Купити криптовалюту
Оплачуйте
USD
Купити та продати
HOT
Купуйте та продавайте криптовалюту через Apple Pay, картки, Google Pay, Банківський переказ тощо
P2P
0 Fees
Нульова комісія, понад 400 способів оплати та зручна купівля й продаж криптовалют
Gate Card
Криптовалютна платіжна картка, що дозволяє здійснювати безперешкодні глобальні транзакції.
Торгівля
Базовий
Спот
Вільно торгуйте криптовалютою
Маржа
Збільшуйте свій прибуток за допомогою кредитного плеча
Конвертація та блокова торгівля
0 Fees
Торгуйте будь-яким обсягом без комісій та прослизань
Токени з кредитним плечем
Отримайте швидкий доступ до позицій кредитного плеча
Премаркет
Торгуйте новими токенами до їх офіційного лістингу
Просунутий рівень
DEX
Торгуйте ончейн за допомогою Gate Wallet
Alpha
Points
Отримуйте перспективні токени в спрощеній ончейн торгівлі
Боти
Торгуйте в один клік за допомогою інтелектуальних стратегій з автоматичним запуском
Копіювання
Примножуйте статки, слідуючи за топ-трейдерами
Торгівля CrossEx
Beta
Єдиний маржинальний баланс, спільний для всіх платформ
Ф'ючерси
Ф'ючерси
Сотні контрактів розраховані в USDT або BTC
Опціони
HOT
Торгівля ванільними опціонами європейського зразка
Єдиний рахунок
Максимізуйте ефективність вашого капіталу
Демо торгівля
Запуск ф'ючерсів
Підготуйтеся до ф’ючерсної торгівлі
Ф'ючерсні події
Беріть участь у подіях, щоб виграти щедрі винагороди
Демо торгівля
Використовуйте віртуальні кошти для безризикової торгівлі
Earn
Запуск
CandyDrop
Збирайте цукерки, щоб заробити аірдропи
Launchpool
Швидкий стейкінг, заробляйте нові токени
HODLer Airdrop
Утримуйте GT і отримуйте масові аірдропи безкоштовно
Launchpad
Будьте першими в наступному великому проекту токенів
Бали Alpha
NEW
Торгуйте ончейн-активами і насолоджуйтеся аірдроп-винагородами!
Ф'ючерсні бали
NEW
Заробляйте фʼючерсні бали та отримуйте аірдроп-винагороди
Інвестиції
Simple Earn
Заробляйте відсотки за допомогою неактивних токенів
Автоінвестування
Автоматичне інвестування на регулярній основі
Подвійні інвестиції
Купуйте дешево і продавайте дорого, щоб отримати прибуток від коливань цін
Soft Staking
Earn rewards with flexible staking
Криптопозика
0 Fees
Заставте одну криптовалюту, щоб позичити іншу
Центр кредитування
Єдиний центр кредитування
Центр багатства VIP
Індивідуальне управління капіталом сприяє зростанню ваших активів
Управління приватним капіталом
Індивідуальне управління активами для зростання ваших цифрових активів
Квантовий фонд
Найкраща команда з управління активами допоможе вам отримати прибуток без клопоту
Стейкінг
Стейкайте криптовалюту, щоб заробляти на продуктах PoS
Розумне кредитне плече
NEW
Жодної примусової ліквідації до дати погашення — прибуток із плечем без зайвих ризиків
Випуск GUSD
Використовуйте USDT/USDC для випуску GUSD з дохідністю на рівні казначейських облігацій
Більше

#Gate广场创作者新春激励 突валецька корекція! BTC опустився нижче 9.3万, ETH втратив рівень 3230, ринок криптовалют посилює боротьбу між покупцями та продавцями, чи варто купувати на дні чи чекати?
19 січня 2026 року, ринок криптовалют переживає момент істини! Біткойн (BTC) короткостроково різко знизився нижче позначки 9.3万 доларів, Ethereum (ETH) одночасно знизився більш ніж на 3%, обсяг ліквідацій по всій мережі стрімко зростає, паніка починає поширюватися. Ця корекція — короткочасний перепочинок у висхідній тенденції чи новий етап корекції?
Технічний аналіз: обидва основні активи подають сигнали корекц
19 січня 2026 року, ринок криптовалют переживає момент істини! Біткойн (BTC) короткостроково різко знизився нижче позначки 9.3万 доларів, Ethereum (ETH) одночасно знизився більш ніж на 3%, обсяг ліквідацій по всій мережі стрімко зростає, паніка починає поширюватися. Ця корекція — короткочасний перепочинок у висхідній тенденції чи новий етап корекції?
Технічний аналіз: обидва основні активи подають сигнали корекц
ETH-0,58%


