Iceberg + Spark + Trino:ブロックチェーンに最適な最新オープンソースデータスタック
本章では、Footprintの主なアーキテクチャアップグレードや機能、さらにデータ収集・整理に関するパフォーマンスについて詳しくご紹介します。
現代ブロックチェーンデータスタックの課題
現代のブロックチェーンインデックス構築スタートアップが直面する主な課題は、以下の通りです。
- 膨大なデータ量。ブロックチェーン上のデータ増加に伴い、データインデックスは負荷増大に対応し、効率的なデータアクセスを維持するためのスケーラビリティが求められます。その結果、ストレージコストの増加、メトリクス計算の遅延、データベースサーバーへの負荷増大といった問題が生じます。
- 複雑なデータ処理パイプライン。ブロックチェーン技術は高度に複雑であり、信頼性の高い包括的なデータインデックス構築には、基盤となるデータ構造やアルゴリズムへの深い理解が不可欠です。これはブロックチェーン実装の多様性にも起因します。例えば、Ethereum上のNFTは通常、ERC721やERC1155規格のスマートコントラクト内で生成されますが、Polkadotではブロックチェーンランタイム内で直接実装される場合が一般的です。最終的には、いずれもNFTとして認識し、保存する必要があります。
- 統合性。ユーザーに最大限の価値を提供するためには、ブロックチェーンインデックスソリューションが分析プラットフォームやAPIなど他システムとのデータ連携を実現する必要があります。これにはアーキテクチャ設計段階で多大な労力が必要となります。
ブロックチェーン技術の普及により、ブロックチェーン上に保存されるデータ量は急増しています。利用者の増加や、各トランザクションごとに新たなデータが追加されることが主な要因です。さらに、ブロックチェーン技術の利用範囲は、Bitcoinのような単純な送金アプリケーションから、スマートコントラクトによるビジネスロジック実装を伴う高度なアプリケーションへと進化しています。こうしたスマートコントラクトは大量のデータを生成し、ブロックチェーンの複雑化と大規模化を促進しています。結果として、ブロックチェーンはより大きく、複雑なシステムへと成長しました。
本記事では、Footprint Analyticsの技術アーキテクチャの進化を段階的に振り返り、Iceberg-Trinoテクノロジースタックがオンチェーンデータの課題をどのように解決するか、ケーススタディとして解説します。
Footprint Analyticsは、約22のパブリックブロックチェーンデータ、17のNFTマーケットプレイス、1,900のGameFiプロジェクト、10万件超のNFTコレクションをセマンティック抽象化データレイヤーにインデックス化しています。これは世界で最も包括的なブロックチェーンデータウェアハウスソリューションです。
ブロックチェーンデータは、200億件を超える金融取引記録を含み、データアナリストによる頻繁なクエリ対象となっています。これは従来のデータウェアハウスのインジェスションログとは異なります。
ここ数カ月間で、成長するビジネス要件に対応するため、3度の大規模アップグレードを実施しました。
アーキテクチャ1.0 Bigquery
Footprint Analyticsの初期段階では、Google Bigqueryをストレージ兼クエリエンジンとして採用していました。Bigqueryは非常に高速で使いやすく、動的な演算能力や柔軟なUDF構文により、迅速な業務遂行を可能にする優れたプロダクトです。
しかし、Bigqueryにはいくつかの課題が存在しました。
- データが圧縮されないため、特にFootprint Analyticsの22以上のブロックチェーンの生データ保存時にストレージコストが高騰します。
- 同時実行性の不足:Bigqueryは最大100件の同時クエリしかサポートせず、多数のアナリストやユーザーを抱えるFootprint Analyticsの高い同時実行性ニーズには対応できません。
- Google Bigqueryへのロックイン。Bigqueryはクローズドソース製品です。
こうした課題から、他のアーキテクチャの検討を開始しました。
アーキテクチャ2.0 OLAP
当時、注目を集めていたOLAP製品に強い関心を持ちました。OLAPの最大の魅力は、膨大なデータに対するクエリ応答時間が非常に短く、数千件の同時クエリもサポートできる点です。
私たちは最良のOLAPデータベースの一つ「Doris」を選定し、試験的に導入しました。このエンジンは高いパフォーマンスを示しましたが、すぐに以下の課題が判明しました:
