Anthropic傘下のAIプログラミングツールClaude Codeが深刻な評判危機に直面しています。AMDのAIディレクターがGitHub公式リポジトリで問題報告を公開し、数万件の会話ログに基づく定量分析の結果として、Claude Codeが今年2月以降にシステム的な能力低下を起こしていると非難しています。**思考の深さが67%も急落**し、モデルの挙動が全面的に崩れているとされています。この報告は開発者コミュニティで瞬く間に議論を呼び込み、Anthropicを世論の最前線へ押し上げました。この分析レポートを提出したのはAMDのAIチーム責任者Stella Laurenzoです。彼女はGitHub公式リポジトリに直接Issueを立て、厳しい言い回しでこう書きました:「**Claudeは複雑なエンジニアリング作業を実行するために信頼できません**」。彼女は「チームは他のサービス提供者に切り替え済みです」と述べ、さらにAnthropicに対して警告しました:「6か月前、Claudeは推論品質と実行能力で群を抜いていました。しかし今は、他の競合を非常に真剣に注視し、評価する必要があります。」このIssueはHacker Newsで急速に燃え広がり、975の支持票と548件のコメントを獲得し、直近のClaude Code関連の議論の中でも最も注目度の高い投稿の1つとなりました。ネットユーザーのコメントは問題の核心を直撃しています――「**ClaudeCodeは以前、賢いペアプログラミングの相棒のようだったのに、今はやり過ぎに熱心なインターンみたいで、事あるごとに物事を台無しにし、そして最も簡単な仮の策を勧めてくる感じ**」;「最近ずっと『寝た方がいいよ。もう遅いから、今日はここまでにしよう』みたいなことを言ってくる。最初は、うっかりClaudeに僕のdeadlineを教えちゃったのかと思ったよ。」Anthropicはこれに回答しました。Claude CodeチームのメンバーBorisが出てきて釈明し、思考内容の隠蔽機能(redact-thinking)はインターフェース層での改変にすぎず、「モデル内部の実際の推論ロジック自体には影響せず、思考予算や基盤となる推論の実行メカニズムにも影響しない」としています。彼は同時に、チームが2月に2つの実質的な調整を行ったことを認めました。**1つ目は、2月9日にOpus 4.6のリリースとともに導入された「適応的思考」(adaptive thinking)**;**2つ目は、3月3日にデフォルトのeffortレベルを高から中等(Medium)に下げたこと**です。Borisはユーザーに対し、/effort highの指示、または設定ファイルの変更により、高強度の思考モードを手動で復元するよう提案しました。しかし、**この説明はコミュニティの疑念を鎮められませんでした。**複数の開発者は、effortを最高にしても「『タスクを急いで片付ける』ための手抜き」のような挙動が依然として存在すると述べています。ユーザーrichardjenningsはこう語っています:> 「出力品質が崖のように落ちる前に、デフォルトのeffortがすでにMediumに変わっていたなんて全く知りませんでした。これらの問題を修正するために、だいたい丸一日かけて作業しました。」データで裏付け:思考の深さが急落し、挙動が全面的に崩れる------------------Laurenzoの分析は、彼女のチームが~/.claude/projects/ディレクトリ配下に蓄積した6852個のClaude Code会話JSONLファイルに基づいています。これらには、17871の思考ブロック、234760回のツール呼び出し、18000件余りのユーザー提示文が含まれ、期間は2026年1月末から4月初旬まで。全期間でAnthropic公式APIを介してOpusモデルに直結していました。**データは明確な退化のタイムラインを示しています。