- Нагородити
- 3
- 3
- Репост
- Поділіться
Rambler1 :
:
Інвестиції в ринок криптовалют пов'язані з високими ризиками, рекомендується користувачам проводити незалежне дослідження та повністю розуміти характер активів і продуктів, які вони купують, перед прийняттям будь-яких інвестиційних рішень. Gate не несе відповідальності за будь-які збитки або шкоду, спричинені такими інвестиційними рішеннями.Дізнатися більше
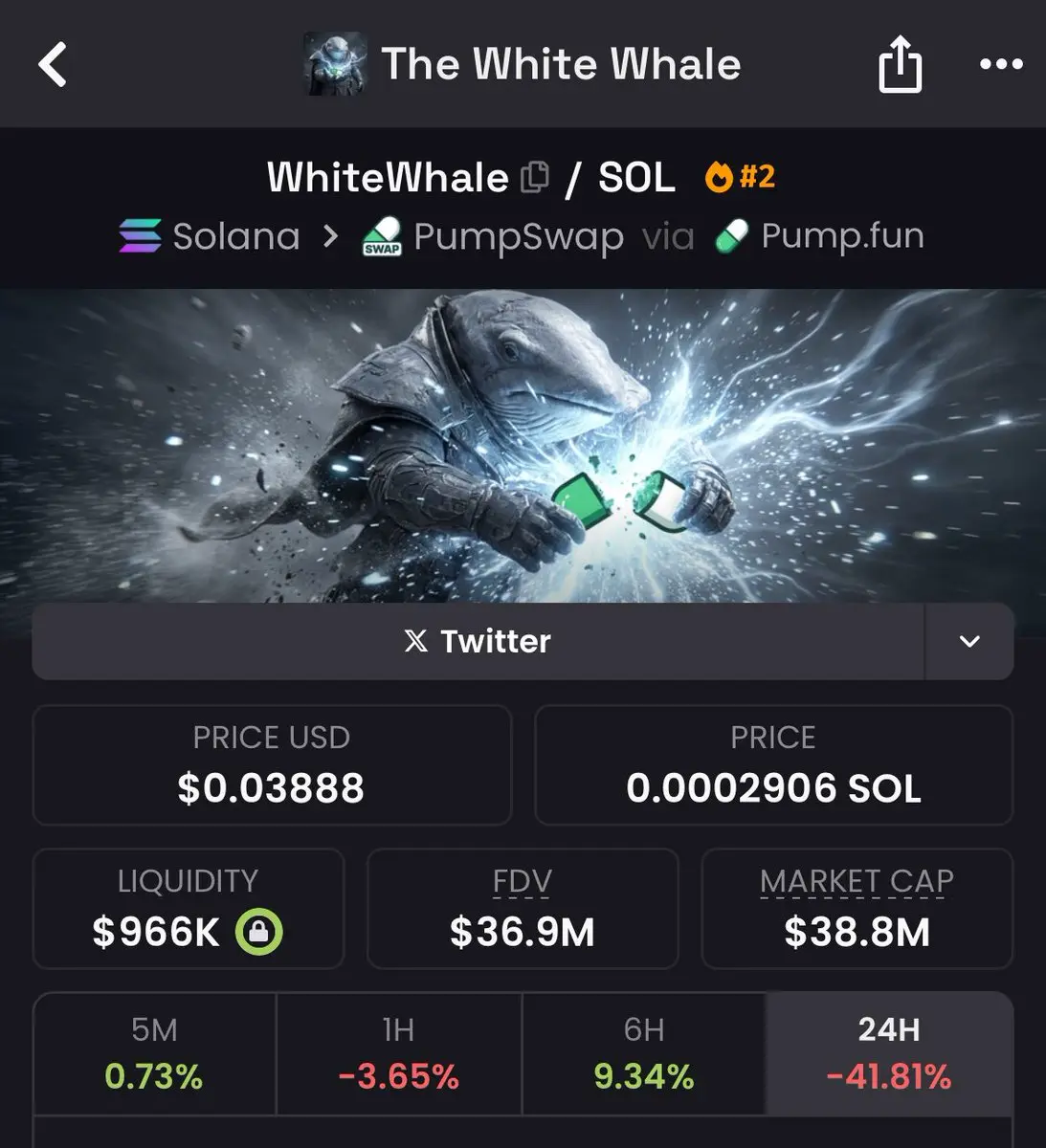
Тобто я думаю, $whitewhale @ 38м після зеленого дило-руху до 200м — це не погана ставка 👀🐋
Якщо б ти був у траншеях більше ніж 5 хвилин, ти б бачив величезні прориви, за якими йшли великі спади на основних гравцях
Ви всі мали FOMO при 100м, але не хочете ставити при 38м 😹
Вхід у чат або gg 🙃
Переглянути оригіналЯкщо б ти був у траншеях більше ніж 5 хвилин, ти б бачив величезні прориви, за якими йшли великі спади на основних гравцях
Ви всі мали FOMO при 100м, але не хочете ставити при 38м 😹
Вхід у чат або gg 🙃
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
大圣归来
大圣归来
Створено@1516481299
Перебіг лістингу
0.00%
Рин. кап.:
$3.53K
Створити мій токен
❄️Супер Сніжка❄️
Чесний запуск платформи Butterfly
Міцний капітал, повна підтримка ✅
Світовий топ-100 спільнот, спільна ціль і зусилля ✅
Команда з топовою ринковою капіталізацією, точне планування ✅
——Тільки для створення наступного чудового мільярдного дива 🚀🚀
❄️Адреса контракту супер Сніжка: 0x7ee784fc79f43d8c863ef2583eed94e576bd7777
Чесний запуск платформи Butterfly
Міцний капітал, повна підтримка ✅
Світовий топ-100 спільнот, спільна ціль і зусилля ✅
Команда з топовою ринковою капіталізацією, точне планування ✅
——Тільки для створення наступного чудового мільярдного дива 🚀🚀
❄️Адреса контракту супер Сніжка: 0x7ee784fc79f43d8c863ef2583eed94e576bd7777
Переглянути оригінал