- ArrayやJSONなどのデータ型が未対応(2022年11月時点)。Arrayは一部のブロックチェーンで一般的なデータ型であり、例えばevmログのtopicフィールドなどが該当します。Arrayで計算ができないことは、多くのビジネスメトリクス算出に直接影響します。
- DBTやマージステートメントのサポートが限定的。これらはETL/ELTシナリオでデータエンジニアにとって一般的な要件であり、新たにインデックス化されたデータの更新が必要です。
このため、Dorisを本番環境の全データパイプラインには利用できず、OLAPデータベースとしてデータ生産パイプラインの一部課題解決のために、クエリエンジンとして高速かつ高い同時実行性を提供する用途に限定しました。
BigqueryをDorisで完全に置き換えることはできなかったため、BigqueryからDorisへの定期的なデータ同期が必要となりました。しかし、この同期プロセスには課題があり、特にOLAPエンジンがフロントエンドクライアントへのクエリ応答で多忙な際、更新書き込みがすぐに滞留し、書き込み速度が低下、同期が大幅に遅延し、時には完了できないこともありました。
OLAPは私たちが直面するいくつかの課題を解決できるものの、Footprint Analyticsのデータ処理パイプライン全体における万能解とはならないことを認識しました。私たちの課題はより大きく、複雑であり、OLAPをクエリエンジンとして単独で用いるだけでは十分ではありませんでした。
アーキテクチャ3.0 Iceberg + Trino
Footprint Analyticsアーキテクチャ3.0へようこそ。基盤アーキテクチャを全面的に刷新し、データのストレージ・計算・クエリを3つの独立した構成要素に分離しました。これは、Footprint Analyticsの過去2つのアーキテクチャで得た知見や、Uber、Netflix、Databricksなど他の先進的なビッグデータプロジェクトの経験を活かしたものです。
データレイクの導入
まず注目したのはデータレイクです。データレイクは、構造化・非構造化データの両方を格納できる新しいタイプのデータストレージです。オンチェーンデータのフォーマットは非構造な生データから、Footprint Analyticsが得意とする構造化抽象データまで多岐にわたり、データレイクはオンチェーンデータ保存に最適です。データレイクを活用することでデータ保存の課題を解決し、SparkやFlinkなどの主流計算エンジンもサポートできれば、Footprint Analyticsの進化に合わせて多様な処理エンジンとの統合も容易になると期待しました。
IcebergはSpark、Flink、Trinoなどの計算エンジンと高い親和性を持ち、各種メトリクスごとに最適な計算方式を選択できます。例えば:
- 複雑な計算ロジックが必要な場合はSpark
- リアルタイム計算にはFlink
- SQLで実行可能な単純なETLタスクにはTrino
クエリエンジン
Icebergでストレージと計算の課題を解決した後、次はクエリエンジンの選定でした。選択肢は多くなく、検討対象は以下の通りです。
- Trino: SQLクエリエンジン
- Presto: SQLクエリエンジン
- Kyuubi: サーバーレスSpark SQL
最も重視したのは、将来のクエリエンジンが現行アーキテクチャと高い互換性を持つことでした。
- Bigqueryをデータソースとしてサポート
- 多くのメトリクス生成に依存するDBTをサポート
- BIツールMetabaseをサポート
これら要件を踏まえ、Icebergとの親和性が高く、バグ報告にも迅速対応(翌日修正・翌週リリース)してくれるTrinoを選択しました。高い実装レスポンスが求められるFootprintチームにとって、最良の選択肢でした。
パフォーマンステスト
方向性を決定した後、Trino + Icebergの組み合わせでパフォーマンステストを実施し、要件を満たすか検証しました。結果は想像を超える高速なクエリ応答でした。
Presto + Hiveが長年OLAP分野で最も低評価だった一方、Trino + Icebergの組み合わせは私たちの予想を大きく上回りました。
以下はテスト結果です。
ケース1:大規模データセットの結合
800GBのtable1と50GBのtable2を結合し、複雑なビジネス計算を実施ケース2:大規模単一テーブルでdistinctクエリ
テストSQL:select distinct(address) from table group by day