**1月30日から2月8日の「良好期」ではClaude Codeの思考の深さの中央値が約2200文字だったのに対し、2月下旬には約720文字まで暴落し、67%の下落です。3月初めにはさらに約560文字へ縮小し、75%の下落となりました。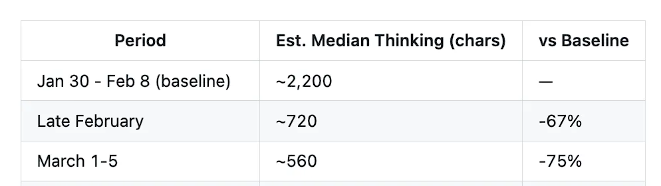**思考の深さの崩壊は、ツール利用パターンの根本的な転換を直接引き起こしました。**良好期には、Claude Codeがコードを修正する前の「読み・改変比」(編集のたびにファイルを読み込む回数)が最大6.6に達し、「まず調査してから修正する」という厳密なワークフローに従っていました。ところが3月8日以降の「退化期」では、この比率が2.0まで急低下し、調査に投じる時間が約70%減少しています。さらに目を覆いたくなるのは、退化期では3回のコード修正のうち1回が、対象ファイルを読み込まずに直接行われていることです。これにより、コードが誤った位置に挿入されたり、コメントの意味的な関連が壊れたりといった初歩的なミスが頻発するようになりました。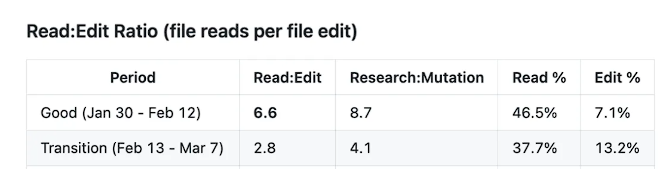**挙動レベルの定量指標も同様に衝撃的です。**「責任を先送りする」「早期に中断する」「許可を求める」といった不良行動を捉えるための終了フック用スクリプト(stop-phrase-guard.sh)は、3月8日以前には一度も発火していませんでした。一方でその後17日間で、**発火回数は173回まで急増し、平均で1日10回**。ユーザー提示文におけるネガティブな感情の割合は5.8%から9.8%へ上昇し、増加率は68%;ユーザー中断率(ユーザーがモデルの誤りに気づき、強制的に停止させる頻度)は、良好期から後半にかけて12倍に跳ね上がりました。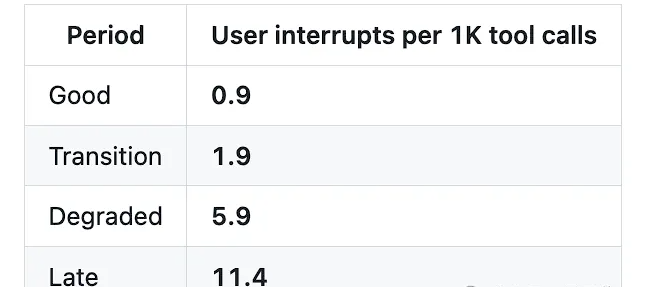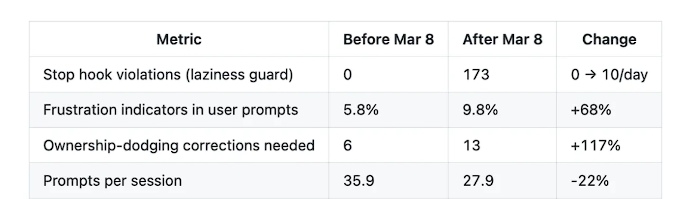隠された「思考内容の隠蔽」機能:退化を意図的に隠している?----------------------Laurenzoの分析によると、上記の退化は、redact-thinking-2026-02-12という名称の機能導入のタイムラインと非常に高い一致を示しています。データでは、この機能は3月5日から段階的に展開され(1.5%)、3月10日〜11日には99%以上のリクエストをカバーし、3月12日からは全量で有効になったことが示されています。この機能の役割は、APIレスポンスから思考内容を切り離し、ユーザーが外部からモデルの実際の推論プロセスを観察できないようにすることです。Laurenzoは、こうした設計が客観的に「思考の深さの退化をユーザーから見えなくする」ことにつながっていると考えています――「**3月初めにリリースされた隠蔽機能は、この退化をユーザーから見えなくしただけです。**」さらに彼女は、思考の深さの低下は実際には当該機能のリリースより早く、2月中旬にはすでに始まっていたと指摘しています。これは、Anthropicが2月9日にOpus 4.6をリリースし、さらに「適応的思考」(adaptive thinking)モードを導入したこと、ならびに3月3日にデフォルトの思考レベルを「Medium effort」(effort=85)に調整したタイミングと一致します。レポートはまた、**思考の深さが隠蔽機能のリリース後に、明確な時間帯の揺らぎを示す**ことも発見しました。太平洋時間17:00(米国西海岸の退勤時間帯)が1日の中で最悪の時間帯で、中位の推定思考深度が423文字にとどまります。19:00は2番目に悪い時間帯で、373文字です。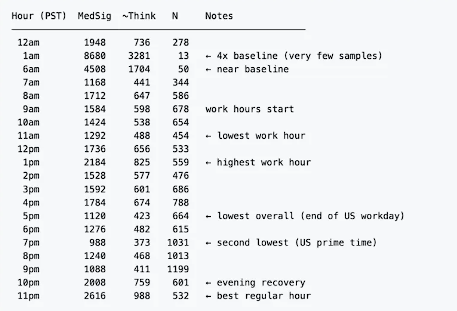このパターンは固定予算の配分とは一致せず、負荷に応じた動的配分システムの特徴により近く、思考リソースがプラットフォームの負荷に応じてリアルタイムに変動している可能性を示唆しています。