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
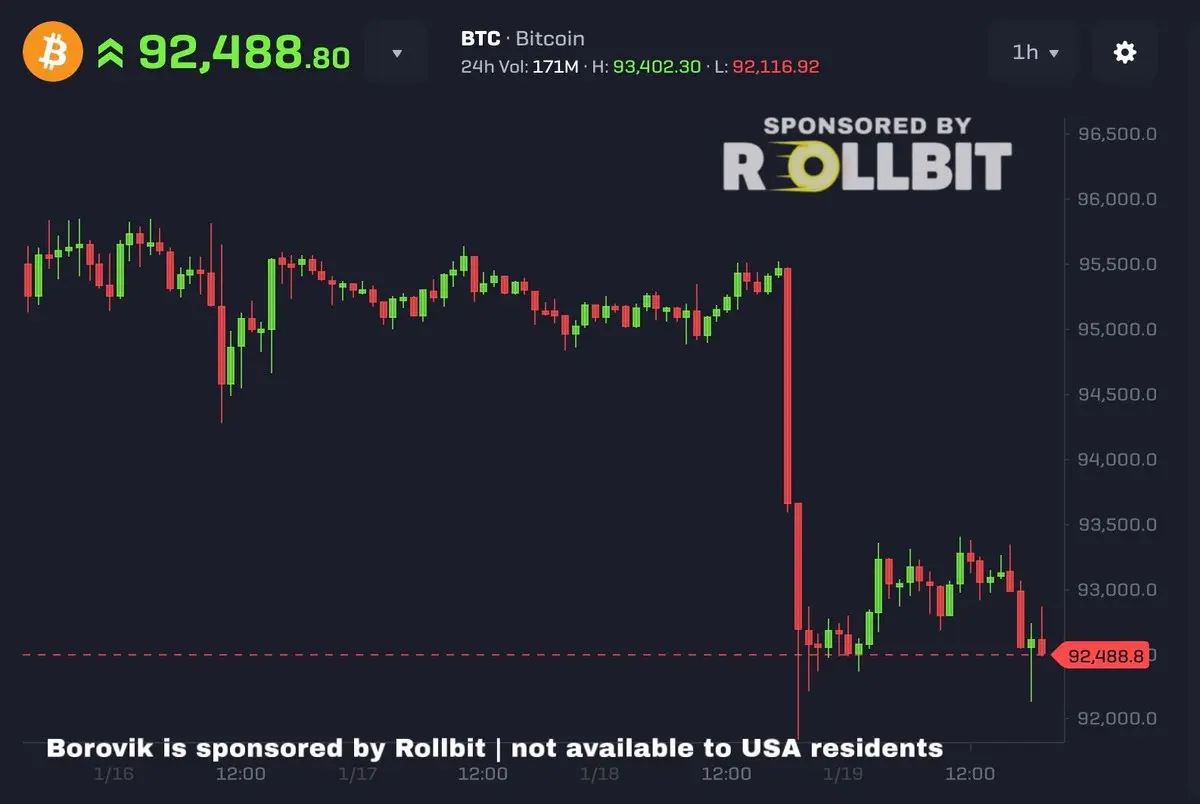
Біткоїн цього року знизився до $92,000
Ми за 3 місяці від заміни Джерома Пауелла на посаду голови ФРС, що означає, що ставки почнуть знижуватися вже влітку
Я вважаю, що BTC підніметься понад $150,000
Ми за 3 місяці від заміни Джерома Пауелла на посаду голови ФРС, що означає, що ставки почнуть знижуватися вже влітку
Я вважаю, що BTC підніметься понад $150,000
Переглянути оригінал
- Нагородити
- 1
- 1
- Репост
- Поділіться
GateUser-d9c25102 :
:
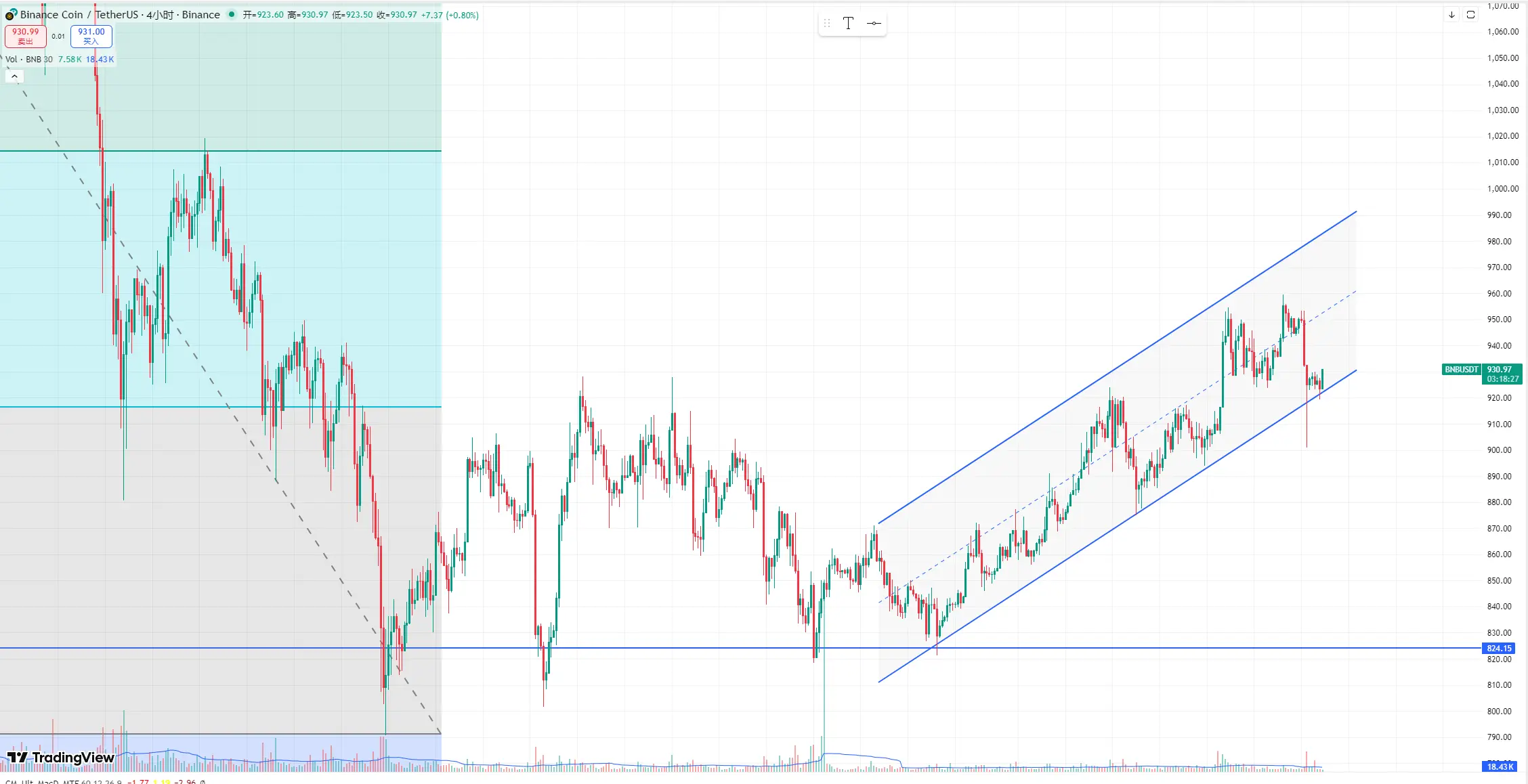
Дуже дякую за інформацію 👋$BNB все ще залишаються такими ж міцними, як і раніше
Вчора під час трансляції я також говорив, що BNB знаходиться в висхідному каналі, і зниження вчора вранці було найшвидшим і найбільшим для BNB у цьому каналі. Тому я тоді прогнозував, що в короткостроковій перспективі цей канал навряд чи буде легко прорваний. Також я порадив відкрити довгу позицію біля нижньої межі висхідного каналу, не знаю, чи всі це отримали.
Вчора під час трансляції я також говорив, що BNB знаходиться в висхідному каналі, і зниження вчора вранці було найшвидшим і найбільшим для BNB у цьому каналі. Тому я тоді прогнозував, що в короткостроковій перспективі цей канал навряд чи буде легко прорваний. Також я порадив відкрити довгу позицію біля нижньої межі висхідного каналу, не знаю, чи всі це отримали.
BNB1,13%
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
Знову порожня перша позиція у списку падінь, дуже просто, я вже вас цьому навчив.
Переглянути оригінал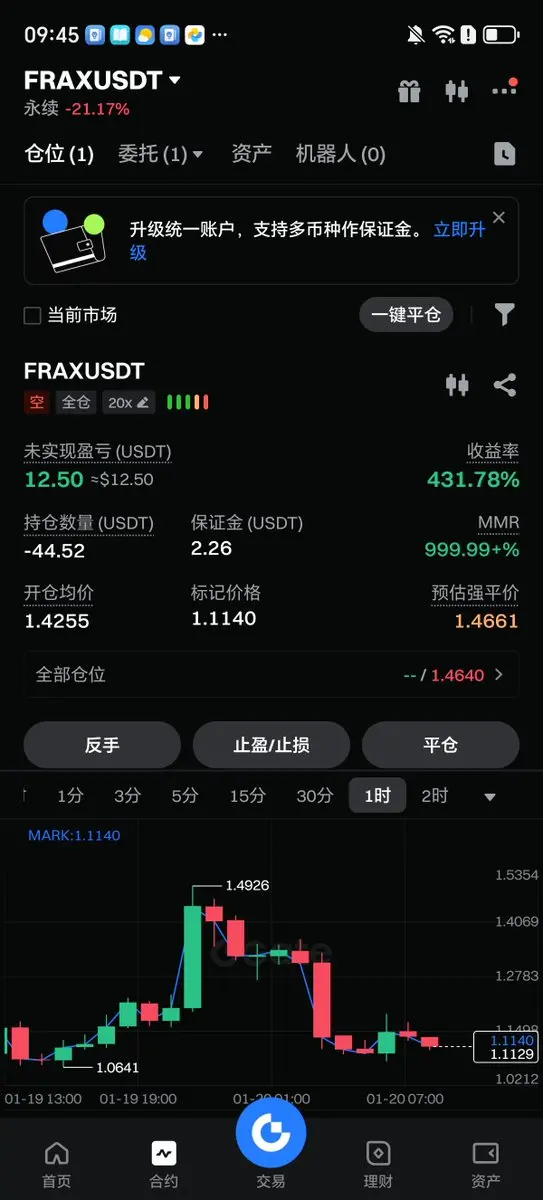
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться

Мій підсумковий звіт за 2025 рік у Gate вже тут! Дивіться, як я проявив себе цього року.
Натисніть посилання, щоб переглянути ексклюзивний підсумковий звіт #2025GateYearEndSummary та Віділ статусу вартістю 20 USDT. https://www.gate.com/vi/competition/your-year-in-review-2025?ref=VVHHVF1XBA&ref_type=126&shareUid=U1JFXFpbBwUO0O0O
Переглянути оригіналНатисніть посилання, щоб переглянути ексклюзивний підсумковий звіт #2025GateYearEndSummary та Віділ статусу вартістю 20 USDT. https://www.gate.com/vi/competition/your-year-in-review-2025?ref=VVHHVF1XBA&ref_type=126&shareUid=U1JFXFpbBwUO0O0O

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
У мене тут іде сніг❄️
Щодня стає все холодніше, люди стають лінивими
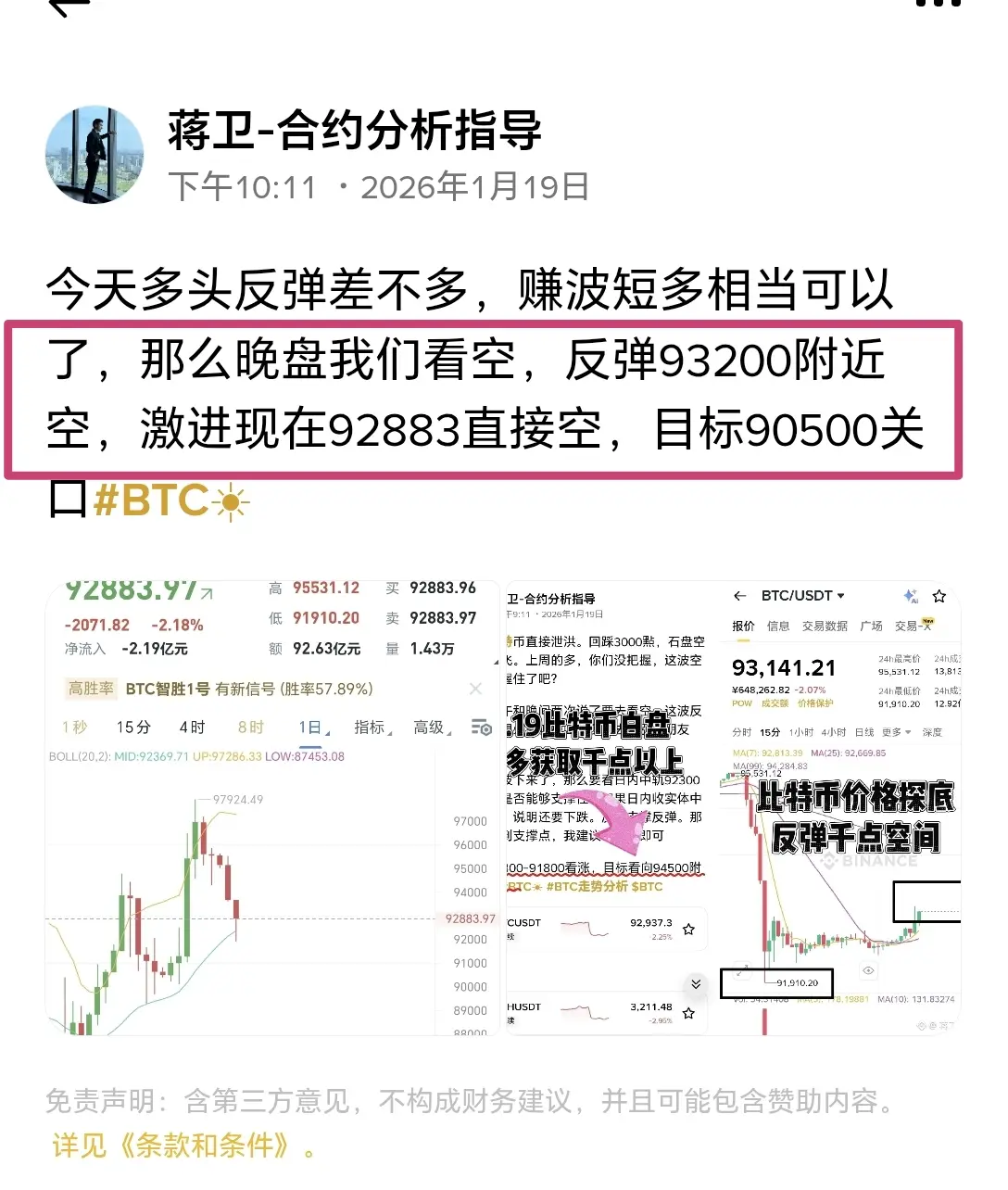
Вранці ціна біткойна опустилася до найнижчої близько 92150. Ви вже відкрили короткі позиції? Якщо так, чекайте, поки ціна підніметься вище 93, щоб продовжити короткі. Якщо ні, тримайте і володійте позицією#BTC #ETH
Щодня стає все холодніше, люди стають лінивими
Вранці ціна біткойна опустилася до найнижчої близько 92150. Ви вже відкрили короткі позиції? Якщо так, чекайте, поки ціна підніметься вище 93, щоб продовжити короткі. Якщо ні, тримайте і володійте позицією#BTC #ETH
ETH-0,58%

