
Система AI-пам’яті MemPalace, у розробці якої брала участь Мілла Йовович, заявляє, що тести були виконані на 100% і через це стала вірусною, проте спільнота викрила її: тестування нібито супроводжувалося шахрайством і маніпуляціями даними. Під час практичної перевірки з’ясувалося, що ефект переоцінено і виявлено багато помилок; команда визнала недоліки та вже працює над їхнім виправленням.
Мілла Йовович створила AI-палац пам’яті, що привернув увагу ззовні
Учора (4/7) у колі AI з’явилася велика новина: голлівудська акторка Мілла Йовович (Milla Jovovich), відома ролями у «Останній охороні», «П’ятому елементі», разом із розробником Ben Sigman використала Claude Code для допомоги в розробці відкритої «MemPalace» як системи AI-пам’яті.
Одразу поширилася думка «голлівудська зірка вийшла на інший рівень і створила проєкт на максимум балів», і донині MemPalace на GitHub має понад 20 000 зірок, але дуже швидко розробницька спільнота почала сумніватися: це справді щось вартісне чи просто піар?
Спочатку розберімо мотив появи MemPalace. У офіційній документації сказано, що команда хоче вирішити проблему, коли в поточних AI-системах вміст діалогів користувачів з AI, процес ухвалення рішень та обговорення архітектури зазвичай зникають після завершення робочого етапу, через що місячні зусилля фактично падають до нуля.
Для вирішення цієї проблеми MemPalace використовує просторову архітектуру для зберігання пам’яті: інформацію чітко групують у «крилові зони» для представників або проєктів, а також у різні рівні структури, як-от коридори, кімнати та шухляди, зберігаючи оригінальний текст діалогу для подальшого семантичного пошуку.
Команда розробників заявляє, що MemPalace досягла ідеальних 100% у довготривалому оціночному базисі пам’яті LongMemEval, і водночас отримала 96.6% точності без виклику будь-яких зовнішніх API, а також може повністю працювати локально, не потребуючи підписки на хмарні сервіси, і доповнена заявленою системою діалектів AAAK, що нібито здатна забезпечити 30-кратне безвтратне стиснення.
Джерело зображення: GitHub Голлівудська зірка Мілла Йовович створила AI-палац пам’яті, що привернув увагу ззовні
Колеги та спільнота одночасно піддали сумніву, тестування та просування мають недоліки
Однак, заявлена MemPalace ідеальна оцінка LongMemEval дуже швидко викликала сумніви з боку колег.
PenfieldLabs, компанія, що також створює системи AI-пам’яті, зазначила, що MemPalace стверджує: у датасеті LoCoMo вона отримала 100%, що математично не могло статися, адже стандарти відповідей у цьому датасеті самі містять 99 помилок.
У своєму аналізі PenfieldLabs виявила, що 100% результат MemPalace походить із встановлення кількості запитів на пошук на 50 разів, але для тестових діалогів максимальна кількість етапів становить лише 32, що означає: система напряму обходить етап пошуку й передає всі дані AI-моделі для читання.
Щодо 100% результату в LongMemEval команду розробників викрили: виявилося, що вона націлилася на 3 конкретні проблеми, які зосереджені на розробці та дали збій, написала спеціальний код для виправлення, і це створює підозру, що під час тестування було здійснено шахрайство з тестовим набором.