Anthropic公式の回答:設定の問題であって、モデルの退化ではない------------------------GitHubの論点が急速に広がる中、Claude CodeチームのメンバーBorisは数時間以内にGitHubとHacker Newsの両方のプラットフォームで応答し、一部の問題の存在を認めつつ技術的な説明を提示しました。Borisの中核となる釈明には、以下が含まれます:> * 第1に、思考内容の隠蔽機能(redact-thinking)はUI層の改変であり、実際の推論プロセスには影響しません。ユーザーはsettings.json内のshowThinkingSummaries: trueオプションで表示を復元できます;> * 第2に、2月下旬の思考の深さの低下は主に、2月9日にOpus 4.6へ導入された適応的思考メカニズム(adaptive thinking)と、3月3日にデフォルトのeffortレベルを中等へ調整したことに関連します。前者はCLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1で無効化でき、後者は/effort highまたは/effort maxで手動により引き上げ可能です。> > Borisはさらに、チームとしてTeamsおよびEnterpriseユーザーのデフォルトeffortレベルを高へ調整するテストを行う計画があると述べています。また、特定のラウンドで適応的思考メカニズムが推論不足になっているという一部ユーザーの報告について調査中だとも言及しました。しかし、こうした説明はコミュニティ内で広範な疑念を呼び起こしました。ユーザーkoverstreetはこう返しました:> 「問題はデフォルトの思考レベルが中等になったことだけではありません。effortを最高にしても、『タスクを急いで完了させようとして片付ける』ような手抜き行動が明らかに増えています。」さらに別のユーザーは、投稿の時点ですでに既知の公開設定をすべて適用していた提出者がいたことを直接指摘し、問題は設定ミスによるものではないと述べています。あるユーザーは皮肉な問い返しをしました:> 「これは一体どんな発想なんでしょう――ユーザーに『設定を間違えました』と言うんですか?」コストの雪崩とユーザーの離脱---------退化がもたらした代償は品質低下だけでなく、コストの惨劇的な膨張も引き起こしました。Laurenzoのデータによると、2月から3月にかけてチームのユーザー提示文の数はほぼ横ばいでした(5608件 vs 5701件)一方で、APIリクエスト量は80倍に暴騰。総入力tokenは170倍、出力tokenは64倍に増加しました。Bedrock Opusの価格で月次コストを見積もると、345ドルから42121ドルへ跳ね上がり、122倍の上昇です。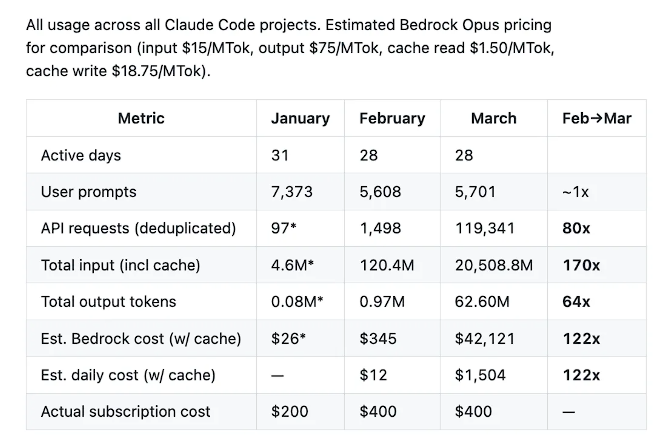Laurenzoは、コストの暴騰の一部はチームが積極的に並列Agent数を増員したことに起因すると説明していますが、退化そのものが無効なループを生み、頻繁な中断とリトライを誘発したため、結果として「1単位の有効作業あたりに消費されるAPIリクエスト数」が追加で8〜16倍に膨らんだとのことです。最終的にチームは、全Agentクラスターを停止せざるを得なくなり、単一会話での人手による監督モードへ戻しました。Laurenzoはこう書いています:> 「人間が投入する作業量はほぼ変わっていないのに、モデルは80倍のAPIリクエストと64倍の出力tokenを消費しているのに、出てくる結果は明らかにもっと悪くなっています。」Hacker Newsの議論では、多くのユーザーが同様の体験を語り、一部はすでにOpenAI Codexまたは他の代替案へ切り替えたと宣言しています。