時に真っ白な画面を見つめながら、これ全体が意味をなしているのか疑問に思う。
それから私はAIを使い始めて、自分の考えを整理するのに役立てました。
私のために書くのではなく。自分の邪魔を取り除くために。
その違いは即座に現れました。
今では週に四回投稿しています。投稿は私らしく聞こえます。アイデアはより鋭くなっています。考えることに時間を使っているからです。フォーマットに時間を取られていません。
ソロの創業者には編集者がいません。コンテンツチームもありません。
AIはあなたの声を置き換えるのではありません。大きなチームがすでに持っていたインフラをあなたに提供しているのです。
- 報酬
- いいね
- コメント
- リポスト
- 共有
実際に私の構築方法を変えたツール:
コーディング用:
→ cursor。
もう文法をググる必要なし
→ claude。
話すラバーダック
→ copilot。
考えるオートコンプリート
リサーチ用:
→ perplexity。
Googleだけど読むだけ
→ notebookLM。
何でも質問、何も忘れない
デリバリー用:
→ vercel。
3分で展開完了
→ supabase。
苦労のないバックエンド
→ expo。
一つのコードベース、二つのプラットフォーム
これらは私を賢くしなかった。
ただ、作らない言い訳をすべて取り除いただけ。
原文表示コーディング用:
→ cursor。
もう文法をググる必要なし
→ claude。
話すラバーダック
→ copilot。
考えるオートコンプリート
リサーチ用:
→ perplexity。
Googleだけど読むだけ
→ notebookLM。
何でも質問、何も忘れない
デリバリー用:
→ vercel。
3分で展開完了
→ supabase。
苦労のないバックエンド
→ expo。
一つのコードベース、二つのプラットフォーム
これらは私を賢くしなかった。