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
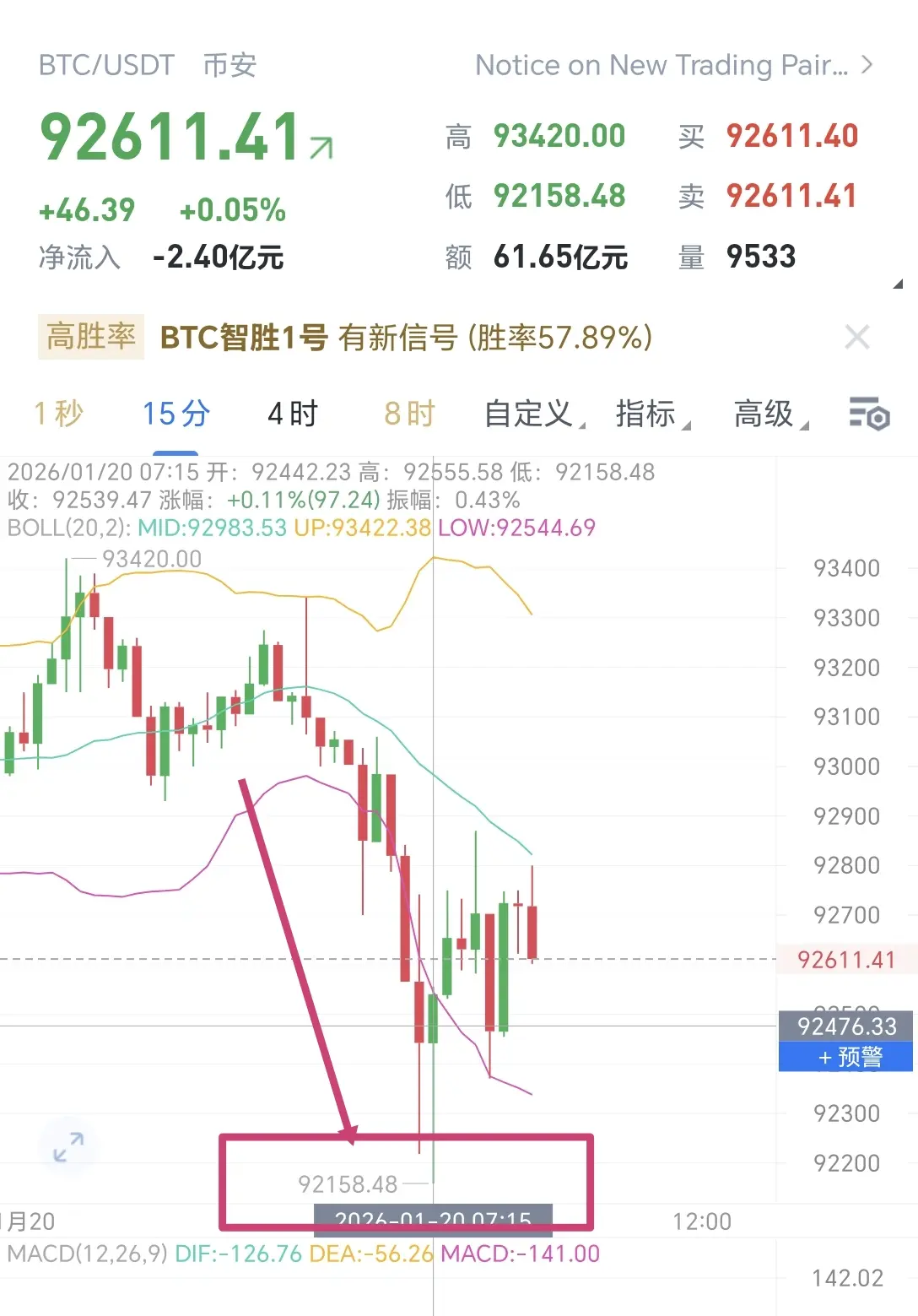
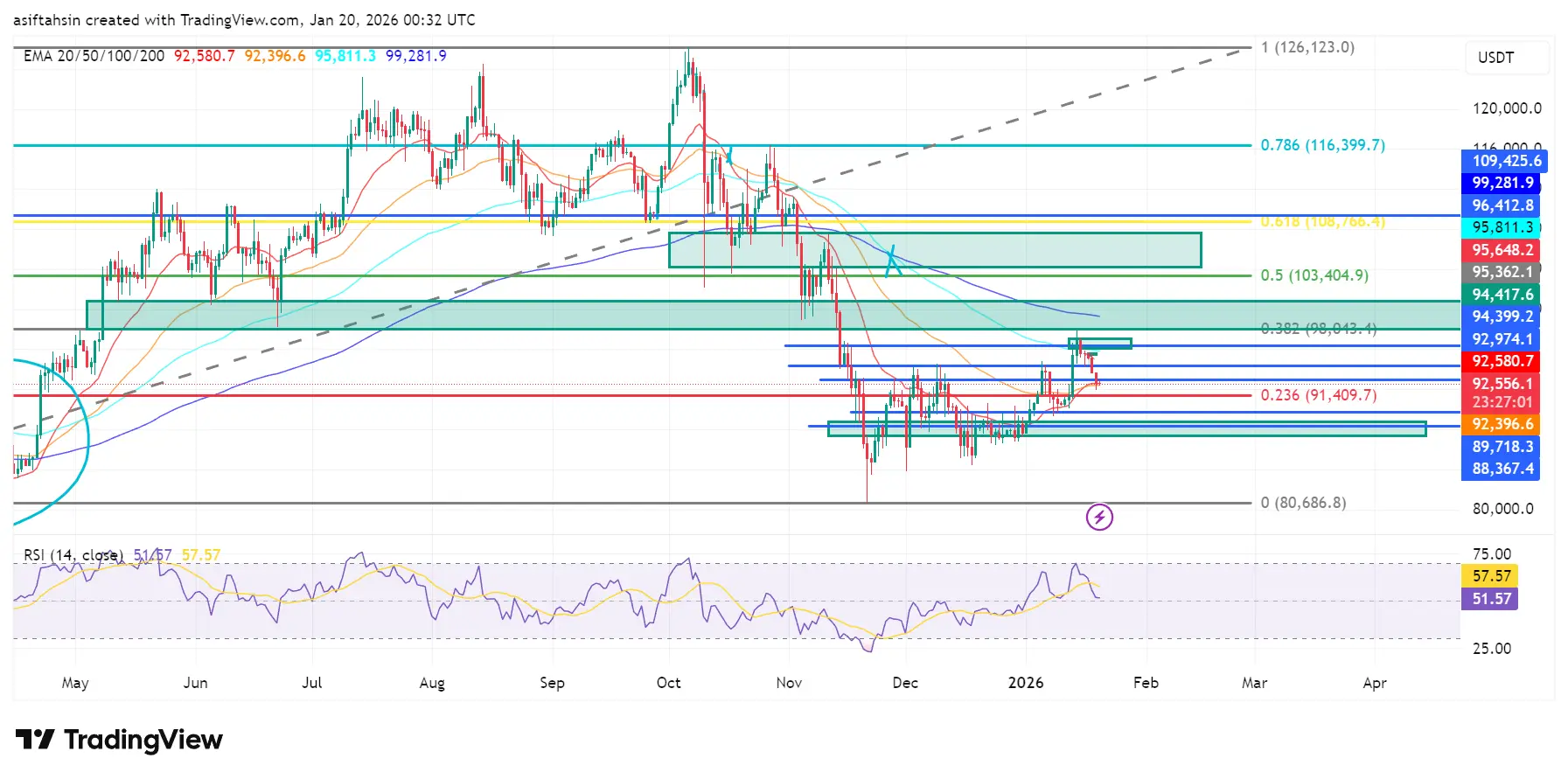
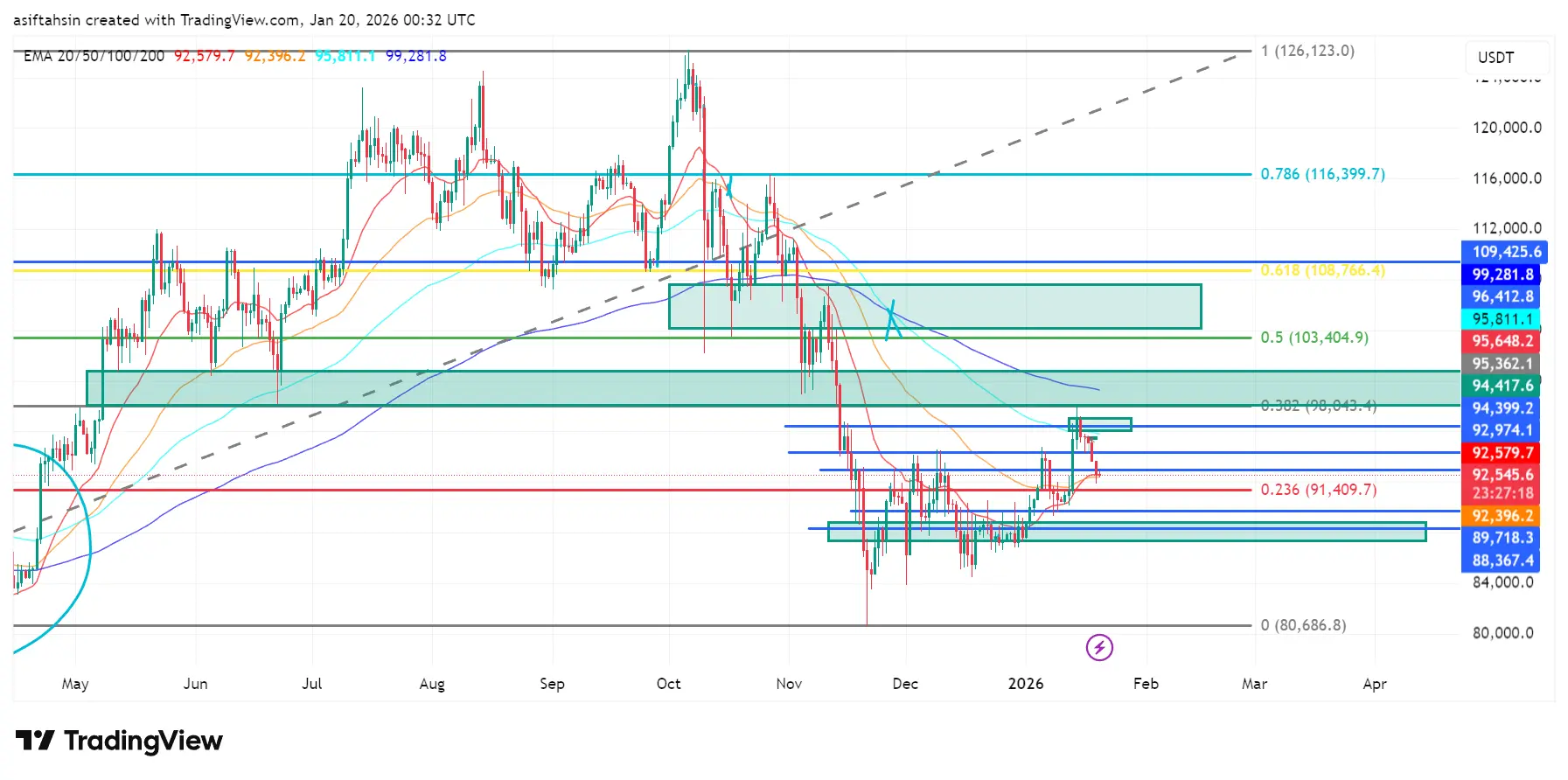
Перспективи технічного аналізу BTC: структура відновлення тестує ключові рівні Фібоначчі та EMA
Біткоїн залишається у ширшій коригуючій структурі після різкого відторгнення від макро-зони пропозиції $116K–$126K , рівня 0.786–1 Фібоначчі(. Це відторгнення позначило вершину розподілу, за якою слідував сильний ведучий рух у зону попиту $80K–).
Останні цінові рухи показують відскок BTC від довгострокового попиту, формуючи базу з вищими мінімумами. Моментум покращився, але тренд на більш тривалих таймфреймах ще не повністю змінився на бичий.
Структура EMA $90K Бичий нахил, покращення короткостроков
Біткоїн залишається у ширшій коригуючій структурі після різкого відторгнення від макро-зони пропозиції $116K–$126K , рівня 0.786–1 Фібоначчі(. Це відторгнення позначило вершину розподілу, за якою слідував сильний ведучий рух у зону попиту $80K–).
Останні цінові рухи показують відскок BTC від довгострокового попиту, формуючи базу з вищими мінімумами. Моментум покращився, але тренд на більш тривалих таймфреймах ще не повністю змінився на бичий.
Структура EMA $90K Бичий нахил, покращення короткостроков
Переглянути оригінал
- Нагородити
- 4
- 4
- Репост
- Поділіться
Discovery:
GOGOGO 2026 👊Дізнатися більше
Це те, що означає CT, коли ви бачите, що ми повернулися
Переглянути оригінал
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
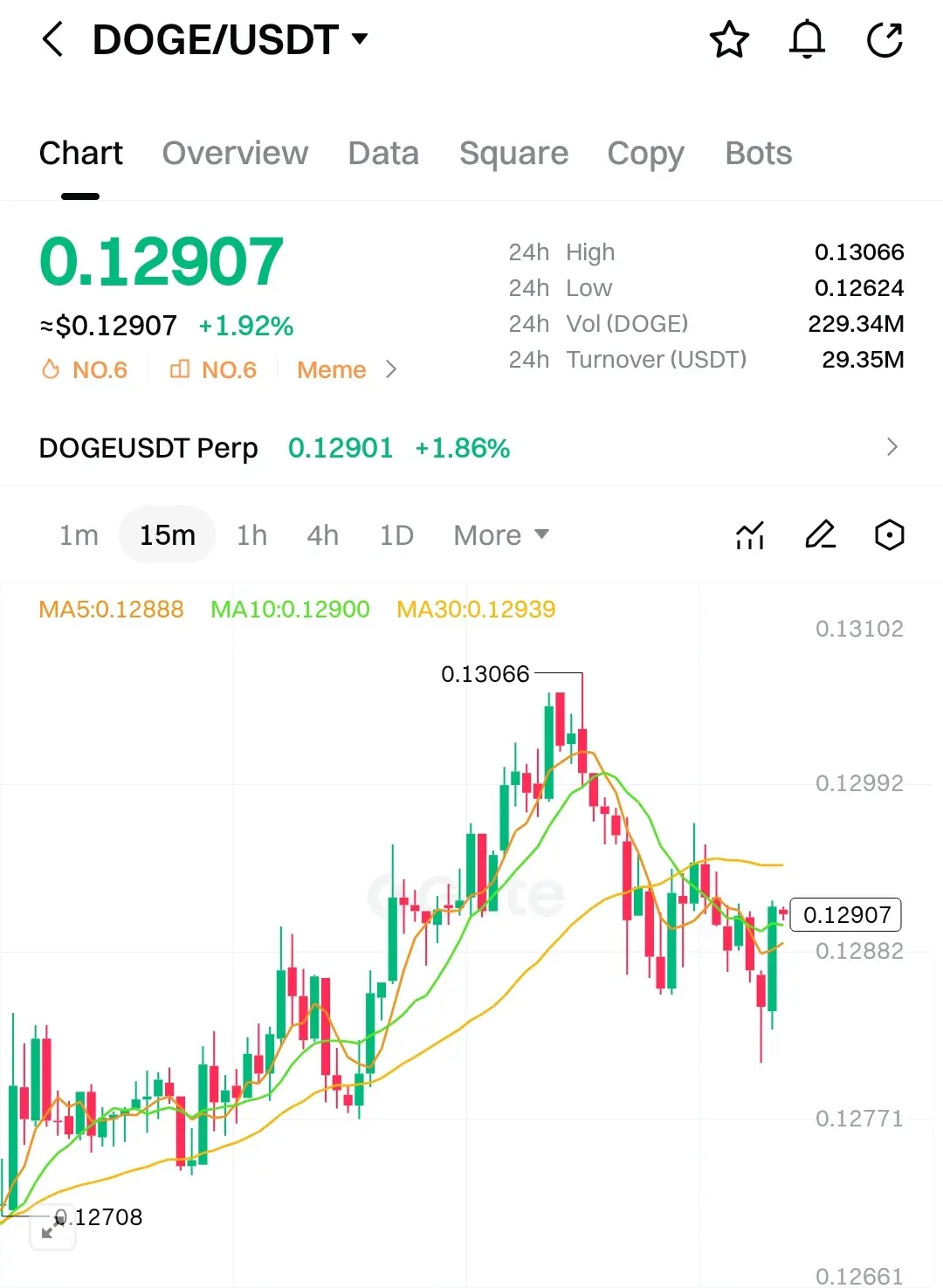
🐕🔥 $DOGE / USDT залишається у боротьбі!
Ціна: $0.12907 (+1.92%)
Максимум / Мінімум за 24H: $0.13066 / $0.12624
Обсяг за 24H: 229.34M DOGE
Обіг за 24H: $29.35M
Perp: $0.12901 (+1.86%)
На графіку 15хв DOGE відкотився від $0.13066 і зараз стабілізується навколо ключових середніх:
MA5: 0.12888
MA10: 0.12900
MA30: 0.12939
Ціна стискається біля МА — класична пауза перед наступним рухом. Волатильність жива, ліквідність сильна, і DOGE здається готовим швидко визначити напрямок.
Мем ніколи не спить 👀🚀
#CryptoMarketWatch
Ціна: $0.12907 (+1.92%)
Максимум / Мінімум за 24H: $0.13066 / $0.12624
Обсяг за 24H: 229.34M DOGE
Обіг за 24H: $29.35M
Perp: $0.12901 (+1.86%)
На графіку 15хв DOGE відкотився від $0.13066 і зараз стабілізується навколо ключових середніх:
MA5: 0.12888
MA10: 0.12900
MA30: 0.12939
Ціна стискається біля МА — класична пауза перед наступним рухом. Волатильність жива, ліквідність сильна, і DOGE здається готовим швидко визначити напрямок.
Мем ніколи не спить 👀🚀
#CryptoMarketWatch
DOGE1,36%
- Нагородити
- 1
- Прокоментувати
- Репост
- Поділіться
#Gate 2025 Year-End Community Gala#
Найкращі стрімери та творці контенту: нагороди року
Хто стане найкращим стрімером року? Хто займе перше місце в рейтингу творців контенту? Приєднуйтесь до голосування, щоб підтримати своїх улюблених стрімерів та творців, і спостерігайте за зростанням зірок спільноти!
https://www.gate.com/activities/community-vote-2025?ref=VGDEVLFACA&refType=1&refUid=32520280&ref_type=165&utm_cmp=xjdtmcgP
Переглянути оригіналНайкращі стрімери та творці контенту: нагороди року
Хто стане найкращим стрімером року? Хто займе перше місце в рейтингу творців контенту? Приєднуйтесь до голосування, щоб підтримати своїх улюблених стрімерів та творців, і спостерігайте за зростанням зірок спільноти!
https://www.gate.com/activities/community-vote-2025?ref=VGDEVLFACA&refType=1&refUid=32520280&ref_type=165&utm_cmp=xjdtmcgP