「サブスクリプションを解約してCodexに切り替えました」;「いまQwen3.5-27bを使ってる。2か月前のOpusほど鋭くはないけど、それでも普通に仕事を進められます。」ユーザーの自力救済:暫定的な対処案-----------退化に直面して、一部の開発者はさまざまな暫定的対処戦略を見出しています。最も一般的なのはCLAUDE.mdで明確な権限付与をする方法です。プロジェクトのルートディレクトリにある設定ファイルに「あなたにはこのプロジェクトのあらゆるファイルを編集する権限があります」「リファクタリングの際に確認を求めないでください」などの指示を書き込むことで、実務上、安全な中断の頻度を約70%下げられるとされています。複雑なタスクを、境界のはっきりしたサブタスクへ分解するのも、広く有効だと検証されています。「認証システム全体をリファクタリングする」ではなく、「auth.jsだけをリファクタリングし、完了したら変更の要約を出力する」といった境界が明確な指示の方が、モデルの早期停止行動を大幅に減らせます。設定の面では、effortをhighまたはmaxにし、さらにCLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1で適応的思考を無効化することが、現時点での公式に認められた最も直接的な介入手段です。一方で、Laurenzoはレポートの中でより体系的な要求を提案しています。Anthropicは、思考tokenの配分状況を公開し、複雑なエンジニアリング作業フロー向けの「満額思考」専用のサブスクリプション枠を用意し、APIレスポンスにthinking_tokensフィールドを露出させることで、ユーザーが推論の深さが要件を満たしているかどうかを自分で監視できるようにすべきだ、というものです。リスクに関する注意事項および免責条項 市場にはリスクがあります。投資は慎重に行ってください。この記事は個人の投資助言を構成するものではなく、特定のユーザーの特殊な投資目標、財務状況、または必要性も考慮していません。ユーザーは、この記事に含まれるいかなる意見、観点、または結論が、自身の特定の状況に適合しているかどうかを検討する必要があります。これに基づいて投資を行う場合、責任は利用者自身が負うものとします。
Claude Code 更新後「失敗」,思考深度急降67%、「再也無法信任其處理複雜工程任務」!
Anthropic傘下のAIプログラミングツールClaude Codeが深刻な評判危機に直面しています。AMDのAIディレクターがGitHub公式リポジトリで問題報告を公開し、数万件の会話ログに基づく定量分析の結果として、Claude Codeが今年2月以降にシステム的な能力低下を起こしていると非難しています。思考の深さが67%も急落し、モデルの挙動が全面的に崩れているとされています。この報告は開発者コミュニティで瞬く間に議論を呼び込み、Anthropicを世論の最前線へ押し上げました。
この分析レポートを提出したのはAMDのAIチーム責任者Stella Laurenzoです。彼女はGitHub公式リポジトリに直接Issueを立て、厳しい言い回しでこう書きました:「Claudeは複雑なエンジニアリング作業を実行するために信頼できません」。彼女は「チームは他のサービス提供者に切り替え済みです」と述べ、さらにAnthropicに対して警告しました:「6か月前、Claudeは推論品質と実行能力で群を抜いていました。しかし今は、他の競合を非常に真剣に注視し、評価する必要があります。」