ただ、作らない言い訳をすべて取り除いただけ。
- 報酬
- いいね
- コメント
- リポスト
- 共有
ほとんどのAIツールはあなたが書く内容を分析します。
VoiceMoat (@voicemoat) はあなたの考え方を分析します。
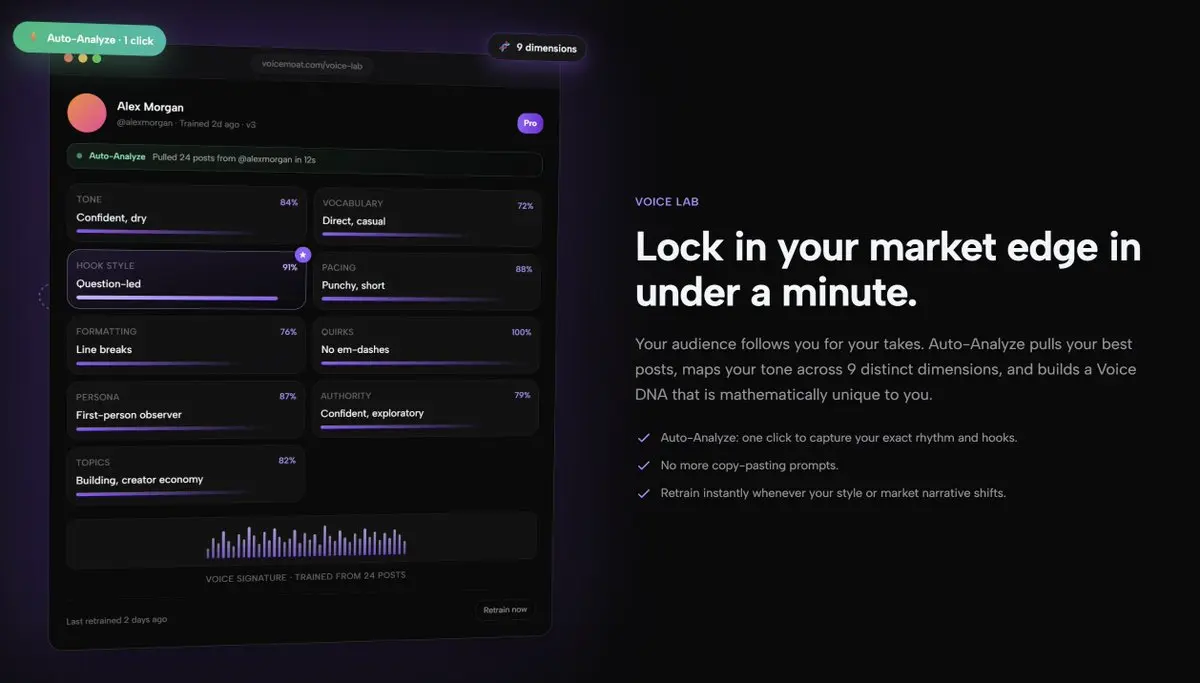
あなたの実際の投稿からマッピングされた9つの次元:
- プレッシャーを感じたときにデフォルトで使う言葉
- 思考を切り出す前にどれだけ長く考えさせるか
- 主張を最初に開示するか、それとも埋めるか
- 興奮しているときに現れるフックと、ただ投稿しているときのフック
あなたの文章には指紋があります。ほとんどのツールはそれを無視します。
#BuildInPublic #IndieHackers #BuildWithAI
原文表示VoiceMoat (@voicemoat) はあなたの考え方を分析します。
あなたの実際の投稿からマッピングされた9つの次元:
- プレッシャーを感じたときにデフォルトで使う言葉
- 思考を切り出す前にどれだけ長く考えさせるか
- 主張を最初に開示するか、それとも埋めるか
- 興奮しているときに現れるフックと、ただ投稿しているときのフック
あなたの文章には指紋があります。ほとんどのツールはそれを無視します。
#BuildInPublic #IndieHackers #BuildWithAI
- 報酬
- いいね
- コメント
- リポスト
- 共有
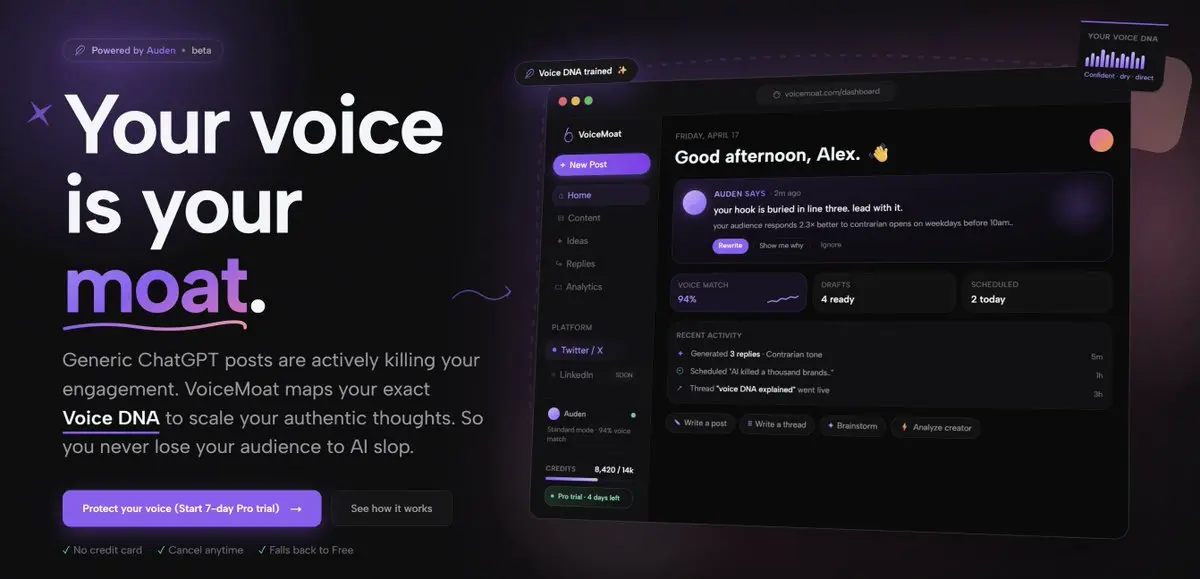
あなたの声は誰もコピーできない唯一のものです。
それを一般的なプロンプトに委託した瞬間、実際に価値を増す唯一の優位性を手放したことになります。
あなたの声はあなたの堀です。
チャットボットにそれを埋めさせないでください。
#BuildInPublic #IndieHackers #BuildWithAI