Джерело зображення: Reddit Колега PenfieldLabs вказує, що MemPalace стверджує: у датасеті LoCoMo отримала ідеальний результат, але математично цього не могло статися
Практична перевірка на GitHub: базові тести мають елементи введення в оману
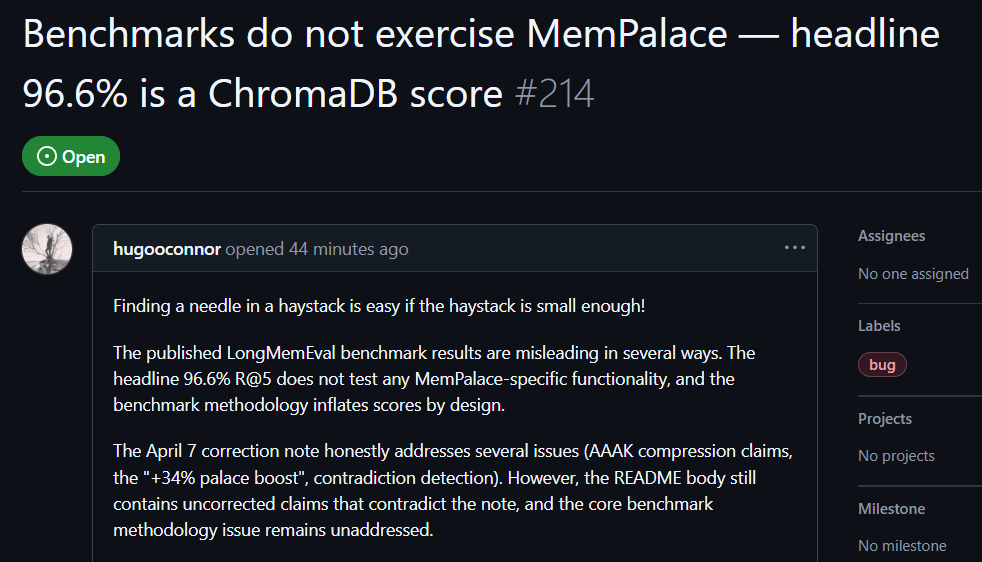
Користувач GitHub hugooconnor після практичної перевірки прокоментував: MemPalace заявляє аж 96.6% точності пошуку, але насправді повністю не використовує архітектуру «AI-палацу пам’яті», яку вона рекламувала. hugooconnor каже, що їхнє тестування лише викликає стандартні можливості базового сховища ChromaDB і зовсім не стосується логіки категоризації, яку підкреслює проєкт, як-от крилові зони, кімнати або шухляди.
Після тестування hugooconnor з’ясував: коли система реально вмикає ці власні логіки категоризації палацу пам’яті, результат пошуку навпаки погіршується. Наприклад, у режимі «кімната» точність знижується до 89.4%, а після ввімкнення технології стиснення AAAK точність ще падає до 84.2%; у обох випадках це нижче, ніж показує стандартна робота бази даних.
hugooconnor також розкритикував методологію тестування: середовище тестування MemPalace навмисно звужує діапазон пошуку для кожного питання приблизно до 50 діалогових етапів, тож у дуже маленькій колекції зразків знайти відповідь надто легко.
Якщо розширити діапазон до понад 19,000 діалогових етапів у реальних сценаріях, точність традиційного пошуку за ключовими словами падає до 30%, що вказує: нинішній формат тестування MemPalace маскує реальну складність пошуку.
Джерело зображення: GitHub Практична перевірка користувача GitHub: у базовому тестуванні MemPalace є елементи введення в оману
Водночас, хоча команда розробників уже опублікувала заяву про виправлення і визнала, що технологія AAAK справді підтверджується як така, що є зі втратами, та пообіцяла на основі суворої критики спільноти відкоригувати документи й дизайн системи, головний опис проєкту досі зберігає кілька непідкоригованих перебільшень, зокрема заяви про 30-кратне безвтратне стиснення та 34% підвищення точності пошуку, а також порівняльні графіки з іншими конкурентами взагалі не містять джерел.
Вихідний код MemPalace стикається з багатьма Bug
Зі збільшенням кількості завантажень тестувань на GitHub з’явилася велика кількість звітів про Bug у вихідному коді MemPalace.
Користувач cktang88 навів низку серйозних недоліків: зокрема, команди для стиснення не працюють і спричиняють падіння системи, у логіці підрахунку кількості слів для підсумків є помилки, статистичні дані щодо «викопування кімнат» є неточними, а також сервер під час кожного виклику завантажує в пам’ять усі інтерпретаційні дані, що створює критичні проблеми зі споживанням ресурсів.
Серед інших вказаних проблем також є те, що система примусово записує назви домашніх членів розробника в типовий конфігураційний файл, а під час перевірки статусу існує обмеження на примусове відображення 10,000 записів даних.
Для цих проблем відкрита спільнота вже почала активно виправляти. Користувач adv3nt3 надіслав кільказапитів навиправлення, включно з виправленням статистичних даних «викопування», видаленням типових назв членів родини та відтермінуванням ініціалізації часу для знаннєвої граф-схеми. Після цього команда розробників також визнала ці помилки та поступово виправляє проблеми з кодом у співпраці з спільнотою.
Мілла Йовович Vibe Coding — це круто, а спосіб просування — ні
Щодо цього проєкту MemPalace користувач Hacker News darkhanakh зробив висновок: MemPalace залишає відчуття на кшталт OpenClaw, тобто штучно маніпулюють результатами базових тестів (benchmark), щоб вони виглядали ідеально бездоганними, а потім упаковують це як якусь велику проривну подію для маркетингу.