このIssueはHacker Newsで急速に燃え広がり、975の支持票と548件のコメントを獲得し、直近のClaude Code関連の議論の中でも最も注目度の高い投稿の1つとなりました。ネットユーザーのコメントは問題の核心を直撃しています――「ClaudeCodeは以前、賢いペアプログラミングの相棒のようだったのに、今はやり過ぎに熱心なインターンみたいで、事あるごとに物事を台無しにし、そして最も簡単な仮の策を勧めてくる感じ」;「最近ずっと『寝た方がいいよ。もう遅いから、今日はここまでにしよう』みたいなことを言ってくる。最初は、うっかりClaudeに僕のdeadlineを教えちゃったのかと思ったよ。」
Anthropicはこれに回答しました。Claude CodeチームのメンバーBorisが出てきて釈明し、思考内容の隠蔽機能(redact-thinking)はインターフェース層での改変にすぎず、「モデル内部の実際の推論ロジック自体には影響せず、思考予算や基盤となる推論の実行メカニズムにも影響しない」としています。
彼は同時に、チームが2月に2つの実質的な調整を行ったことを認めました。1つ目は、2月9日にOpus 4.6のリリースとともに導入された「適応的思考」(adaptive thinking);2つ目は、3月3日にデフォルトのeffortレベルを高から中等(Medium)に下げたことです。Borisはユーザーに対し、/effort highの指示、または設定ファイルの変更により、高強度の思考モードを手動で復元するよう提案しました。
しかし、**この説明はコミュニティの疑念を鎮められませんでした。**複数の開発者は、effortを最高にしても「『タスクを急いで片付ける』ための手抜き」のような挙動が依然として存在すると述べています。ユーザーrichardjenningsはこう語っています:
データで裏付け:思考の深さが急落し、挙動が全面的に崩れる
Laurenzoの分析は、彼女のチームが~/.claude/projects/ディレクトリ配下に蓄積した6852個のClaude Code会話JSONLファイルに基づいています。これらには、17871の思考ブロック、234760回のツール呼び出し、18000件余りのユーザー提示文が含まれ、期間は2026年1月末から4月初旬まで。全期間でAnthropic公式APIを介してOpusモデルに直結していました。
**データは明確な退化のタイムラインを示しています。**1月30日から2月8日の「良好期」ではClaude Codeの思考の深さの中央値が約2200文字だったのに対し、2月下旬には約720文字まで暴落し、67%の下落です。3月初めにはさらに約560文字へ縮小し、75%の下落となりました。
**思考の深さの崩壊は、ツール利用パターンの根本的な転換を直接引き起こしました。**良好期には、Claude Codeがコードを修正する前の「読み・改変比」(編集のたびにファイルを読み込む回数)が最大6.6に達し、「まず調査してから修正する」という厳密なワークフローに従っていました。ところが3月8日以降の「退化期」では、この比率が2.0まで急低下し、調査に投じる時間が約70%減少しています。さらに目を覆いたくなるのは、退化期では3回のコード修正のうち1回が、対象ファイルを読み込まずに直接行われていることです。これにより、コードが誤った位置に挿入されたり、コメントの意味的な関連が壊れたりといった初歩的なミスが頻発するようになりました。
挙動レベルの定量指標も同様に衝撃的です。「責任を先送りする」「早期に中断する」「許可を求める」といった不良行動を捉えるための終了フック用スクリプト(stop-phrase-guard.sh)は、3月8日以前には一度も発火していませんでした。一方でその後17日間で、発火回数は173回まで急増し、平均で1日10回。ユーザー提示文におけるネガティブな感情の割合は5.8%から9.8%へ上昇し、増加率は68%;ユーザー中断率(ユーザーがモデルの誤りに気づき、強制的に停止させる頻度)は、良好期から後半にかけて12倍に跳ね上がりました。
隠された「思考内容の隠蔽」機能:退化を意図的に隠している?