原文表示それを一般的なプロンプトに委託した瞬間、実際に価値を増す唯一の優位性を手放したことになります。
あなたの声はあなたの堀です。
チャットボットにそれを埋めさせないでください。
#BuildInPublic #IndieHackers #BuildWithAI
- 報酬
- いいね
- コメント
- リポスト
- 共有
危険な部分は怠惰さではない。
それは、聴衆がAIのような投稿を、どんなアルゴリズムよりも早くスキップするように自分たちを訓練していることだ。
あなたの声はかつて彼らにスクロールを止めさせるものでした。
今ではそれは後回しになりつつある。
原文表示それは、聴衆がAIのような投稿を、どんなアルゴリズムよりも早くスキップするように自分たちを訓練していることだ。
あなたの声はかつて彼らにスクロールを止めさせるものでした。
今ではそれは後回しになりつつある。
- 報酬
- いいね
- コメント
- リポスト
- 共有
今やCTの皆は皆同じように聞こえる.. それは彼らが同じ考えを持っているからではなく。 皆同じAIを使っているからだ。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
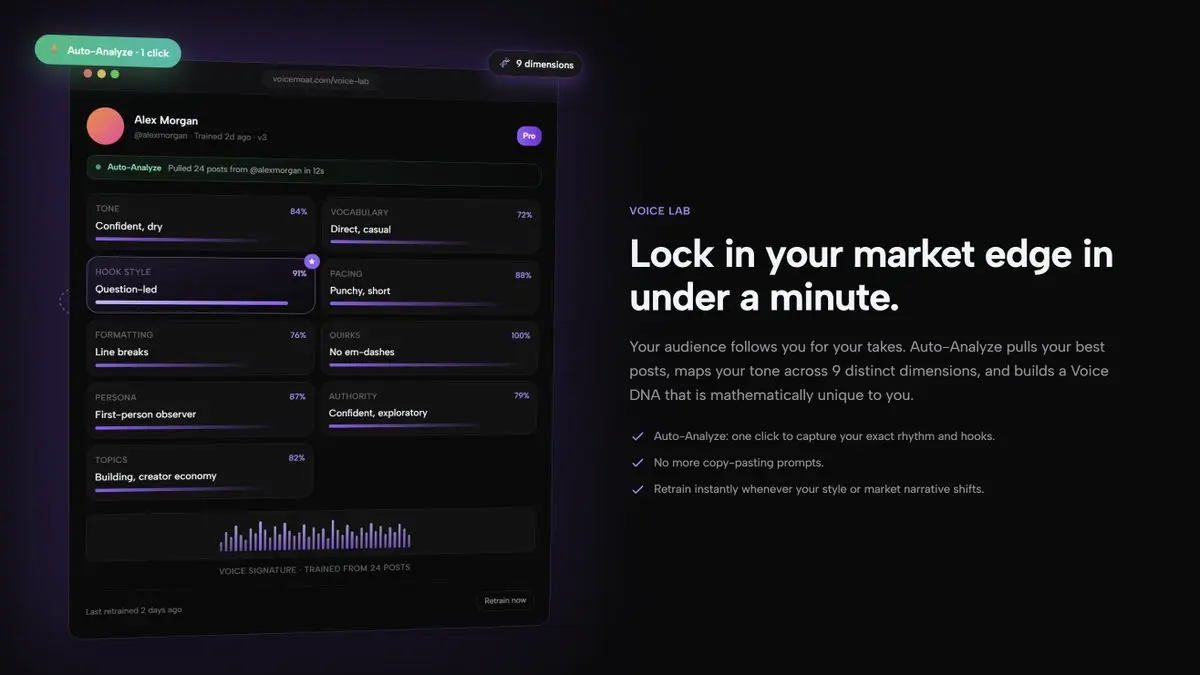
ほとんどのAIツールはすべてのクリエイターの文章を同じように扱います。
VoiceMoat (@voicemoat) はあなたの最新の投稿を抽出し、それらを9つの次元—トーン、フック、語彙、リズム、フォーマット、個性—にマッピングし、あなた専用のVoice DNAを作り上げます。
ワンクリック。手動設定は不要です。
これが私のものです。
7日間無料トライアル、クレジットカード不要 →
#BuildInPublic #IndieHackers #BuildWithAI