Trino+Icebergの組み合わせは、同一構成下でDorisの約3倍の速度を記録しました。
さらに、IcebergはParquetやORCなどのデータフォーマットを利用したデータ圧縮・保存が可能であり、Icebergのテーブルストレージは他のデータウェアハウスの約1/5のスペースしか使用しません。同一テーブルの3つのデータベースでのストレージサイズは以下の通りです。

注:上記テストは実際のプロダクション環境での個別事例であり、参考値です。
・アップグレード効果
パフォーマンステストで十分な性能を確認できたため、約2カ月で移行を完了しました。以下はアップグレード後のアーキテクチャ図です。
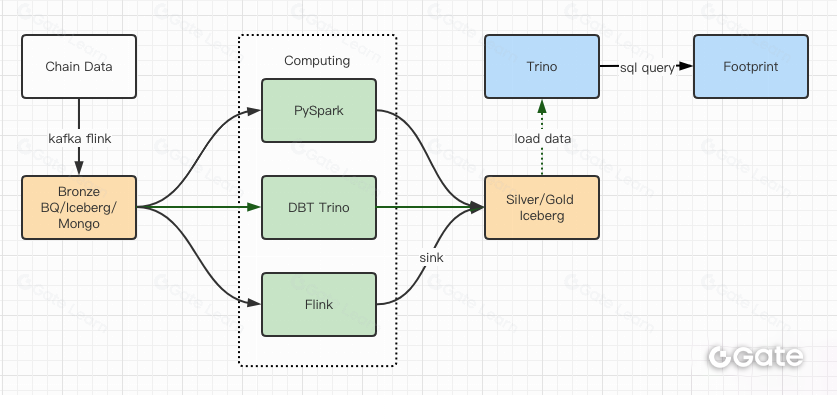
- 複数の計算エンジンで多様なニーズに対応
- TrinoはDBTをサポートし、Icebergに直接クエリできるため、データ同期作業が不要に
- Trino + Icebergの優れたパフォーマンスにより、全てのBronzeデータ(生データ)をユーザーに公開可能に
まとめ
2021年8月のローンチ以来、Footprint Analyticsチームは1年半足らずで3回のアーキテクチャアップグレードを完了しました。これは、最高のデータベース技術の恩恵を暗号資産ユーザーに届けるという強い意志と、基盤インフラ・アーキテクチャの実装・アップグレードにおける確実な遂行力によるものです。
Footprint Analyticsアーキテクチャ3.0へのアップグレードにより、異なるバックグラウンドのユーザーがより多様な用途・アプリケーションでインサイトを得る新たな体験がもたらされました。
- Metabase BIツールを活用したFootprintにより、アナリストはデコード済みオンチェーンデータへアクセスし、ツールの選択(ノーコード・ハードコア問わず)も自由、全履歴へのクエリやデータセットのクロス分析も可能で、即座にインサイトを取得できます。
- オンチェーン・オフチェーン双方のデータを統合し、Web2 + Web3横断分析が可能
- Footprintのビジネス抽象化上でメトリクス構築・クエリを行うことで、アナリストや開発者は80%の繰り返しデータ処理作業を省力化し、意味ある指標・リサーチ・プロダクトソリューションに集中できます。
- Footprint WebからREST APIコールまで、すべてSQLベースでシームレスな体験を提供
- 投資判断を支援する主要シグナルのリアルタイムアラート・アクション通知
関連コース

暗号資産におけるアイデンティティ:主なプロジェクト

マスターノードトークンの紹介

分散型アイデンティティの基礎

暗号デリバティブ:主なプロジェクト

暗号資産における自分自身の調査(DYOR)を行う