Laurenzoの分析によると、上記の退化は、redact-thinking-2026-02-12という名称の機能導入のタイムラインと非常に高い一致を示しています。データでは、この機能は3月5日から段階的に展開され(1.5%)、3月10日〜11日には99%以上のリクエストをカバーし、3月12日からは全量で有効になったことが示されています。
この機能の役割は、APIレスポンスから思考内容を切り離し、ユーザーが外部からモデルの実際の推論プロセスを観察できないようにすることです。Laurenzoは、こうした設計が客観的に「思考の深さの退化をユーザーから見えなくする」ことにつながっていると考えています――「3月初めにリリースされた隠蔽機能は、この退化をユーザーから見えなくしただけです。」
さらに彼女は、思考の深さの低下は実際には当該機能のリリースより早く、2月中旬にはすでに始まっていたと指摘しています。これは、Anthropicが2月9日にOpus 4.6をリリースし、さらに「適応的思考」(adaptive thinking)モードを導入したこと、ならびに3月3日にデフォルトの思考レベルを「Medium effort」(effort=85)に調整したタイミングと一致します。
レポートはまた、思考の深さが隠蔽機能のリリース後に、明確な時間帯の揺らぎを示すことも発見しました。太平洋時間17:00(米国西海岸の退勤時間帯)が1日の中で最悪の時間帯で、中位の推定思考深度が423文字にとどまります。19:00は2番目に悪い時間帯で、373文字です。
このパターンは固定予算の配分とは一致せず、負荷に応じた動的配分システムの特徴により近く、思考リソースがプラットフォームの負荷に応じてリアルタイムに変動している可能性を示唆しています。
Anthropic公式の回答:設定の問題であって、モデルの退化ではない
GitHubの論点が急速に広がる中、Claude CodeチームのメンバーBorisは数時間以内にGitHubとHacker Newsの両方のプラットフォームで応答し、一部の問題の存在を認めつつ技術的な説明を提示しました。
Borisの中核となる釈明には、以下が含まれます:
Borisはさらに、チームとしてTeamsおよびEnterpriseユーザーのデフォルトeffortレベルを高へ調整するテストを行う計画があると述べています。また、特定のラウンドで適応的思考メカニズムが推論不足になっているという一部ユーザーの報告について調査中だとも言及しました。
しかし、こうした説明はコミュニティ内で広範な疑念を呼び起こしました。ユーザーkoverstreetはこう返しました:
さらに別のユーザーは、投稿の時点ですでに既知の公開設定をすべて適用していた提出者がいたことを直接指摘し、問題は設定ミスによるものではないと述べています。あるユーザーは皮肉な問い返しをしました:
コストの雪崩とユーザーの離脱
退化がもたらした代償は品質低下だけでなく、コストの惨劇的な膨張も引き起こしました。
Laurenzoのデータによると、2月から3月にかけてチームのユーザー提示文の数はほぼ横ばいでした(5608件 vs 5701件)一方で、APIリクエスト量は80倍に暴騰。総入力tokenは170倍、出力tokenは64倍に増加しました。Bedrock Opusの価格で月次コストを見積もると、345ドルから42121ドルへ跳ね上がり、122倍の上昇です。
Laurenzoは、コストの暴騰の一部はチームが積極的に並列Agent数を増員したことに起因すると説明していますが、退化そのものが無効なループを生み、頻繁な中断とリトライを誘発したため、結果として「1単位の有効作業あたりに消費されるAPIリクエスト数」が追加で8〜16倍に膨らんだとのことです。最終的にチームは、全Agentクラスターを停止せざるを得なくなり、単一会話での人手による監督モードへ戻しました。Laurenzoはこう書いています:
Hacker Newsの議論では、多くのユーザーが同様の体験を語り、一部はすでにOpenAI Codexまたは他の代替案へ切り替えたと宣言しています。「サブスクリプションを解約してCodexに切り替えました」;「いまQwen3.5-27bを使ってる。2か月前のOpusほど鋭くはないけど、それでも普通に仕事を進められます。」
ユーザーの自力救済:暫定的な対処案
退化に直面して、一部の開発者はさまざまな暫定的対処戦略を見出しています。
最も一般的なのはCLAUDE.mdで明確な権限付与をする方法です。プロジェクトのルートディレクトリにある設定ファイルに「あなたにはこのプロジェクトのあらゆるファイルを編集する権限があります」「リファクタリングの際に確認を求めないでください」などの指示を書き込むことで、実務上、安全な中断の頻度を約70%下げられるとされています。
複雑なタスクを、境界のはっきりしたサブタスクへ分解するのも、広く有効だと検証されています。「認証システム全体をリファクタリングする」ではなく、「auth.jsだけをリファクタリングし、完了したら変更の要約を出力する」といった境界が明確な指示の方が、モデルの早期停止行動を大幅に減らせます。
設定の面では、effortをhighまたはmaxにし、さらにCLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1で適応的思考を無効化することが、現時点での公式に認められた最も直接的な介入手段です。
一方で、Laurenzoはレポートの中でより体系的な要求を提案しています。Anthropicは、思考tokenの配分状況を公開し、複雑なエンジニアリング作業フロー向けの「満額思考」専用のサブスクリプション枠を用意し、APIレスポンスにthinking_tokensフィールドを露出させることで、ユーザーが推論の深さが要件を満たしているかどうかを自分で監視できるようにすべきだ、というものです。
リスクに関する注意事項および免責条項