- Нагородити
- 1
- 2
- Репост
- Поділіться
Discovery:
Тримай HODL міцно 💪Дізнатися більше
k
恐惧与贪婪
Створено@LoneShadowWalkingAlone
Прогрес підписки
0.00%
Рин. кап.:
$0
Створити мій токен
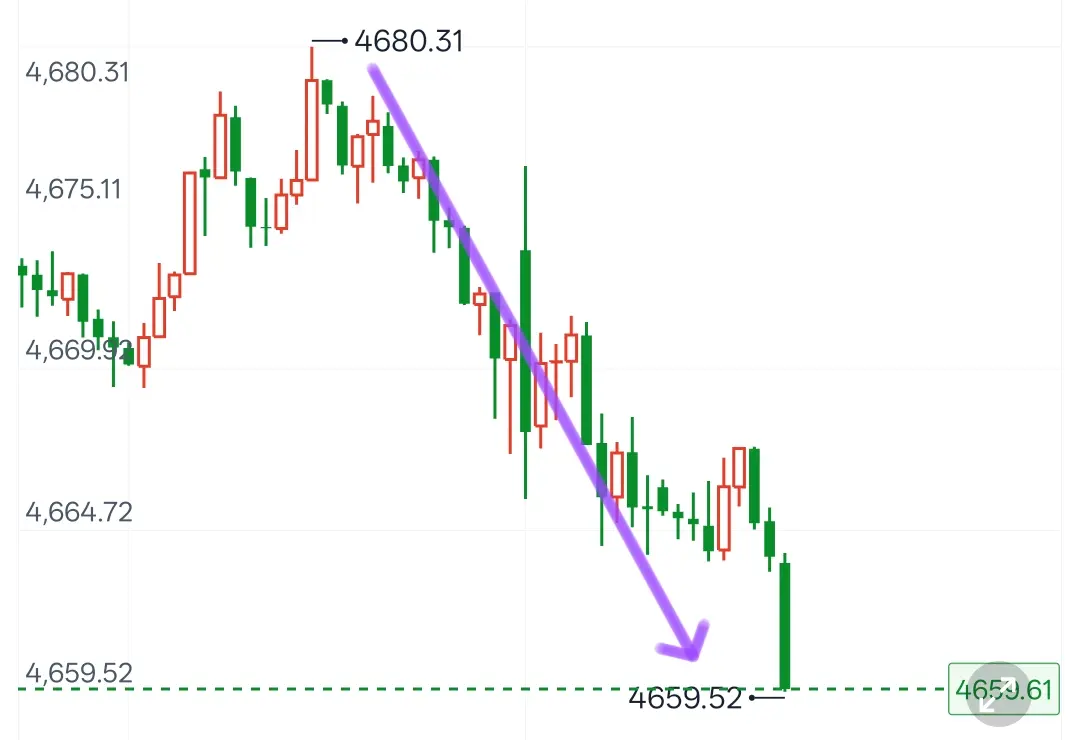
Золото точно закріпилося вранці на високих рівнях, від 4680📉 до 4659!
Переглянути оригінал
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
Те саме оголене зображення
Якщо ти виставляєш його на вуличному ринку, це буде порнографія
Якщо ти вивішуєш його у художньому музеї, це буде мистецтво людського тіла
Продовжуйте взаємне підписування #синійVвзаємне підписування
Переглянути оригіналЯкщо ти виставляєш його на вуличному ринку, це буде порнографія
Якщо ти вивішуєш його у художньому музеї, це буде мистецтво людського тіла
Продовжуйте взаємне підписування #синійVвзаємне підписування