原文表示VoiceMoat (@voicemoat) はあなたの最新の投稿を抽出し、それらを9つの次元—トーン、フック、語彙、リズム、フォーマット、個性—にマッピングし、あなた専用のVoice DNAを作り上げます。
ワンクリック。手動設定は不要です。
これが私のものです。
7日間無料トライアル、クレジットカード不要 →
#BuildInPublic #IndieHackers #BuildWithAI
- 報酬
- いいね
- コメント
- リポスト
- 共有
あなたの声は誰もコピーできない唯一のものです。
それを一般的なプロンプトに外注した瞬間、実際に積み重ねてきた唯一の優位性を手放したことになります。
あなたの声はあなたの堀です。チャットボットに埋めさせないでください。
#BuildInPublic #IndieHackers #BuildWithAI
原文表示それを一般的なプロンプトに外注した瞬間、実際に積み重ねてきた唯一の優位性を手放したことになります。
あなたの声はあなたの堀です。チャットボットに埋めさせないでください。
#BuildInPublic #IndieHackers #BuildWithAI
- 報酬
- いいね
- コメント
- リポスト
- 共有
危険な部分は怠惰さではない。
それは、聴衆がAIのように聞こえる投稿を、どんなアルゴリズムよりも早くスキップするように自分たちを訓練していることだ。
あなたの声はかつて彼らにスクロールを止めさせるものでした。
今ではそれは後回しになりつつある。
原文表示それは、聴衆がAIのように聞こえる投稿を、どんなアルゴリズムよりも早くスキップするように自分たちを訓練していることだ。
あなたの声はかつて彼らにスクロールを止めさせるものでした。
今ではそれは後回しになりつつある。
- 報酬
- いいね
- コメント
- リポスト
- 共有
今やCTの皆は皆同じように聞こえる..