Він вважає, що базова технологія MemPalace може бути справді цікавою, але за умов, коли методика тестування має такі недоліки, а ще й продається як «найвищий публічно доступний результат в історії», це виглядає явно недоречно, «але, знаєте, з тією справою, що Мілла Йовович грає в Vibe Coding, я, мабуть, усе ж думаю, що це доволі круто».
Додаткове читання:
AI написала код і наробила проблем! Проблема з безпекою в додатку «Прагни не марнувати їжу» (дата продукції в супермаркеті на смітник), GPS вдома повністю «випав» в ефір
Пов'язані статті
Міф Клода: Firefox виявив 271 вразливість, захисники мають шанси отримати вирішальну перевагу
Mozilla у вівторок оголосила, що рання версія AI-моделі Anthropic Claude Mythos в ході внутрішнього тестування виявила 271 вразливість у браузері Firefox, і всі ці вразливості були виправлені протягом цього тижня. Mozilla, висловлюючи здивування, також зазначила, що результати вказують на можливі докорінні зміни в сфері мережевої безпеки, і захисники, ймовірно, вже скоро скоротять перевагу, яку атакувальники мали протягом тривалого часу.
MarketWhisper2хв. тому
Попередження щодо IPO SpaceX: комерційна здійсненність бізнесу центрів обробки даних для космічного ШІ Ілона Маска під сумнівом
За повідомленням Reuters від 22 квітня, SpaceX у проєкті майбутнього S-1, який незабаром має бути подано, попередила потенційних інвесторів, зазначивши, що її плани з розробки космічних центрів даних на основі AI, а також місячної та міжпланетної індустріалізації «ще перебувають на ранній стадії, передбачають суттєву технічну складність і неперевірені технології, що може унеможливити комерційну реалізацію», що різко контрастує з оптимістичними поглядами, публічно висловленими цього року генеральним директором Ілоном Маском.
MarketWhisper32хв. тому
Claude Code скасовує виведення Pro-пакету, щоб його використовувати, потрібно оформити підписку Max! Керівники Anthropic заявляють, що це ще тестується
Нещодавно кілька користувачів помітили, що, ймовірно, на офіційному сайті Anthropic Claude Code з Pro (20 доларів/місяць) прибрали та замінили на Max (від 100 доларів/місяць) для використання. Офіційно заявили, що це лише тест для приблизно 2% нових реєстрацій prosumer, і наявні користувачі Pro та Max не постраждають. Цей крок розцінюють як повторну оцінку витрат і цінової стратегії для високовитратних функцій; у майбутньому, можливо, такі функції відокремлять від масових пропозицій і перейдуть до багаторівневого ціноутворення з вищими тарифами.
ChainNewsAbmedia1год тому
З’явилися ChatGPT Images 2.0! Точність генерації тексту значно зросла — легко створюйте маркетингові постери
OpenAI випустила ChatGPT Images 2.0: текст генерується точніше, плакати та портретні дизайни виглядають привабливіше, додано «режим мислення», який дозволяє миттєво шукати в інтернеті, виконувати пакетне виведення та здійснювати самоперевірку; за одним запитом можна отримати максимум вісім зображень, вони здатні зберігати сталість персонажа та стилю, роздільна здатність — до 2K, а співвідношення сторін можна обрати в діапазоні 3:1–1:3. Оптимізація для азійських мов є помітною, доступні API та платні комерційні плани, знання — до грудня 2025 року; для складних композицій усе одно потрібно кілька хвилин.
ChainNewsAbmedia1год тому
OpenAI зобов’язується інвестувати до $1.5B у нове спільне підприємство з приватним капіталом
Повідомлення Gate News, 22 квітня — OpenAI зобов’язалася інвестувати до $1.5 мільярда в нове спільне підприємство з приватною інвестиційною компанією, прагнучи конкурувати з Anthropic і завоювати зростаючий ринок інструментів корпоративного штучного інтелекту. Спочатку компанія інвестує $500 мільйона в капітал
GateNews1год тому
GPT-5.5 з’являється в селекторі OpenAI Codex, але повертає помилку 400; наразі недоступно
Повідомлення Gate News, 22 квітня — GPT-5.5 з’явився в розкривному списку вибору моделей для OpenAI Codex, розміщений у верхній частині списку.
Однак коли користувачі обирають GPT-5.5 і надсилають запит, Codex повертає помилку 400 з повідомленням "Модель 'gpt-5.5' не підтримується під час використання Codex із обліковим записом ChatGPT".
GateNews1год тому