- Нагородити
- подобається
- 1
- Репост
- Поділіться
LulululSeventeen :
:
Пік 2026 року 👊Доброго ранку! У Ухані випав перший сніг 2026 року —
Перед тим, як відвести дитину до школи, я провів з ним у дворі кілька хвилин, малюючи на землі різні малюнки, зліпив кілька маленьких сніговиків, погрались у сніжки.
На шапці дитини — сніг, на віях — сніг, личко рум'яне, але він зовсім не звертає уваги, чим більше грається, тим більше радіє, і в кінці — як і передбачалося, запізнився. 😂
Раптом я зрозумів, чому багато дорослих з часом стають все втомленішими:
Світ дорослих завжди прагне максимальної ефективності, але дітям це не потрібно, сніг — це сніг, холод — це холод, а весело — це вже д
Переглянути оригіналПеред тим, як відвести дитину до школи, я провів з ним у дворі кілька хвилин, малюючи на землі різні малюнки, зліпив кілька маленьких сніговиків, погрались у сніжки.
На шапці дитини — сніг, на віях — сніг, личко рум'яне, але він зовсім не звертає уваги, чим більше грається, тим більше радіє, і в кінці — як і передбачалося, запізнився. 😂
Раптом я зрозумів, чому багато дорослих з часом стають все втомленішими:
Світ дорослих завжди прагне максимальної ефективності, але дітям це не потрібно, сніг — це сніг, холод — це холод, а весело — це вже д