同じ考えを持っているからではなく。
皆同じAIを使っているからだ。
原文表示同じ考えを持っているからではなく。
皆同じAIを使っているからだ。
- 報酬
- いいね
- コメント
- リポスト
- 共有
プロダクトハントの成功とプロダクトの品質は直交している。
片方を操作してもう片方を操作しないことができる。
そして誰もがそれを知っている。
本当の質問は、あなたのプロダクトが良いかどうかではない。
それがPHアルゴリズムにとって良いかどうかだ。
初日にトレンド入りすることは:
- 事前に温められたオーディエンスが準備できていることを意味する
原文表示片方を操作してもう片方を操作しないことができる。
そして誰もがそれを知っている。
本当の質問は、あなたのプロダクトが良いかどうかではない。
それがPHアルゴリズムにとって良いかどうかだ。
初日にトレンド入りすることは:
- 事前に温められたオーディエンスが準備できていることを意味する
- 報酬
- いいね
- コメント
- リポスト
- 共有
Product huntの成功と製品の品質は直交している。
一方をゲームにすればもう一方は得られない。
そして誰もがそれを知っている。
本当の質問は、あなたの製品が良いかどうかではない。
それがPhのアルゴリズムにとって良いものかどうかだ。
初日にトレンド入りすることは次のことを意味する:
- 事前に温められた観客がアップボート準備完了
- 人々の好奇心を引くフック
- アルゴリズムの勢いのあるタイミングを捉えるタイミング
これらはすべて、6ヶ月続く製品を必要としない。
これまでに作られた最高の製品の中には、Phでトレンド入りしなかったものもあるし、最悪のものが1位になったこともある。
だから、あなたが実際にプレイしているゲームを選びなさい。
もしPhのバリデーションを望むなら、それが製品のバリデーションと同じだと偽るのをやめなさい。
本物を作りたいなら、リーダーボードの更新をやめなさい。
原文表示一方をゲームにすればもう一方は得られない。
そして誰もがそれを知っている。
本当の質問は、あなたの製品が良いかどうかではない。
それがPhのアルゴリズムにとって良いものかどうかだ。
初日にトレンド入りすることは次のことを意味する:
- 事前に温められた観客がアップボート準備完了
- 人々の好奇心を引くフック
- アルゴリズムの勢いのあるタイミングを捉えるタイミング
これらはすべて、6ヶ月続く製品を必要としない。
これまでに作られた最高の製品の中には、Phでトレンド入りしなかったものもあるし、最悪のものが1位になったこともある。
だから、あなたが実際にプレイしているゲームを選びなさい。
もしPhのバリデーションを望むなら、それが製品のバリデーションと同じだと偽るのをやめなさい。
本物を作りたいなら、リーダーボードの更新をやめなさい。
- 報酬
- いいね
- コメント
- リポスト
- 共有
ほとんどの人が貯蓄を築かない理由は収入ではありません。
障壁です。
「今月いくら貯めるべきか?」という質問は、一貫して答えが得られることはありません。
@SaveX_Aiを使ってから、その質問を完全に排除しています。
すべての購入が自動的に端数を切り上げます。余ったお金はリスクレベルに合わせた暗号通貨戦略に自動的に振り分けられます。手作業は一切不要です。
出て行くのを感じることはありませんが、蓄積されていきます。
これは正直、2026年における受動的な資産形成の理想的な方法です。
市場のタイミングを計るのではなく、大きな動きをするのでもなく、ただ一貫したマイクロ積立を自動運転で行うだけです。
ぜひチェックしてください 👇
原文表示障壁です。
「今月いくら貯めるべきか?」という質問は、一貫して答えが得られることはありません。
@SaveX_Aiを使ってから、その質問を完全に排除しています。
すべての購入が自動的に端数を切り上げます。余ったお金はリスクレベルに合わせた暗号通貨戦略に自動的に振り分けられます。手作業は一切不要です。
出て行くのを感じることはありませんが、蓄積されていきます。
これは正直、2026年における受動的な資産形成の理想的な方法です。
市場のタイミングを計るのではなく、大きな動きをするのでもなく、ただ一貫したマイクロ積立を自動運転で行うだけです。
ぜひチェックしてください 👇

- 報酬
- いいね
- コメント
- リポスト
- 共有
今のところ二つのタイプの人々:
グループ1:
「AIに取って代わられる」
「すべてが飽和状態」
「今始めるには遅すぎる」
「チャンスを逃した」
グループ2:
誰も教えなかった学習ツール
実際にものを作っている
他の人がパニックになっている間にAIスキルを積み重ねている
静かに次の10年に向けて準備している
一つのグループは未来についてツイートしている。
もう一つは深夜2時に月額20ドルのサブスクリプションとクリアな頭でそれを築いている。
この二つのグループの間の差は才能ではない…アクセスさえも違わない…ただ決断のスピードの違いだ。
6ヶ月後、同じグループ1の人々はグループ2を見て「彼らは運が良かった」と言うだろう。
いや、彼らはただ始めただけだ、あなたが始めるかどうか迷っている間に。
原文表示グループ1:
「AIに取って代わられる」
「すべてが飽和状態」
「今始めるには遅すぎる」
「チャンスを逃した」
グループ2:
誰も教えなかった学習ツール
実際にものを作っている
他の人がパニックになっている間にAIスキルを積み重ねている
静かに次の10年に向けて準備している
一つのグループは未来についてツイートしている。
もう一つは深夜2時に月額20ドルのサブスクリプションとクリアな頭でそれを築いている。
この二つのグループの間の差は才能ではない…アクセスさえも違わない…ただ決断のスピードの違いだ。
6ヶ月後、同じグループ1の人々はグループ2を見て「彼らは運が良かった」と言うだろう。
いや、彼らはただ始めただけだ、あなたが始めるかどうか迷っている間に。
- 報酬
- いいね
- コメント
- リポスト
- 共有
彼らは私にプレイブックはシンプルだと言った。
構築。ローンチ。成長。
実際に起こったことはこうだ:
構築 → 「これ本当に良いのか」
ローンチ → シーンなし
シーンなし → 「もしかして間違ったものを作ったのか」
小さな反応 → 「まあ、多分違う」
さらなる疑念 → 「ちょっと待って、何をしているんだ」
ゆっくりとした成長 → ああ。
期待と現実の間のギャップは失敗ではない。
それはただ、誰も投稿しない部分だ。
原文表示構築。ローンチ。成長。
実際に起こったことはこうだ:
構築 → 「これ本当に良いのか」
ローンチ → シーンなし
シーンなし → 「もしかして間違ったものを作ったのか」
小さな反応 → 「まあ、多分違う」
さらなる疑念 → 「ちょっと待って、何をしているんだ」
ゆっくりとした成長 → ああ。
期待と現実の間のギャップは失敗ではない。
それはただ、誰も投稿しない部分だ。
- 報酬
- いいね
- コメント
- リポスト
- 共有
唯一の出口は、逆のことをするものを作ることだった。あなたの声を置き換えるAIではなく、それを守るAIだ。だから私は、クリエイターの声を9つの次元にわたってマッピングし始めた:リズム、語彙、フック、構造、そして人々が正直になろうとするときに手に取る言葉。
原文表示- 報酬
- いいね
- コメント
- リポスト
- 共有
今日は正式に開始します。7日間の無料トライアル。事前にカードは不要です。
あなたのコンテンツがAIのノイズに溶け込んでいるのを静かに見てきたなら、これがその脱出方法です。
原文表示あなたのコンテンツがAIのノイズに溶け込んでいるのを静かに見てきたなら、これがその脱出方法です。
- 報酬
- いいね
- コメント
- リポスト
- 共有
その実感は衝撃的だった:AIはクリエイターのコンテンツを殺したのではなく、平坦化したのだ。
市販のAIを使うすべてのソロクリエイターは、交換可能に聞こえる作品を送り出していた。
人々が何年もかけて築いた差別化は、数ヶ月で崩れつつあった。
原文表示市販のAIを使うすべてのソロクリエイターは、交換可能に聞こえる作品を送り出していた。
人々が何年もかけて築いた差別化は、数ヶ月で崩れつつあった。
- 報酬
- いいね
- コメント
- リポスト
- 共有
私は6ヶ月前にほとんどXアカウントを削除しそうになった。
アルゴリズムが悪化したからではない。
私自身が悪化していたからだ。
すべての投稿がAIが書いたように聞こえた。
なぜならAIがそうしていたからだ。
今日はその修正を出荷している。
🧵
原文表示アルゴリズムが悪化したからではない。
私自身が悪化していたからだ。
すべての投稿がAIが書いたように聞こえた。
なぜならAIがそうしていたからだ。
今日はその修正を出荷している。
🧵
- 報酬
- いいね
- コメント
- リポスト
- 共有