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
Гаманець, пов’язаний із мемкоіном, викликає занепокоєння щодо внутрішньої активності - - #cryptocurrency #bitcoin #altcoins
MEME7,27%

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
Тільки стратегія купівлі золота без короткострокового продажу приносить прибуток?
Щоденний звіт про інвестиції в золото від 20 січня від Золотого Кролика
Після того, як 1 січня за допомогою магії Чжичженьдуньцзя було зроблено прогноз щодо золота, 4 січня було здійснено покупку, загалом інвестовано 20 W ➕ у ВТБ, X W у Золото ➕, 5 грамів фізичного золота ВТБ.
Зранку, перш ніж почати день, відкриваючи торгове додаток, дивлюся на сьогоднішній $XAU тренд, після нових максимумів вчора, ціна зараз невелике коригування, становить 4662 доларів США за унцію.
Причиною зростання вчора стали збільшення ак
Щоденний звіт про інвестиції в золото від 20 січня від Золотого Кролика
Після того, як 1 січня за допомогою магії Чжичженьдуньцзя було зроблено прогноз щодо золота, 4 січня було здійснено покупку, загалом інвестовано 20 W ➕ у ВТБ, X W у Золото ➕, 5 грамів фізичного золота ВТБ.
Зранку, перш ніж почати день, відкриваючи торгове додаток, дивлюся на сьогоднішній $XAU тренд, після нових максимумів вчора, ціна зараз невелике коригування, становить 4662 доларів США за унцію.
Причиною зростання вчора стали збільшення ак
Переглянути оригінал

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
#Gate 2025 Year-End Community Gala#
Найкращі стрімери та творці контенту — нагороди року
Хто стане найкращим стрімером року? Хто займе перше місце в рейтингу творців контенту? Приєднуйтесь до голосування, щоб підтримати своїх улюблених стрімерів і творців, і спостерігайте за зростанням зірок спільноти!
https://www.gate.com/activities/community-vote-2025?ref=VVHFUFELUQ&refUid=43079898&ref_type=165&utm_cmp=xjdtmcgP
Переглянути оригіналНайкращі стрімери та творці контенту — нагороди року
Хто стане найкращим стрімером року? Хто займе перше місце в рейтингу творців контенту? Приєднуйтесь до голосування, щоб підтримати своїх улюблених стрімерів і творців, і спостерігайте за зростанням зірок спільноти!
https://www.gate.com/activities/community-vote-2025?ref=VVHFUFELUQ&refUid=43079898&ref_type=165&utm_cmp=xjdtmcgP

- Нагородити
- 1
- Прокоментувати
- Репост
- Поділіться
Річний звіт Gate вже доступний! Давайте подивимося на мої результати за рік
Клацніть посилання, щоб переглянути ваш персональний #2025Gate年度账单 , та отримайте 20 USDT на досвідчений купон https://www.gate.com/zh/competition/your-year-in-review-2025?ref=BAUVUA8O&ref_type=126&shareUid=VlJAUl5cBwMO0O0O
Переглянути оригіналКлацніть посилання, щоб переглянути ваш персональний #2025Gate年度账单 , та отримайте 20 USDT на досвідчений купон https://www.gate.com/zh/competition/your-year-in-review-2025?ref=BAUVUA8O&ref_type=126&shareUid=VlJAUl5cBwMO0O0O

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
Завантажити більше
Приєднуйтеся до нашої зростаючої спільноти разом із 40M користувачами
⚡️ Приєднуйтеся до обговорення криптоманії разом із 40M користувачами
💬 Спілкуйтеся з улюбленими топовими авторами
👍 Дивіться те, що вас цікавить
Популярні теми
Дізнатися більше22.42K Популярність
334.03K Популярність
41.85K Популярність
7.51K Популярність
6.07K Популярність
Популярні активності Gate Fun
Дізнатися більше- 1

牛马
牛马
Рин. кап.:$3.46KХолдери:10.00% - Рин. кап.:$3.46KХолдери:10.00%
- Рин. кап.:$3.46KХолдери:10.00%
- 4

茅台
茅台
Рин. кап.:$3.46KХолдери:10.00% - Рин. кап.:$3.53KХолдери:20.19%
Новини
Дізнатися більшеДеякий ІТ-спеціаліст із Bitcoin-рахунку був конфіскований поліцією двох країн на суму понад 80 мільйонів юанів, причини справи кілька разів змінювалися
1 м
Дані: 131.61 тисячі TON були виведені з Kiln, після транзиту вони надійшли до TON
5 м
Інженер з кібербезпеки звинувачується у крадіжці коштів азартних сайтів, поліція двох країн вилучила 183 біткоїни
10 м
Один інженер мережі був звинувачений у крадіжці коштів з азартного сайту, поліція двох регіонів послідовно порушила кримінальні справи та конфіскувала 183 біткоїни.
10 м
Один гігантський кит відкрив короткі позиції на BTC та ETH на HyperLiquid з приблизним плаваючим прибутком близько 2 мільйонів доларів
12 м
Закріпити